Playlist from June 2025.
Some of my favorites:
- Claudia, Wilhelm R And Me by Roberto Musci
- Journey in Satchidananda by Alice Coltrane and Pharoah Sanders
- Little Sunflower by Dorothy Ashby
I haven't published much this past month. Notes and responses are significantly down from last year.
That said, I'm happy that so far I've published seven long-form blog posts, which is how many I published all of last year.
I haven't spent as much time bookmarking and resharing content. Partially due to the fact that I'm still working on the redesign. So far vibe-specing the redesign hasn't yielded good enough results. Maybe I need to break down my problem further. That experience on its own might make a good blog post.
Part of the challenge with the redesign is that I'm trying to find a balance between standardizing my front-matter YAML schemas so that I can simplify my code and just have a single function handle the parsing of the front-matter, while at the same time enabling custom rendering depending on the post type. I think in the end what I'll end up doing is having different schemas per post type and maybe refactoring some of my code to remove redundancies.
Better late than never. Here's the May 2025 drop.
Some of my favorites from last month:
- Prayer to the Stars by Vianney Lopez, Sam Bottner
- Diarabi by Viex Farka Toure, Khruangbin
- Everything & Nothing, OHMA
- Bloom, Deya Dova
- Dance of the Seven Sisters, Deya Dova
- Wisdom Eye by Alice Coltrane
- Black Meditation by Shabaka
Some pictures from the Thee Sacred Souls concert I attended a few weeks ago.
I caught them in New York when the tour started, so it was nice to catch them at the end of the tour as well.
In both cases, they were great performances.


I saw these really cool murals around the neighborhood. The artists signed their work either with their name or Instagram handle. I don't use Instagram, so it was nice to see that some of them also had websites where I could follow their work.
(see your rules and project plan)
Is that Copilot's way of saying, "Per my previous e-mail..."?
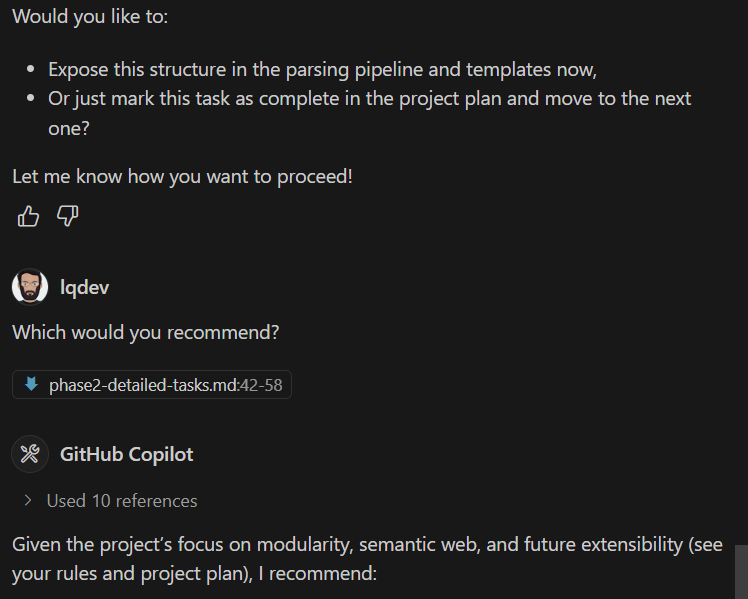
And then it rage quit.


Blogs
Notes
Responses
- The Evolution of Blogging
- ZeroSearch - Incentivize the Search Capability of LLMs without Searching
- Introducing AutoRound
- Discourse and the Fediverse
- socialweb.network
- TeLoGraF: Temporal Logic Planning via Graph-encoded Flow Matching
- Bukmark Club
- Parakeet TDT 0.6B V2 (En)
- CORG: Generating Answers from Complex, Interrelated Contexts
- Introducing Locate 3D
- In Praise of Links
- Announcing Distributed.Press Social Inbox 1.0
- Resisting the urge to rewrite the website
- Just Put It On Your Blog
- Fediverse House 2025 Roundup
- Self-Generated In-Context Examples Improve LLM Agents for Sequential Decision-Making Tasks
- Claude Artifacts
- A Survey of AI Agent Protocols

I find it amazing how you could've heard a song before but on rare occasions, you actually get to really listen to the song. That's been happening to me with this album from Chicano Batman. I've written before about how much I enjoy A Hundred Dead and Loving Souls. Lately though, I've been really into Itotiani, La Samoana, and Soniatl. The instrumentals are amazing. Wild to think this album is now 15 years old.
April 2025 drop.
SAULT, Cleo Sol (SAULT singer), and Little Simz were on repeat.
In the latest Ollama 0.6.5 release support was added for Mistral Small 3.1.
In an earlier post, I highlighted the announcement and summarized the key features.
I've been using it with GitHub Models and based on vibes I found it was more reliable at structured output compared to Gemma 3, especially when considering the model and context window size.
Now that it's on Ollama thought, I can use it offline as well. However, I'm not sure how well that'll work on my ARM64 device, which only has 16GB of RAM.
In a previous post, I talked about my workaround for running Element Desktop on my ARM64 Windows device.
I'm happy that I no longer need that workaround.
Element Desktop enabled support for ARM64 on Windows and shipped it as part of the 1.11.95 release.
While you could go to the downloads website and get the installer from there, you can now also get it via WinGet.
I built on the work of the existing community manifest in the winget-pkgs repo and via a pull request updated the latest 1.11.96 version to include the ARM64 installer.
While I didn't create the manifest from scratch, I thought it was really easy to contribute a new installer. I'll leave the details of my process for another post though.
Installing Element Desktop via WinGet is relativaly straightforward.
Assuming you already have the WinGet tool installed, all you have to do is run the following commmand in the terminal and you're all set!
winget install Element.Element -a arm64
February's drop.
I've been listening to a lot of Andre 3000 and stumbled upon Carlos Nino and Friends.
Blogs
Responses
- Claude 3.7 Sonnet and Claude Code
- The Algorithm - J. Cole has a blog?
- Introducing Mercury, the first commercial-scale diffusion large language model
- How to Multistream Using Azure, Azure VM, MonaServer 2, and FFmpeg with OBS Studio
- Nomic Embed Text V2: An Open Source, Multilingual, Mixture-of-Experts Embedding Model
- s1: Simple test-time scaling
- Unplatform
- Your Site Is a Home
It's rough out there.


Thanks to the kind e-mail from benji.dog, I realized people couldn't subscribe to my RSS feeds using the links provided in the /subscribe page.
I'd noticed something weird had been going on for the past few days but since the rest of my site was working, I didn't pay attention to it.
When I went in earlier today to fix the issue, I realized because of changes to Azure CDN, none of my redirects were working.
My site kept working fine, but that's because the migration was autmatically done by Azure.
What wasn't automatically migrated were my CDN rules which I'd set up to simplify URLs and own my links.
Off to a good start.
In the month of January, I wrote two long-form posts:
Last year, I published about seven of them.
As I tinker some more live on stream and use blog posts as a more structured way to orgqanize my explorations, I expect this year to have a healthy number of longer-form blog posts.
Notes and responses are not too far behind either. Both of them are at 14 in January. That's about 10% and 5% the number of posts in both of those categories last year. I haven't been reposting things I'm reading as often, but I'd like to start doing that some more.
Similar to long-form posts, as I reflect on each stream and publish the recordings, I expect at least one note every one or two weeks just for the stream.
No surprise, tags on my posts continue to be related to AI.
This month I didn't really do the monthly music playlist kind of posts. If I were to quickly summarize the music on repeat this month, it'd be the Andre 3000 album, New Blue Sun.
About a week ago, I was telling maho.dev about Owncast and my self-hosted setup.
During our chat, the question of simulcasting came up.
Using the guidance from the OBS community as a starting point, I decided to try it out for myself.
It didn't work as-is but after using an AI assistant to help me tweak the ffmpeg command, I was able to get it working.
I posted the command to my Wiki and plan on writing a more detailed post at a later time.
I saw that the DeepSeek R1 model is now on GitHub Models and Azure AI Foundry, so I decided to start a stream and play around with it in the GitHub Models playground as well as a .NET application.
Here's the recording.

I rambled on stream since it's my stream of consciousness as I'm tinkering with these technologies.
If you're mainly interested in the code, here's the GitHub repo: lqdev/DeepSeekDotnetSample
Mama says that alligators are ornery because they got all them teeth and no toothbrush.

Earlier today I tested out my self-hosted Owncast setup.

Overall, I think it went well considering I was using the built-in camera and mic on my laptop. Despite sharing my screen, using the browser, broadcasting and recording the stream, the laptop seemed to handle it just fine. I didn't get a chance to test writing and running code which is going to make up a bulk of the content on stream.
The flow on OBS is straightforward and simple. I might automate it either using my Stream Deck or just mapping hotkeys. It's simple enough that I only need to transition between a few scenes.
As far as hosting the recordings, the process of uploading to YouTube was straightforward. It took a little over 10 minutes, but that's something that I can just do in the background so not really worried about that. For the time being, I think I'll just use YouTube to host the videos and mark them as unlisted. No particular reason behind that other than I only want YouTube to serve as my video host. The main place I plan on showcasing and organizing videos is on my website.
For the time being, I'll just create notes like these. Eventually though, I'd like to have a video post type which shows up on my feed. The post card will only display the video but the detailed view, I'd like for it to be like my presentation pages. Except, instead of a presentation, it'd contain the video, show notes, maybe the transcript, and links mentioned during the stream. Also, I'd like video posts to have their own RSS feed just like other posts on this page so folks who are interested in following along can via their RSS reader.
A few other things I want to figure out are:
- Setting up a custom domain that points to my Owncast server rather than the default one provided by Azure Container Apps.
- Displaying and managing chat outside of the built-in Owncast frontend.
Notes
- Week of January 12, 2025 - Post Summary
- Embedded Owncast live stream into my website
- How do you watch Blu-Ray on PC?
- Why does Spotify need my full address?
Responses
- AI Subtitles Are Coming to VLC
- The Future of Calm Technology with Amber Case
- Stop renting space for your notes and start being your own landlord
- Making space for a handmade web
- R.I.P David Lynch
- Swarm navigation of cyborg-insects in unknown obstructed soft terrain
The live stream page on my site is up.
If you go to /live, you'll see the stream.
Still not sure what stream schedule will look like, but I'm thinking maybe I'll do a test one on Monday.
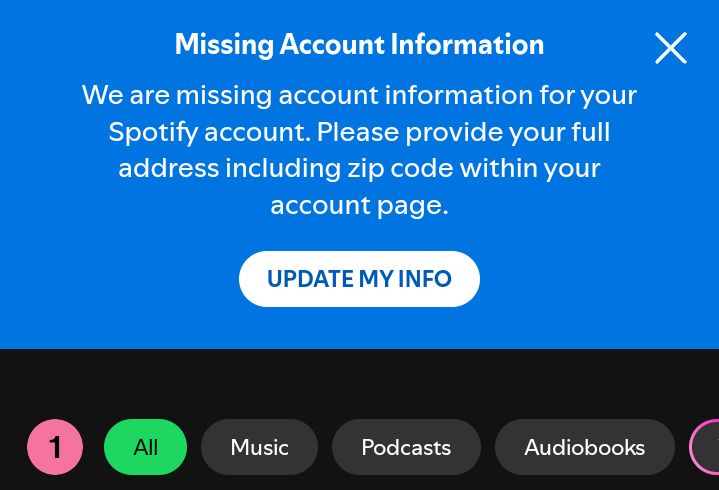
Why?
I have a preference for physical media. There's many reasons, some related to the sentiment of owning vs. renting content. Along the same lines, streaming services and service providers can change the terms of service and you have little to no control over it. Westworld is an example of that. One day, HBO decided to pull it from its streaming service and physical copies were the only way you could watch it.
Anyway, on to my most recent experience trying to play a Blu-Ray disc on my PC.
The other day I decided to sit down to watch an episode of Westworld. Usually, I get the DVD version. In this case though, I had the Blu-Ray.
I have an external Blu-Ray player so I thought, "Great! Let me just plug that into my laptop and start the show".
Wrong!
What I thought was a simple task, ended up taking me about 20 minutes to figure out and even then I got to a subpar solution.
I prefer playing media either with MPV or VLC.
At first, it wouldn't play so I decided to go online and figure out why. Turns out, that's not supported out of the box and to get it working you need to download an additional DLL and configure a few things in the VLC settings.
I could've gone through that process, but I just wanted to watch a show. There's got to be an easier way.
Next, I turned to the built-in Media Player in Windows. No luck there either.
I ended up going with the Leawo Blu-Ray player. Although it's free, you have to deal with pop-ups prompting you to upgrade to the paid version. It works though.
I would prefer to use VLC or the built-in media player but it's unfortunate using them isn't as straightforward. Now that I have some more time, I'll set up VLC so that next time, it can "just work".
I'll close it out with a question.
How do you watch Blu-Rays on your PC?
Send me a message and let me know.
Publishing on my site was broken since yesterday. I thought it was only me but after doing some digging looks like it was an issue with Azure CLI and the link it uses to download azcopy.
Looks like the team is already working on a fix and you can track progress using this issue
https://github.com/Azure/azure-cli/issues/30635
If you're using Azure CLI in GitHub Actions and running into this problem, you can unblock yourself by installing azcopy manually. Here's the snippet that worked for me.
- name: Upload to blob storage
uses: azure/CLI@v1
with:
azcliversion: 2.67.0
# azcopy workadound https://github.com/Azure/azure-cli/issues/30635
inlineScript: |
tdnf install -y azcopy;
# YOUR SCRIPT
I'm so glad I didn't bother tuning in. That ending was rough.
Last night I attended my first IndieWeb Homebrew Website Club meeting. Although it was my first, everyone was very welcoming and it felt like I'd been a longtime participant. It was also great to put faces to the many websites I already follow as well as discover new people in the community. Looking forward to the next one.
A few months ago, I started tinkering with Owncast. In that case, I was figuring out how I could use .NET Aspire and Blazor to configure an Owncast server and embed the stream on a website.
Although I didn't go all the way through creating the deployment, doing so with Aspire would've been fairly straightforward.
Since I already have a website, all I care about deploying is the Owncast server.
After spending about an hour on it today, I was able deploy and Owncast server to Azure Container Apps using the virtual network environment setup tutorial.
The hardest part was figuring out that I needed to set up a virtual network in order to publicly expose multiple ports.
Once the server was up and running, configuring OBS was relatively easy as well.
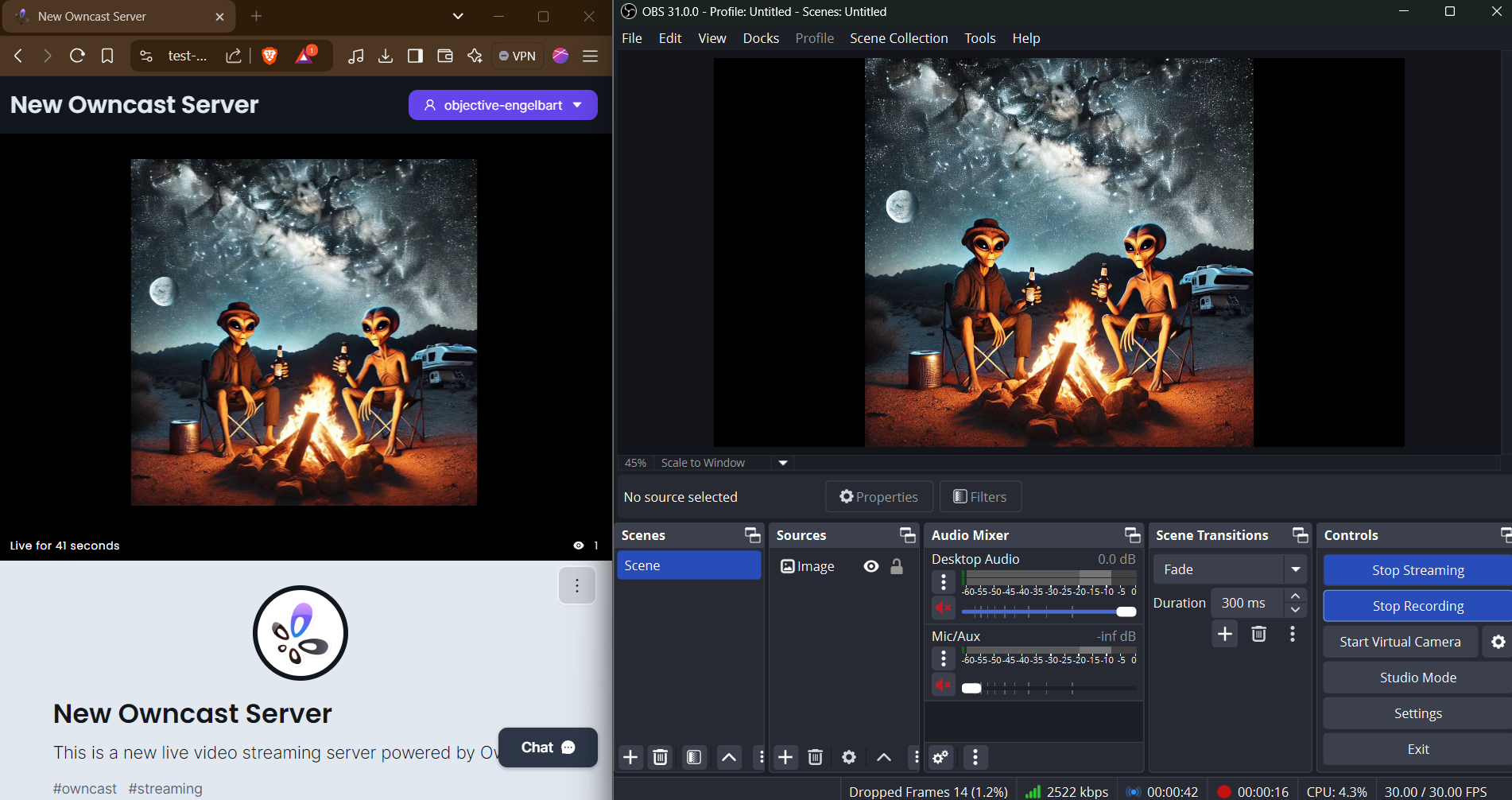
I'll try to put together a more detailed writeup so I remember what I did for next time as well as help others who may be interested in self-hosting their own livestream server.
Blogs
Notes
Responses

I'm trying.
That's a lot of podcasts!
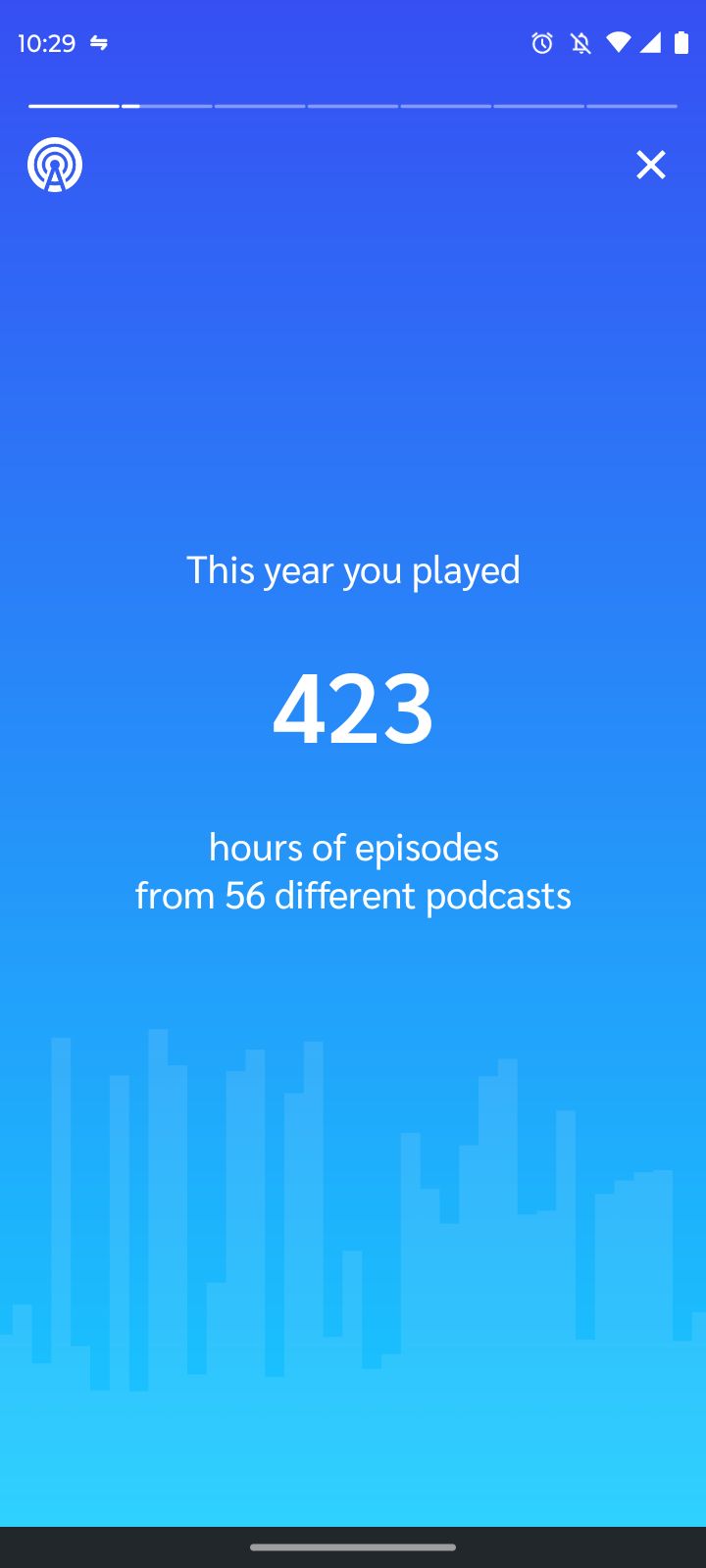
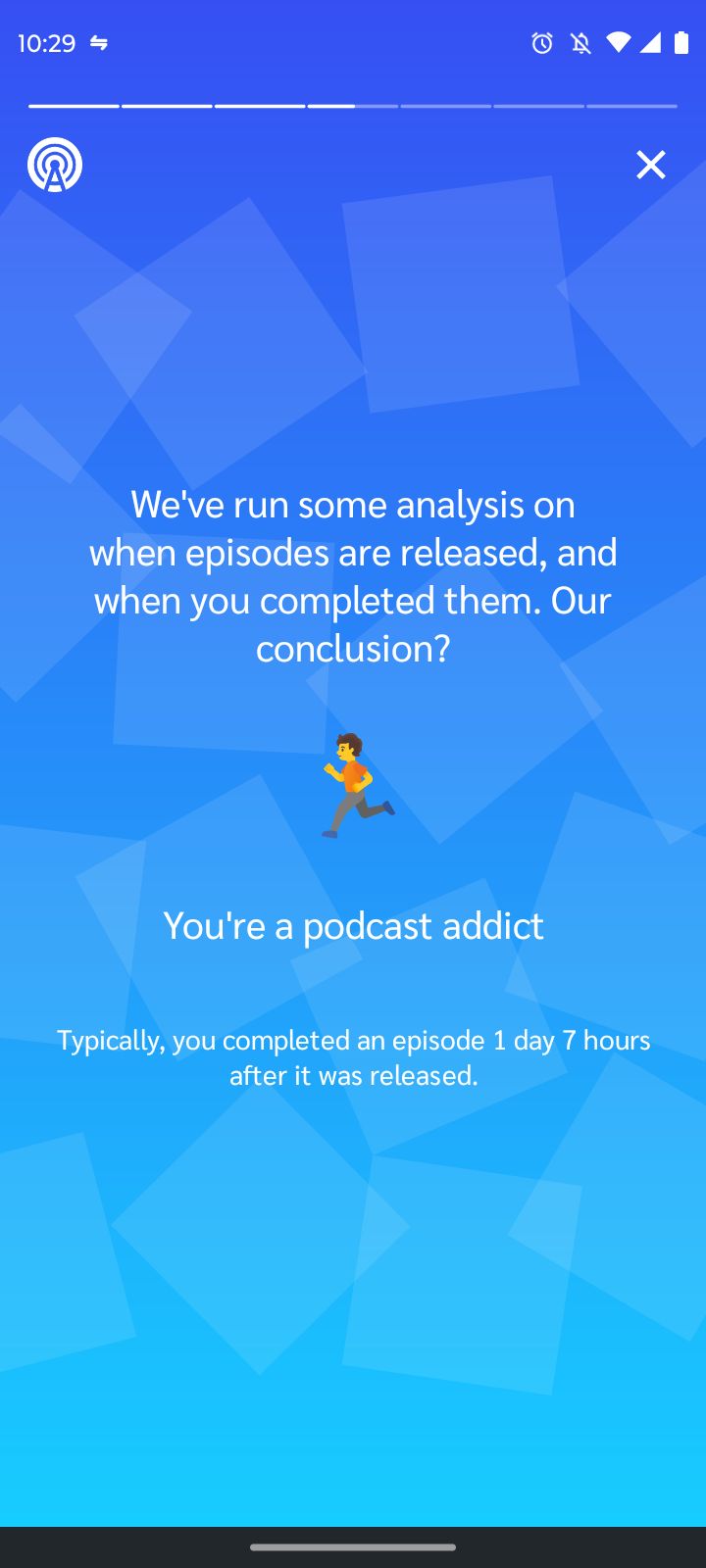
While looking at Spotify Wrapped this year, I completely missed the AI-generated podcast that came along with it.
As cool as this is, it should've been opt-in.
Although I would hope that when I clicked "I Agree" on the user agreement, the use of my data in this way is covered (for Spotify's sake), it's not clear or easy to find:
- What data was shared with Google's NotebookLM
- What Google will do with that data
There's a reason I purposefully haven't linked Spotify to other accounts.
I know there's probably hundreds of worse ways my data is being used I don't know about. This one though was hard to miss and a sad reminder that often you don't learn about how your data is being used until after the fact. Cases like this are not really a big deal. So what if you know I was going through a "Witchy Jam Band Phsychedelic Rock" phase in September? Where it does matter though is when it involves more personal and sensitive data. Again, because we don't realize it until after the fact, it's not until then that we learn what we're giving up when we make the simple, often uninformed, decision to select "I Agree".
It's finally here!
I can't say I'm too surprised by the results.

Compared to last year, I nearly doubled my listening minutes. Also, none of the artists from the previous year made it onto this list. Although, I'm not sure how Buffalo Springfield worked its way into the list of top artists.
I love how my listening habits from September are described, "Witchy Jam Band Psychedelic Rock".

So you might've heard of Windows Subsystem for Linux (WSL), but did you know you can also run Linux GUI apps with WSLg?
While trying to install the Element Desktop client on my Spandragon X Elite Windows device, I quickly realized you can't because of an issue with Electron.
WSL is supported on ARM64 Windows devices. This means, it should also support GUI apps.
I decided to try and install the Element Desktop client for Linux in WSL and this was the result!
For a while, I've known that I can use my domain and the WebFinger protocol to aid with discovery in the Fediverse, specifically Mastodon.
I tried implementing this feature on my website a while back but was unsuccessful.
Last night, I got an itch to try it again and got it working.
Basically, what I was doing wrong the first time was, I was trying to use lqdev.me as the domain. Currently, my domain is not set up to use apex / naked domains. Therefore, it makes sense why that didn't work.
Once I used www.lqdev.me, everything seemed to be working fine. The implementation isn't perfect, because technically you can use any username. Scott Hanselman does a nice job explaining that. The important part though is that my persence on the Fediverse is now directly linked to my domain, just like it is with Bluesky. This goes beyond the link verification Mastodon provides. As a result, it provides more flexibility and opportunities to shape my presence on the Fediverse.
If you're interested in implementing it for yourself, there's a ton of guides, but here's the one I used: Use your own user @ domain for Mastodon discoverability.
I don't like the www subdomain. So far I've put up with it for a while but this might be the forcing function to finally getting the apex domain setup.
In the meantime, you can search my account in Mastodon using @lqdev@www.lqdev.me.
In version 4.3, Mastodon introduced OpenGraph creator tags to link to an author's Fediverse account from within a post.
I had implemented it on my website a while back. However, because my instance wasn't using a version that supported it, it didn't show up on my instance.
Since upgrading to 4.3.1, I can now see my posts making use of the creator tag feature.
As you can see from the original post, implementing it was relatively trivial. Another win for open protocols and standards.
After about a month of not being able to access my Mastodon instance, I'm so excited to have it working again!
Not sure what I did wrong with my upgrade to 4.3.0. Fortunately, the issues appears to have been on the frontend and the fix wasn't too involved.
Upgrading to the latest 4.3.1 fixed the issue I ran into during my last upgrade.
Thanks to my POSSE setup, I've been able to continue posting to my website and syndicating to Mastodon. Unfortunately, since the frontend wasn't working, I was unable to access my notifications. Because the mobile apps make use of the web frontend to log in, I couldn't use the mobile app either.
Amazing that Tyson at his age just did that. He earned that paycheck. That said, it was tough to watch and fortunately it didn't seem like he got hurt too bad. It looked like Jake was pulling his punches because that fight could've ended in the 2nd / 3rd round. Overall, it's the best outcome possible. Jake can say he "beat" Mike Tyson, Tyson didn't get knocked out or hurt too bad, and they both earned a decent paycheck.
Obligatory upgrade post. Just upgraded the website to .NET 9. As with all the previous years, it involved no code changes, and all I had to do was updade the version I'm using in my project file and GitHub Actions file.
It's that time of the year again. A new .NET release.
Tons of great sessions at .NET Conf this year, which you can see in the agenda.
I'll be taking part in two sessions:
- Building AI Applications from Scratch: A Hands-On Guide for .NET Developers
- Building the Foundation: AI Fundamentals in .NET
Started experimenting some more with posting photos this week.
Notes
- Week of November 3, 2024 - Post Summary
- NYC Sunrise
- .NET Conf 2024 Bound
- Finally starting to feel like fall
Responses
- Microsoft Research Focus: Week of October 28, 2024
- Thinking LLMs: General Instruction Following with Thought Generation
- Microsoft Research: Introducing DRIFT Search
- In-Context LoRA for Diffusion Transformers
- Leo.fm move to micro.blog
I was lucky to snap this picture the other day.

Fairly active week on the website.
Blogs
Notes
- Website Post Statistics - October 2024
- Crate Finds - October 2024
- Finally starting to feel like fall
- Only 365 more days until next halloween
- St. Chroma is a great intro
Responses
- New Release: Spirit Box by Flying Lotus
- Chromakopia by Tyler The Creator Released
- NotebookLlama: An Open Source version of NotebookLM
- Haves and Choices
- Art the Clown Will Ring the Nasdaq Closing Bell in Times Square on Halloween!
It's been unseasonably warm around these parts but this weekend it finally started to cool down. That meant hot cider and cider donuts straight from the source.

I love the album overall but St. Chroma is a great intro that sets up the rest of the album.
Some of my favorite parts from the track
You are the light. It's not on you, it's in you. Don't you ever in your motherfucking life dim your light for nobody.
P said I could do it too, and boy, did I believe him. I built a path to freedom 'cause them words that he said. Give a fuck about tradition, stop impressin' the dead
Don't you ever stop bein' who you are and dimmin' your light for none of these motherfuckers out here

Lots of music released this month
Both amazing albums I've now listed to multiple times from beginning to end.
That said, the Crate Finds this month are light and can best be summarized as my favorite songs from Got A Story to Tell by Thee Sacred Souls.
It's been a while since I've done one of these.
One thing I'm changing is the titles. For the other posts, the titles don't match up with the date for the metrics. For example the post for "July 2024" was actually talking about June metrics. Kind of confusing, so fixing that this month.
This is my post
| Post Type | Count |
|---|---|
| Blogs | 4 |
| Notes | 83 |
| Responses | 251 |
Overall the trend is nice. I'm just under 1 response a day. Not like that's the goal, but in general I think it shows a steady stream of content I'm posting on the website.
With two recent blog posts published, that brings me to 5. The script ran just before I hit publish on the last blog which is why you only see four.
- Build your own self-hosted live streaming application with Owncast and .NET Aspire
- Digitize Analog Bookmarks using AI, .NET, and GitHub Models
There's a few other ideas I'm tinkering with, which might easily get me close to or past the 8 blog posts from last year.
That's a wrap for spooky season. It was unseasonably warm so it hasn't really felt like fall.

Wow! This game delivered. I haven't watched any games this season and I couldn't have picked a better one to tune into.
It was an ugly game for Penn State and they got lucky on some calls but they found a way to get it done on the road.
New drop from FlyLo. This feels like a new album coming. So far the theme is mystical.
The previous single, Garmonbozia, was a reference to Twin Peaks.
Ingo Swann's website describes him as
...a pioneer of parapsychology and remote viewing, who worked with CIA and NASA, wrote books, and created art.
The website invites visitors to,
explore his research on NHEs, UFOs, UAPs, and the planets.
Similarly, Wikipedia describes him as
an American psychic, artist, and author, whose claims of clairvoyance were investigated as a part of the Central Intelligence Agency’s Stargate Project. Swann is credited as the creator of the term “Remote Viewing," a term which refers to the use of extrasensory perception to perceive distant persons, places, or events.
I'm excited to discovery the mystery behind this new project from FlyLo.
New release from Thee Sacred Souls. I really enjoyed the beginning and the end.
My favorite songs are:
- Lucid Girl
- Price I'll Pay
- Live for You
- On My Mind
- Waiting on the Right Time
- I'm So Glad I Found You, Baby
This month had a mix of genres. Some of the ones I kept coming back to:
- Wharf Rat by Grateful Dead
- Deal by Grateful Dead
- God is Love by Marvin Gaye
- Save the Children by Marvin Gaye
I listened to the album What's Going On a few times throughout the month.
The most significant update from last month is that I have now passed the number of responses compared to last year.
The top tag continues to be AI and The Verge is the top domain I link to.
I'm in the process of redesigning the website, so that's probably one of the things I'll be focusing the next few months.
A little late with this post, but here's what I was listening to in August.
Some songs that were on repeat:
- Dark Star by Grateful Dead
- Ripple by Grateful Dead
- Garmonbozia by Flying Lotus
- Pretty Girl Why by Buffalo Springfield
- Sit with the Guru by Strawberry Alarm Clock
Excerpts from the Omega Mart Leadership Ascension Track (LAT)
Meeting the self
- Make a human pyramid with your high school guidance counselor and middle school crush.
Renouncing the body
- Contribute 14% of your net worth to Drampcorp.
- Be nice to 77 dogs.
Understanding nature
- Learn to suck venom out of a snake bite.
- Befriend a snake.
- Interview a rock and ghost write its memoir.
- Spend a week in the desert, living off the land.
Harmonizing with the essence
- Buy two cakes. Decorate and dedicate one of the cakes to the other. Stack the cakes. Leave them both on a neighbor's doorstep in a ding-dong-ditch scenario.
- Swim to a whirlpool and dance within its rotating waves (hint: go with the flow).
Moving beyond
- Approach a stranger in a coffee shop, have them show you their laptop search history, find the second-most recent country they've searched and move there for 7 months.
Come to peace with the infinite
- Use an infinity mirror to get ready for a night on the town.
Manifesting the self
- Take a childhood photo to the top of a mountain. Bury the photo and create a new peak.
- One day a week, wake at dawn and meditate until sundown.

I got my hands on an Ivy Cliq+ 2 earlier today and am really liking it.
It's really cool that it's both a point-and-shoot camera as well as a photo printer. The camera comes in handy if you want to capture something in the moment and print it out immediately. The printer is great for pictures you've taken on your phone or some other device. Even better, you can create collages, apply filters, and do all sorts of adjustments to images before printing.
If there's one thing I didn't like is that in order to set it up, it needed access to my exact location. Trying approximate location wasn't enough. It connects over Bluetooth, so you'd think that should be enough to pair. Not sure what it needs my EXACT location for.
I'm oficially old. I had to look up what Kick is.
In case you also didn't know, I'll save you some time.
Kick is a platform where you can watch and interact with live streamers from various categories, such as games, music, gambling and creative.
While thiking about implementing .well-known for RSS feeds on my site, I had another idea. Since that uses OPML anyways, I remembered recently doing something similar for my blogroll.
The concept is the same, except instead of making my blogroll discoverable, I'm doing it for my feeds. At the end of the day, a blogroll is a collection of feeds, so it should just work for my own feeds.
The implementation ended up being:
Create an OPML file for each of the feeds on by website.
<opml version="2.0"> <head> <title>Luis Quintanilla Feeds</title> <ownerId>https://www.luisquintanilla.me</ownerId> </head> <body> <outline title="Blog" text="Blog" type="rss" htmlUrl="https://www.lqdev.me/posts/1" xmlUrl="https://www.lqdev.me/blog.rss" /> <outline title="Microblog" text="Microblog" type="rss" htmlUrl="https://www.lqdev.me/feed" xmlUrl="https://www.lqdev.me/microblog.rss" /> <outline title="Responses" text="Responses" type="rss" htmlUrl="https://www.lqdev.me/feed/responses" xmlUrl="https://www.lqdev.me/responses.rss" /> <outline title="Mastodon" text="Mastodon" type="rss" htmlUrl="https://www.lqdev.me/mastodon" xmlUrl="https://www.lqdev.me/mastodon.rss" /> <outline title="Bluesky" text="Bluesky" type="rss" htmlUrl="https://www.lqdev.me/bluesky" xmlUrl="https://www.lqdev.me/bluesky.rss" /> <outline title="YouTube" text="YouTube" type="rss" htmlUrl="https://www.lqdev.me/youtube" xmlUrl="https://www.lqdev.me/bluesky.rss" /> </body> </opml>Add a
linktag to theheadelement of my website.<link rel="feeds" type="text/xml" title="Luis Quintanilla's Feeds" href="/feed/index.opml">
Grateful Dead on repeat this month. Songs I kept coming back to:
- Standing on the Moon
- Eyes of the World
- Fire on the Mountain
A few Doors songs also got in there I hadn't listened to before like Blue Sunday.
Finished July with more regular posting.
Only 4 posts away from passing last year's response count.
As mentioned on another post, I've been slowly working on transitioning authoring workflows to Emacs using org-capture templates.
This month, I want to work on making capturing content from Nyxt more seamless, especially since responses are the types of posts I use most.
The other thing I'd like to start doing is consolidating the structure of my posts. Right now the YAML front-matter for the various posts types is significantly different. However, it doesn't have to be.
For most posts, I need:
- Title
- Date published
- Data updated
- Tags
Responses are a little different because I also need to include the link to the original content I'm referencing in the post.
Once that's done, at some point, I'd also like to consolidate my URLs.
/postscaptures long-form blog posts/feedcaptures microblog posts and responses
Since everything is a post, consolidating under one of them for all my posts and providing additional urls like /notes, /photos, /articles for the individual types of posts might make more sense.
I recently took inventory of subscriptions I'm no longer using. The ones that were especially tricky to spot were the annual subscriptions that don't show up on bank statements every month. These also happened to be ones that I hadn't used in years.
Getting a list of them was the easy part. The fun didn't start until I actually went through the process of unsubscribing.
For a few of them, cancelling was relatively straightforward.
Others, it was an adventure. Best case, I was presented with several screens where the option to keep my subscription was front and center and the cancel button was in small print all the way at the bottom of the screen. In other cases, I had to send an e-mail to cancel. My favorite though was the one where I was able to log in and access member content. When I went to the account settings to try and cancel my subscription, they were conveniently having technical difficulties 🙃
Super frustrating experience all around, but happy to get it done so I get to keep more of my money.
I finally got my website note org-capture template working for new files.
Originally, I only had it working on existing files using this snippet.
("wne"
"Creates a note in an existing file"
plain
(file buffer-file-name)
(file ,(file-name-concat website-template-dir "note.txt")))
This template uses the file name of the current buffer to select the insertion target.
Getting it to work with a new file specified by the user, requires a small tweak.
("wnn"
"Creates a note in a new file"
plain
(file (lambda () (file-name-concat website-note-dir (format "%s.md" (read-string "Enter file name: ")))))
(file ,(file-name-concat website-template-dir "note.txt")))
At first, I thought I had to use the function target type since I wanted to use a function to capture the file name. That didn't work.
I then realized, I could still keep the file target type. However, to fill in the file name, I could use a function which takes in user input.
Now that I got this working, I've also done the same for my reponse template.
I still need to set up an org-capture template for snippets, so writing a note to myself to remember these commands I'll eventually want to come back to.
Capture elfeed link
In this custom function, elfeed-show-yank extracts the link element in an elfeed entry. org-capture then just invokes the org-capture template selection prompt. At this point, I can move forward with creating a response entry on the website and since the link to the entry I was viewing in elfeed is in the kill-ring, I can easily paste the URL while filling out the org-capture template.
(defun capture-elfeed-entry ()
(elfeed-show-yank)
(org-capture))
Org capture contexts
I recently found out, I can add filters to org-capture templates based on the mode I'm in Emacs. Here's an example:
(setq org-capture-templates-contexts
'(("wrn" ((in-mode . "elfeed-show-mode")))))
org-capture-templates-contexts defines a set of conditions that defines which contexts certain org-capture templates appear under.
For example, the org-capture template mapped to wrn will only be visible when org-capture is invoked from a buffer in elfeed-show-mode.
More information can be found in the org-capture templates in context documentation
A few new songs. Besides listening to them a few times though, there aren't many I came back to throughout the month.
I'm excited for the new album from Thee Sacred Souls though.
Better late than never.
Nothing too interesting this month. I haven't been posting as much.
I think part of that is because I've been creating DayOne posts more.
I've been relying on DayOne to share articles from my RSS reader. That's worked really well for bookmarking.
As far as my authoring process, when working locally, I've been using Emacs more.
One reason for Emacs is capture templates.
Technically, I already have something similar with VS Code Snippets.
I like the richness of the Emacs experience more though.
The future workflow I'm thinking of involves two components:
- Elfeed
- Nyxt
When reading articles using Elfeed, I can create a function that takes the information from the entry I'm on and converts it into an entry on my site using capture templates.
Similarly, in Nyxt while browsing the internet, I can create a similar function which uses capture templates to create website entries.
Maybe I can get a long-form post out of that experiment.
As far as numbers go, I'm at 56 notes for the year which is 15 more than last year.
I'm closing in on passing last year's response count at 210.
Most of the content shared continues to be mainly about AI.
Top linked domain is still The Verge.
Testing an org-capture template generated note for the website.
Org-mode appreciation post.
I use plain text and org-mode for most things in my life, especially when it comes to task and life management.
I won't rehash all the reasons Emacs and org-mode are amazing. There are tons of blog posts and videos out there that would do it more justice than I ever could.
Over the last few years, Emacs has become my go-to text editor. Throughout all that time, I've continued to find new features that delight.
The most recent is clock table.
I already use org-mode to track my to-dos and perform some sort of time-block planning by setting deadlines and scheduling tasks.
Recently though, I've been wanting a way to see all of the things I've worked on over the past [ INSERT TIME PERIOD ]. More importantly, I'd like to have time associated with them to see where my time has gone and evaluate whether I'm spending time on the things I should be.
I knew you could clock in and clock out on tasks. However, I didn't know you could easily build a customized report that automatically updates. That's when I came across clock tables.
Now, I have a way of visualizing all of the things I worked on during a week or month, and as I'm planning for the next week or month, I can adjust and reprioritize the things I'm working on.
I know there are enterprise offerings like the Viva suite from Microsoft which provides detailed reports on how you spend your time.
What excites me about org-mode though is that it's plain text. The clock table report that gets generated is a plain text table which makes it portable and easy to access using any text editor of your choice. It works best with Emacs, but that's not a requirement.
On their own, clock tables are amazing.
However, given how well language models work on plain text, they could be used as context for your queries. Imagine giving a language model as input an org file which contains:
- A clock table
- A list of TODO tasks (with notes, priorities, deadlines, tags, properties, and other annotations)
- A high level list of goals you want to achieve
Then, you could enter a prompt along the lines of: "Using the following clock-table and list of goals I want to achieve, provide me with recommendations of tasks I should work on for the next week. Ensure that they align with my goals, are top priority, and provide the highest return on my efforts".
Additionally, you might also provide your org-agenda view containing appointments and use the results from the first query as context for the following prompt: "Given the agenda view for the next week, schedule the top 3 tasks you recommended".
The result would be a list of TODO items containing schedule / active timestamps annotations which now show up on your org-agenda view.
Today, almost every productivity application out there is working on building these kinds of AI features into their products. The difference is, in many cases, the formats used by those applications aren't plain text. This adds complexity to the data extraction and transformation pipelines required to get the data into the right format for a language model to process. With plain text, there's little to no transformations required.
What's even better, I can extend org-mode and Emacs using elisp to do the things I just talked about.
I'm no elisp expert, so I asked Copilot to generate an elisp function that takes an org-mode clock table as input and generates a written text summary of it. Here are the results:
(defun org-clock-summary-to-chatgpt ()
"Extracts clock table data and requests a summary from ChatGPT."
(interactive)
(let* ((clock-table-data (org-clocktable-get-clocktable))
(summary-text (org-clocktable-format-summary clock-table-data))
(api-endpoint "https://api.openai.com/v1/engines/davinci/completions")
(api-key "YOUR_API_KEY")) ; Replace with your actual API key
;; Construct the HTTP request and send it to ChatGPT
(with-current-buffer
(url-retrieve-synchronously api-endpoint
`(("text" . ,summary-text)
("api_key" . ,api-key)))
(goto-char (point-min))
(search-forward "\n\n")
(let ((response-json (json-read)))
(message "ChatGPT summary: %s" (cdr (assoc 'choices response-json)))))))
All you elisp experts out there, let me know how it did.
I know at least the API endpoint is wrong, but generally speaking, it seems to be doing the right thing. Such function could be extended to include org-agenda information, TODO items, and many other things that would use AI to augment the existing functionality of Emacs and org-mode to tailor them to my needs.
Scorecard (Unofficial)
| Rd | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Stevenson | 9 | 9 | 9 | 10 | 10 | 10 | 10 | 10 | 9 | 9 | 10 | 10 |
| Harutyunyan | 10 | 10 | 10 | 9 | 9 | 9 | 9 | 9 | 10 | 10 | 9 | 9 |
Shakur did enough not to lose. It was a boring fight, but he should've done enough to be up on the scorecards.
I learned from Matthias Ott that Mastodon created a new Open Graph meta tag which displays a direct link to the website owner's Fediverse (Mastodon, Pixelfed, Threads, etc...) profile as part of the URL preview card on the Mastodon web and mobile apps.
I just added support for it on my website.
All I had to do was add the following tag to my site.
<meta property="fediverse:creator" content="@lqdev@toot.lqdev.tech">
I'm not running the nightly version of Mastodon on my instance, but if anyone on an instance where this is already supported like mastodon.social can verify and let me know it's working, it's much appreciated.
Ring Walk
Didn't see Claggett's but Lopez ring walk was a little cringe.
Scorecard (Unofficial)
| Round | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lopez | 10 | 10 | 10 | 10 | 10 | 10 | ? | 10 | 9 | 10 | 10 | 10 |
| Claggett | 9 | 9 | 9 | 9 | 9 | 9 | ? | 9 | 10 | 9 | 9 | 9 |
Rd 1
Claggett put more pressure but Lopez got in the better shots and looked in control even boxing off his back foot.
Rd 2
Claggett still putting in a lot of pressure but Teofimo still looks in control.
Rd 3
Teofimo still in control. Claggett has some damage to the face but still keeps going forward.
Rd 4
Some nasty shots from Teofimo but Claggett still keeps coming forward.
Rd 5
Solid back and forth
Rd 6
Claggett is solid. Making Teofimo work and he's got some wear on his face.
Rd 7
PC battery died 😃
Rd 8
Big uppercuts from Teofimo but Claggett keeps coming forward.
Rd 9
Claggett keeps coming forward and he landed some good shots.
Rd 10
Teofimo stole the round at the end. Not like he needed to. He got the better shots. Sad to see because Claggett is putting the pressure but not doing as much damage.
Rd 11
Much of the same. Claggett reguses to go away. Sadly, he hasn't done enough that if / when it goes the distance, he'll lose. He needs a knockout and it looks unlikely.
Rd 12
Teofimo still looked fresh in this one. Claggett still kept the pressure though
Verdict
I'd be surprised if Lopez didn't win. Claggett showed a lot of heart and made Teofimo uncomfortable. Sadly it wasn't enough though.
Ramirez dominated most of the fight but that knockout was insane. Watching it live, it wasn't easy to see but in the replay, Ramirez exploded from the botttom and nearly took Benitez' head off. He wasn't out cold but he got his bell rung and just didn't make the count. Still, I hope he's okay. He took a beating the rest of the fight.

Better late than never. Here's May's drop.
Some of my favorites this month are:
- Journey of the Sorcerer by the Eagles
- Any of the songs by Piero Piccioni
- Any of the songs by Fishmans
6 months in and these are the main takeaways.
- At 51 notes, I'm 10 over last year's total notes.
- Responses are healthy. I'm closing in on 200. I wasn't as active the month of May so I'm still shy of last year's mark, but given it's still only halfway through the year, it seems like good progress so far.
- Most of my posts continue to be related to AI. While I can believe it, I also think I could be more specific and get more creative with my tags. Given the lead AI has though in terms of tag numbers, it'll be harder for those more fine-grained tags to come through.
- I won't use the word struggle, but I have paid less attention to long form posts. There's a few that I have planned for June, so that should help bump those numbers.
Overall I'm happy with the progress and use I'm getting out of the website.
Some things I'd like to work on are simplifying my authoring process. Although github.dev and Codespaces can be convenient, it's a hassle. Authoring content locally reduces some of that friction. However, I'm still bound to my laptop.
As a Day One subscriber, I haven't maximized my subscription. This past week I've started to use it more for bookmarking articles I'm reading. Maybe that's a way that I can bookmark articles when on the go and when I'm ready to reshare them on the website, I can just copy from there.
Something else I can use Day One for are to start longer form blog or note drafts. Then, when I'm ready to do more serious work and publish them, I can continue on my laptop.
I may have spoken too early in my post about X not displaying bio links correctly.
Not sure if it was a glitch or what was going on, but I now see my domain correctly displayed as the bio link. All good.
I'd be interested in knowing whether others have experienced something similar.
While making some updates to my X profile, I noticed the link displayed on my bio isn't the same one I configured in the form. Instead it's a t.co shortened link. I get I'm just a free user on the platform but that seems like an annoying change. I haven't found much details about the change, but I'd hope paying subscribers get the "perk" of having control over how the link on their bio displays.
![]()
Just enabled discovery for my blogroll based on the OPML blogroll spec. While technically not part of the spec, I also have similar collections for podcasts and YouTube. I've added those as well.
<head>
<!--...-->
<link rel="blogroll" type="text/xml" title="Luis Quintanilla's Blogroll" href="/feed/blogroll/index.opml">
<link rel="youtuberoll" type="text/xml" title="Luis Quintanilla's YouTube Roll" href="/feed/youtube/index.opml">
<link rel="podroll" type="text/xml" title="Luis Quintanilla's Podroll" href="/feed/podroll/index.opml">
<!--...-->
</head>
youtuberoll doesn't really roll off the tongue, but I'm hesitant to call it videoroll or vidroll. My concerns mainly come from the fact that YouTube != video.
Ideas welcome!
What a great fight.
I think the judges did a great job. It was a close fight, but the knockdown won it for Usyk.
The ref did a good job not stopping it in the 9th and giving Fury a chance to come back.
I think Fury clowned around too much in the beginning and didn't hit the gas in the middle rounds letting Usyk come back in the later rounds. The clowning probably was masking because Usyk is most likely the best fighter he's fought in his career.
Great job by both fighters coming back, Usyk in those middle rounds and Fury from the knockdock where it looked like he was done.
Also, it's business and most likely both fighters carried each other rather than press the action because this leaves the door open for the rematch.
I doubt Usyk does the trilogy with Anthony Joshua given the series is 2-0. The next fight for both will probably be the rematch.
Still not mid-year and I'm making progress on publishing to the website. Some notable observations this month:
- At 43 notes, I'm already past the total number of notes posted in 2023. Weekly summary posts like Create Finds and Weekly Summary continue to contribute towards this number.
- Despite a slow last week of April with no posts, I was still able to manage adding nearly 40 new posts. At 184, I'm closing in and expect to surpass last year's response posts within the next two months.
- I'm still working through how to go about publishing longer-form content to the blog. I'm still only at 3 posts. Given that I posted 8 last year, it's not an elusive target. Still, I haven't figured out what some good topics / experiments I'm doing today would be interesting to expand upon in the blog. I'm in no rush though. I'm enjoying the shorter form posts both notes and responses.
April's drop. This month, I kept coming back to:
- Pon Pon by Khruangbin
- This Feeling I Get by Doug Shorts
Notes
Responses
- 'PBS Retro' is coming to Roku as a FAST channel
- Google Penzai
- The Dumbphone Boom Is Real
- Introducing Phi-3
- Remembering the 90's Video Store
- New Album: Kamasi Washington - Fearless Movement
- One year with the Light Phone 2
- SAMMO: A general-purpose framework for prompt optimization
- The Internet Used To Be Fun
- Calculus Made Easy
- Ghost is federating over ActivityPub
- Introducing Snowflake Arctic
- Grow Your Own Services
- We Need To Rewild The Internet
The website had been out of comission for a few days because my credentials had expired. I could still add posts and make updates. However, none of them were published to Azure.
Figuring out the right incantations wasn't straightforward, so saving the fix for future reference.
Notes
- These models are too damn big!
- Enjoying El Sonido from KEXP
- New podcast (Better Offline) added to blogroll
- Week of April 07, 2024 - Post Summary
Responses
- LLM training in simple, raw C/CUDA
- RecurrentGemma - Open weights language model from Google DeepMind, based on Griffin.
- Beeper was just acquired by Automattic
- Hello OLMo: A truly open LLM
- Molly White's Blogroll
- ARAGOG: Advanced RAG Output Grading
- Rock AlterLatino from Radio Bilingue
- Far Out Guides
- Proton and Standard Notes are joining forces
- DE-COP: Detecting Copyrighted Content in Language Models Training Data
- Using LLM to select the right SQL Query from candidates
- Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
While the size of these smaller language models is significantly less than the trillion parameter models like GPT, they still take up a lot of storage space. Playing around with Mistral 7B Instruct v0.2, the safetensor files containing the weights take up roughly 15GB of space. I'm thinking of playing around with blobfuse to mount a storage container to my local file system. That way, I'm only caching and accessing the models I'm working with at any given time.
I just found El Sonido from KEXP. Albina Cabrera is a great host. I've already found a few new songs and artists to listen to I otherwise wouldn't have been aware of or exposed to.
Notes
- New Album - Notebook Fantasy from Chicano Batman
- New podcast added to blogroll
- Website Post Statistics - April 2024
- Week of April 1, 2024 - Post Summary
- Thoughts on World Wide Whack
- Crate Finds - March 2024
Responses
- Large Language Models Are Zero-Shot Time Series Forecasters
- Google Podcasts is gone — and so is my faith in Google
- IPEX-LLM
- Introducing Stable Audio 2.0
- Start using ChatGPT instantly
- Introducing Command R+: A Scalable LLM Built for Business
- OpenAI - Introducing improvements to the fine-tuning API and expanding our custom models program
- Announcing DBRX: A new standard for efficient open source LLMs
- ReALM: Reference Resolution As Language Modeling
- T-Mobile Sidekick’s Jump button made mobile multitasking easy
- The Matrix is coming back for a fifth movie
While doing chores today, I put on one of the episodes from Ed Zitron's Better Offline podcast. This resulted me in me basically binging the rest of the episodes on the backlog. Also, it's now made its way into the regular rotation with other podcasts and the podroll.
I saw this come across my feed a few days ago but didn't get around to listening to it until today. I really enjoyed it.
Some of my favorite tracks are:
- Chanel Pit
- Imaginary Friends
- Shower Song
My website stats script seems to be running as expected.
Some highlights from last month:
- With 33 notes posted in the microblog, I'm about 80% of the way to the number of total notes posted last year. These monthly summary posts, as well as my Crate Finds and Weekly Summary posts have somewhat contributed to this number but I like the pace I'm setting. Not even halfway through the year and it looks promising.
- While most of my responses are reshares (93), there's still a broader distribution across bookmarks and other type of reponses posts.
- AI continue to be the main topic I share posts around.
- The Verge is still one of the main sources I reshare. Personally, the redesign has contributed to the way I consume content from The Verge but also, the topics covered align with many of the things I'm interested in.
I have yet to make progress on the long-form posts, but there are some experiments I've been tinkering with that will eventually make it on there.
Similar to February, I didn't spend too much time listening this month so the list is somewhat short. I got a chance to listen to a few songs off Chicano Batman's new album, Noteboook Fantasy though. Here's the drop for March 2024:
I have to admit, I wasn't the biggest fan of the singles released before the album. Though I have to say, there's been a few times Era Primavera has been stuck in my head. Very catchy.
I haven't listened to the whole thing, but so far I really like the tracks Notebook Fantasy, Parallels, and Beautiful Daughter.
Introducing the 100 Sways project.
Over the next few months, I plan on creating artifacts like blog posts, newsletters, and websites using Microsoft Sway.
Bookmark the site 100sways.lqdev.tech and follow along!
Note: If you can't access the website, you can use the direct link (https://sway.cloud.microsoft/aC19McbR3xcNo6s8).
What is the 100 Sways project?
This project is an attempt to show how you might use Sway as a publishing platform for content like newsletters, blog posts, and websites.
This project was inspired by James' 100 things you can do on your personal website post.
Motivations
- Learn more about Microsoft Sway
- Show how you can make the most use out of apps and services already included with your Microsoft Account
- Show how easy it is to create and consume web content using Sway
Notes
- New Forums Page
- Week of March 18, 2024 - Post Summary
- New Era of Work - Windows / Surface Event Blog (March 21, 2024)
- Looking for Discord server / community recommendations
- Use AI to generate a blogroll others can subscribe to
Responses
- Building Meta’s GenAI Infrastructure
- Fast Inner-Product Algorithms and Architectures for Deep Neural Network Accelerators
- Diffusion models from scratch, from a new theoretical perspective
- Spreadsheets are all you need
- Introducing Stable Video 3D: Quality Novel View Synthesis and 3D Generation from Single Images
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- Nvidia reveals Blackwell B200 GPU
- Demystifying Embedding Spaces using Large Language Models
- Quanto: a PyTorch quantization toolkit
- LaVague - Large Action Model framework
- Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs
- Algorithms for Modern Hardware
- Ollama now supports AMD graphics cards
- Diffusion Models From Scratch
- Machine Learning for Games Course - HuggingFace
- Stability CEO Resigns
- The Tokenizer Playground
- Releasing Common Corpus: the largest public domain dataset for training LLMs
- Grok-1
- OpenAI Transformer Debugger
- The Online Local Chronicle
- MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training
Following the patterns of a blogroll and podroll, I decided to post a forums page to list various forums and communities I find interesting.
I've also created an OPML file for it so you can subscribe to them in your RSS reader of choice.
Discord is good for communities. For example on servers like Shudder there's watch parties and HuggingFace reading club gets together to discuss some of the latest papers. For events, this works really well because everyone can participate in real-time. However, I find that outside of events or general chat, it's difficult to follow the message stream. I like the forum format with topics / threads much better.
If you have any forum recommendations, feel free to send them my way.
I've seen several posts about blogrolls recently across my feed. My own needs some updating, but you can find it here. I also created one for podcasts which I call a podroll.
I've also seen posts about making the indie web easier.
With both of those in mind, that's how this post came to be.
Let's say that you have a blogroll on your website which might just be a list of links to the respective RSS feeds.
If someone wanted to subscribe to the feeds on your blogroll, they could just copy the links and add them to their RSS reader. However, as your blogroll grows, doing this in bulk can be tedious.
One way you can make it easier is using OPML files. Many RSS readers support importing feeds using OPML files.
You could go through the process of figuring out what OPML is, how you need to format the file, and then do the work of creating and populating the file. Or...you could use AI.
In this example, I opened up Copilot, provided it a list of links to RSS feeds and asked it to generate an OPML file. You can take the outputs generated using AI, save them to a file, and add it to your website.
Now people who want to subscribe to the feeds on your blogroll can just load the OPML file into their RSS reader and all the feeds will be automatically added.
12:03
- Copilot is making people more productive.
12:06
- Copilot for Microsoft 365 integrated into Windows.
- Demo: After coming back from vacation, you want to catch up.
- Ask copilot about latest project updates
- Ask copilot for summary of meeting you missed which generates a summary of the discussion and action items.
- Copilot then can help you tackle the action items like drafting and sending e-mails.
12:09
- Demo: Using Copilot to configure Windows settings
12:13
- Demo: Using Windows App to manage Windows 365 cloud PCs
12:21
Surface Pro 10 and Surface Laptop 6 announced for business. Comes with latest Intel processors, Neural Processing Units (NPUs), and Copilot.
12:39
The demo showing a .NET development workflow on the Surface Laptop 6 was great. Usually that same workflow longer on my Lenovo P4.
I finally decided to dust off my Discord. So far, I've joined several communities like:
- HuggingFace
- LangChain
- LlamaIndex
- Racket
- Virtual ML.NET
- Shudder
- ClubTwit
- ...and many others
I've noticed that server / community discovery needs improvement, so I'm asking for your recommendations!
General topics I'm interested in:
- AI
- Machine Learning
- Open Source
- Software Development
- .NET
- F#
- Open Web
- IndieWeb
- Fediverse
- Lisp
- Tech
- Personal Finance
- Podcasts
- Books
- Travel
- Retro Tech
- Retro Gaming
E-mail me your recommendations at contact@lqdev.me or send me a Webmention!
Thanks in advance.
Notes
Responses
- Building Meta’s GenAI Infrastructure
- Fast Inner-Product Algorithms and Architectures for Deep Neural Network Accelerators
- Diffusion models from scratch, from a new theoretical perspective
- Spreadsheets are all you need
- Introducing the Proton Mail desktop app
- What I learned from looking at 900 most popular open source AI tools
- LaVague - Large Action Model framework
- Enhancing RAG-based application accuracy by constructing and leveraging knowledge graphs
- Algorithms for Modern Hardware
- Ollama now supports AMD graphics cards
- Diffusion Models From Scratch
- Apple Vision Pro Perspectives - Hugo Barra
- Grok-1
- OpenAI Transformer Debugger
- Bluesky’s Stackable Approach to Moderation
I was sitting at the airport waiting to board my flight and over the PA system, the usual "see something, say something" security announcements were going off.
Although I've heard these many times before, this time for some reason there's one that caught my attention and got me thinking. I don't remember the exact words, but basically the gist of it said something like, "If anyone asks you to check in baggage other than your own, do not accept it".
I barely even want to deal with my own bags. Why would I want to deal with someone else's bag?
I've been trying to visualize scenarios where:
- Someone would come up to you and ask you to check in THEIR luggage
- You would accept
Maybe in scenarios where you're traveling with friends or family? In the case of family, maybe someone doesn't have a carry-on and if there's an extra bag that's small enough to be considered carry-on they'll "claim" it as their carry-on to not pay the extra fees. Still though, that's not checking it in. I'm just having a hard time seeing it.
Putting this out there ahead of time - no, stranger, I will not check in your bag.
Blogs
Notes
Responses
- Microsoft to end its Android apps on Windows 11 subsystem in 2025
- The surprising connection between after-hours work and decreased productivity
- Stable Diffusion 3: Research Paper
- Wix’s new AI chatbot builds websites in seconds based on prompts
- Apple Podcasts now includes transcripts
- 5 reasons why desktop Linux is finally growing in popularity
- Levels of Complexity: RAG Applications
- Training great LLMs entirely from ground up in the wilderness as a startup
- Gemma PyTorch
- Guest host Hank Green makes Nilay Patel explain why websites have a future
- Inflection-2.5: meet the world's best personal AI
- The missing graph datatype already exists. It was invented in the '70s
- Today’s smart homes: the hopes and the realities
- Introducing the next generation of Claude
- You can now train a 70b language model at home
Short month and not as much time spent listening to music. As a result, this month's list is a short one. Here's the drop for February 2024:
Just finished reading Agency by William Gibson. I was not a big fan. I posted my review with more details.
Another successful run of my monthly script to track post statistics.
Some highlights:
- Over 100 responses through the month of February. That's basically halfway through the total number of responses I posted in 2023.
- Almost 20 notes. Similar to responses, I'm halfway through the total number of notes posted last year.
I've never done 100 days to offload. Unintentionally though, between notes and responses, I'm well past it.
When it comes to more long-form posts, I haven't posted as many. Still only at 1 for the year. However, there's a few projects I'm looking to undertake that involve some of my publishing practices and AI. That should result in a healthy number of longer blog posts.
New song from Chicano Batman's latest album, Notebook Fantasy.
Good thing I have elfeed as my backup so I can use that in the meantime.

I have no idea what I just watched, but I liked it. I thought Nicolas Cage making weird movies was a relatively recent thing, but I guess it goes way back to the 80s. I kept getting thrown off by his accent, which I only noticed about a quarter into the movie and even later into the movie sometimes it wasn't there. His descent and transformation into "Nosferatu" was interesting to watch. Mostly funny, but sometimes just weird and disturbing.
If you're interested, it's currently streaming for free on Tubi
Success!
At the end of last year, I created an automated script to tally some basic stats about my posts on this site.
Last month, due to user error, it triggered but failed to run susccessfully.
This month though, it ran as expected!
Some highlights:
- I'm posting more notes (short micro-blog style content). Through January, I'm already over 30% of total notes posted last year which is what I'm working towards.
- I've already posted 50 response posts through January. This is already over 20% of total responses published last year (223)!
- I'm resharing more than bookmarking. Still figuring that one out but I think this is a good start.
Not sure how these videos ended up showing up on my feed but I'm glad they did.
They're weird, creepy, and fun all rolled into one.
I'm surprised that they have such low views / subscribers.
Check them out on YouTube.
The Archive in Between


Alternate Bazaar Art

January 2024 drop of Crate Finds. Ones I kept coming back to:
- Where Are You by 54 Ultra
- Language of Love by Jason Joshua
- A Love International by Khruangbin
- Dreameater by Healing Gems
- La Isla En El Sol, Pt. 2 by Real Cumbia Activa RCA
- Portrait of a Time by Peter Cat Recording Co.
New Chicano Batman album!
It's unfortunate Gabriel isn't part of this project but looking forward to the new sound tour.
Brain dumping a bunch of half-formed thoughts.
Over the past few days, I've been thinking about different forms of sharing content. With the shifts in social media towards smaller, more private communities, is it possible to get the best of feeds for sharing updates and information but in a smaller more intimate way?
Here's a few of the options I came up with:
Journals
Examples: Day One Shared Journals
- Pros
- Made for an audience of one, but other can collaborate on it.
- Depending on the interface, looking back at specific days and events that took place is easy to look back on.
- May be able to include different forms of media (i.e. audio, video, photos)
- Cons
- No individual profiles
- May require everyone to use the same app / service
Examples: Newsletters, Mailing lists
- Pros
- Almost everyone has an e-mail address.
- Built on standard protocols.
- Producers can use any app they'd like to compose e-mails.
- Consumers can use any app they'd like to read e-mails.
- Could use any app / client / service-provider they'd like. (Federated by default)
- Cons
- Content rendering may differ based on app.
- Could add to the noise already present in your e-mail inbox.
- No individual accounts / feeds.
Messaging Apps
Examples: Discord, Matrix, IRC, Slack, Signal
- Pros
- Sharing could be done via SMS (though this would limit the content you share).
- You could form various sub-groups to sub
- Cons
- May require everyone to use the same app / service.
- May not have a way to view individual profiles or feeds.
- Because conversations are not often grouped by topics, it might be difficult to find conversations, especially older conversations.
Private blogs
Examples: Private WordPress Blog, Haven
- Pros
- Produces can use any tool / service to author and publish posts.
- Consumers can access via any browser of their choice.
- Cons
- May have to host your own service.
- Consumers may have to create accounts and passwords for each of the private blogs they follow.
Fediverse
Examples: Mastodon, PixelFed, PeerTube
- Pros
- Familar social media interface.
- More availability of apps and services that form part of the Fediverse make it easier for producers and consumers to use what makes the most sense for them.
- Cons
- Limited to the format supported by the app / service (i.e. Pixelfed is for images / video, PeerTube for video, etc.).
- May require you to host your own service.
P2P Social Media
Examples: ScuttleButt
- Pros
- Could be made for an audience of one but shared with other peers.
- Decentralized by default.
- Access individual feeds.
- Cons
- Similar to the Fediverse, being exposed to new protocols and technical terms may make onboarding and adoption challenging.
- May require you to host your own service.
- Protocols haven't been widely adopted so users are limited in the apps / services they can use for this.
Forums
Examples: NixOS Forum, Lemmy
- Pros
- Could create threads and conversations on various topics
- Easy to search and tag content
- Cons
- Someone would have to host a server
- Might not work well for small groups
RSS feeds
This is a variation on the private blog. Except instead of having a website that displays the posts, you just have an RSS feed.
Examples: RSS-Only Club
- Pros
- Producers can use any software they'd like to create and publish their RSS feed
- Consumers can use any feed reader to access and read content
- Everyone could have their own feed, so effectively they'd be like profiles
- Cons
- You have to figure out how to produce and host the RSS feed
- Can't really control who sees this since the feed is public. Maybe private feeds could help here.
- Limited interaction. Users can't comment or reply to items in a feed.
Note that this is not an exhaustive list of pros and cons, just a few that I thought of. I persoanlly would skew towards e-mail and messaging apps. The main reason at least with e-mail is that everyone is familiar with it and most likely won't have to create separate accounts on various silos to communicate and engage with others. With apps like DeltaChat you could actualy combine them and get the best of both.
What are your thoughts?
The first half of 2024 will be good for new music. Chicano Batman is releasing something in the next few days. Last night I found out Khruangbin released a new single, Love International, and has a new album coming out called A La Sala on April 5th. I can't wait!
I didn't know Martin Lawrence was still making movies. I knew about Bad Boys but that was almost 4 years ago. Just watched Mindcage, one of his latest ones. It was alright. The story is similar to Silence of the Lambs. Detectives seeking help from a manipulative serial killer to catch another killer on the loose. The twist at the end was interesting and not what I was expecting.
I use NewsBlur as my feed reader. In it, I subscribe to:
- newsletters
- personal blogs
- sports blogs
- news publications
- GitHub releases
- Mastodon feeds and tags
- Bluesky feeds
- StackOverflow tags
- subreddits
- podcasts
- severe weather alerts
- YouTube channels
- PeerTube instances and channels
- Lemmy instances and sublemmys? (I don't know the Lemmy lingo yet)
- Forums
Basically, if it has an RSS feed, I subscribe to it there.
Today I noticed I'm subscribed over 1000 feeds (1042 to be exact)!

Over 300 of them are personal blogs. This has taken a few years to curate. I remember my reader being empty when I first started. As I've read newsletters and personal blogs, I've followed things they've linked to which is where I find even more feeds to subscribe to, especially when they're easy to find.
There's some pruning that needs to happen at this point whether that's because of broken links or I just don't read those publications often. However, I find myself usually checking in on personal blogs and newsletters on a daily basis so I think many of those will stay.
I like to use my response feed to bookmark and reshare interesting content I find online. Typically my workflow looks like the following:
flowchart TD A["Scroll through feed reader"] --> B["Open articles I want to read in a new tab"] B --> C["Read articles"] C --> D["Create a response file to publish on my website"] D --> E["Capture interesting information from the article in the response file"] E --> F["Publish the response"]
The bottleneck I usually find is in the middle steps of creating a response file and capturing the relevant content. This usually happens as I'm reading the article. For a single file, it's not a big deal. Doing it for several can be time consuming, especially with the number of feeds I subscribe to.
There's a few things I think could help here:
- Create one response file and do a daily link dump.
- Create a browser extension or system where I can:
- Highlight text or content on a page
- Right-click or use a keyboard shortcut to create an entry for the content I highlighted
- Create an entry in a database somewhere which captures the URL of the page I'm looking at.
- I enter a few more details like the file name I want to use and response type
- When I'm done with my session, I can publish. This will use the database content to compose the content for my response and create a PR
The first option is simple but I don't like it because although most of the content I come across is tech related, I prefer having individual articles I can link to with their own tags to make it easier to build relationships.
The second option sounds complex, but it's basically a web highlighting tool. I know there's a few out there already so maybe worth checking out.
I'd prefer to build my own to tailor it specifically to what I want just like my website generator. However, it would mean that I'd have to spend some time thinking about how to implement it.
It'd be a fun project though. Maybe worthwhile experimenting with building an AI agent to help me use the content I captured to nicely format the response.
Lately I've been using Spotify to listen to audiobooks since it's included as part of their Premium tier. That's how I started listening to Making It In America. What I didn't know was that there's a limit to the number of hours you can listen in a given month. I only got as far as chapter 2 and now I have to wait 7 days for my listening hours to be replenished for the month.
As a result, I started building the reading backlog at the local library which is now at an unreasonable 164 books that I probably won't get to. It got that way because I added many of the Best of 2023 recommendations from my local library to my wishlist. I haven't added many of those to my library page because I don't want to go through the process of manually adding them. I should look into whether there's an automated way of getting that information via APIs or batch download.
Last night I started reading How To Sell A Haunted House and I'm enjoying it so far. The next one on deck is A City on Mars.
I had known about Gravatar since its early days. I was under the (incorrect) impression that it could only be used to comment on blogs. I thought when you created an account, you added your name, e-mail, and image as part of your profile. Then, when you wanted to comment on blogs, instead of creating individual accounts or profiles, you could just reuse your Gravatar profile. That's partially true. However, I'm happy to report I was wrong and there's so much more.
While commenting on Matt Mullenweg's Birthday Gift post, I didn't use a Gravatar profile. This prompted Matt to kindly respond via e-mail and suggest I check out Gravatar. I put it off for a few days. Eventually, I decided to check it out and I'm glad I did. Thanks Matt!
The signup process was simple. All I had to do was enter my e-mail address. This immediately sent me a confirmation e-mail which I then used to proceed with onboarding.
Here's where things got interesting.
You can add all the things I was already aware of (name, e-mail, photo). However, you can also do much more than that! You can add your own verified accounts, links, contact information, and payments.
As of the time of this writing these options include:
- Accounts
- WordPress
- X / Twitter
- TikTok
- Tumblr
- Mastodon
- GitHub
- Twitch
- Fediverse
- Stackoverflow
- Calendly
- Vimeo
- TripIt
- Foursquare
- Contact info
- Phone number (home, work, mobile)
- Contact form
- Calendar
- Payments
- PayPal
- Patron
- Venmo
- Crypto
- Bitcoin
- Litecoin
- Dogecoin
- Ethereum
- XRP
- Cardano
- Custom
In addition to those integrations, you can also provide as many of your own custom links as you'd like. In my case, I've chosen to link to my website and RSS feeds. The options are endless though.
I don't have a Linktree profile so I can't objectively say how Gravatar compares to those offerings. At their core though, Gravatar and Linktree seem to address similar problems.
If you're not yet committed to having your own place on the internet (website/blog) or if you're looking for a way to organize your digital identity in single place, Gravatar is an excellent option. I'd encourage you to check it out.
You can find my Gravatar profile at lqdev.me/gravatar!
Based on the post, own your RSS links, I decided to set up redirects for all my RSS feeds which was very easy to do using Azure CDN. You can find the updated links in my subscribe page. If you're currently subscribed to any of those feeds, you can keep using the old URLs but I'd recommend updating your feed reader with the latest URLs.
In the past two weeks I've been listening to a few episodes from the Huberman Lab podcast. In many of the episodes, the host, Dr. Andrew Huberman, brings on guests to talk about topics like nutrition, fertility, motivation, finding your purpose, and many others. It's interesting though that despite the large diversity of topics and guests, at their core, many of the conversations ended up coming back to mind, body, and soul. More specifically, nurturing those various aspects of our lives. This includes but is not limited to, fueling your body with the right foods, building community, being active, learning new things, exposing yourself to new experiences, etc.
Currently I'm using org-mode in Emacs for note-taking, journaling, habit-tracking, task management, any many other things. I've heard good things about Notion and Obsidian but haven't made the switch because I like the flexibility of Emacs. I learned about Anytype a few months ago and it looked like it might be a good replacement. I'd been holding out because back then it didn't have local-only mode. In their latest release, they added local-only mode so maybe it's finally time to try it. First though, I have to figure out if it works on NixOS.
A few days ago, I posted about a script I wrote. The script computes computes post metrics on my website. That's what I used to author my (We)blogging Rewind 2023 posts. Because I want the script to run at periodic intervals, I automated the process using GitHub Actions.
The script is scheduled to run on the first of every month and I'm happy to report that it works! Kind of.
The GitHub Action was successfully triggered at the defined interval. Unfortunately, the script failed due to a user error which I've since fixed. Come February 1st, everything should work as expected though, so I'm happy about that.
So basically this Orange Bowl game between Georgia and Florida State is a look at what the College Football Playoff could've been, had both teams been part of the playoff. I know teams in general were affected by the transfer portal, but it's not even close. It's barely halftime but the game is basically over unless Florida State finds a way to score 6 touchdowns in the next 30 minutes.
If 2023 was the year of AI and the Fediverse, is 2024 the year of Gemini?
I've been seeing a few posts about Gemini cross my feed reader which is more than I'm used to seeing. These include:
Gemini is weird in a fun way.
Since content is text-based, using terminal clients like Elpher and Amfora make it easy to browse pages (capsules) and blogs (gemlogs).
Late to the App Defaults train but here's what I use as of December 2023. For the latest list and Every Day Carry (EDC) list, see the Uses page.
- Operating System: NixOS (Desktop) / Android (Mobile)
- E-Mail: Thunderbird (Desktop) / Outlook (Mobile)
- Feed Reader: NewsBlur
- Podcasts: AntennaPod
- Music: Spotify
- Notes: Emacs (Org-Mode)
- Tasks: Emacs (Org-Mode) / Microsoft To-Do
- Office: LibreOffice
- Browser: Firefox
- Messaging: Element / Signal (Molly)
- Maps: OSMAnd~
- Text Editor: Visual Studio Code
- E-Book Management: Calibre
- Reading: Libby
- Video: mpv / VLC
- Authenticator: Aegis
Update from yesterday. 2023 is still not over. I think I can squeeze out at least one more post for the year 🙂.
Blog post counts
| Year | Count |
|---|---|
| 2023 | 7 |
| 2022 | 7 |
Note counts
| Year | Count |
|---|---|
| 2023 | 37 |
| 2022 | 36 |
Yesterday I posted aggregate statistics about this website in the post (We)blogging Rewind 2023.
I thought it'd be cool to see which domains I referenced most in my responses. Here's the breakdown of the top 5.
| Domain | Count |
|---|---|
| github.com | 15 |
| huggingface.co | 11 |
| arxiv.org | 10 |
| openai.com | 6 |
| www.theverge.com | 4 |
No surprise here given that AI was one of the top tags in my responses.
Updated script is here stats.fsx.
21:40
This Utah defense are the real MVPs. Utah hasn't been able to put together a drive all game. So far I think I've seen 3-4 turnovers. The fact that Northwestern is ONLY up by 7 is shocking.
21:47
Make it make sense. Something must've happened. Maybe injuries or something. This season they:
- Beat Florida
- Beat USC
- Had a close game against Washington which is now in the playoffs
Yet they can't put together a drive. Something doesn't add up.
21:54
Okay. I think I got it. Utah like many of the Pac-12 teams is a passing team. Northwestern is in the top 25 passing defenses. So I guess this is the toughest defense they've faced?
22:01
7-7!

22:16
Armchair quarterbacking, but at 44% 4th down conversions, I don't think you go for it on 4th and 2 in the middle of the field. No matter how well your defense is playing and going against a backup quarterback.
22:25
And there it is. Starting QB came back into the game and had a short field to work with against a tired defense. Offense is going to have to dig deep for Utah.
22:33
That's the game. Bad execution on 4th down again.
In my recent post, Using Generative AI to produce Spotify Clips I listed a bunch of challenges but realized I missed a big one. While listening to IJ by Sam Gendel, I realized, what do you do about instrumental songs, solos, or songs with few lyrics?
Some sort of audio-to-video technique?
Maybe using metadata like title, genre, beats-per-minute (BPM), spectrogram, and musical notes would work?
Or generating an image and animating it or its background to add depth similar to how in the VideoPoet blog post, the image of the Mona Lisa is animated.
It would be a fun experiment.
Inspired by Spotify Wrapped and Antennapod Echo, I decided to look back at my activity on this website for 2023. Here is the snippet I used to generate these metrics.
Posts by Year
Blog
Blog posts are my more formal, long-form content. This year, I published less blog posts than last year.
| Year | Count |
|---|---|
| 2023 | 5 |
| 2022 | 7 |
Part of that includes me getting in my head about what these posts "should be". Historically, they have been detailed technical posts related to a project I've worked on like Accept Webmentions using F#, Azure Functions, and RSS. I haven't stopped experimenting and tinkering, but because they aren't end-to-end solutions, I don't think of them as "blog post worthy". That doesn't mean though that learnings and growth haven't come from them. In more recent blog posts like AI like it's 1999 or 1899 and Quick thoughts about Snapdragon Summit 2023, I've started experimenting more with just posting. In 2024, I want to be more flexible in my posting and not worry too much about whether the blog posts are "good enough".
Microblog
This site also contains a microblog feed, one for notes and another for responses.
Notes
Notes tend to be original content that although can include links to external content, they are short-form and informal versions of blog posts. This post is an example of a note. This year, I posted less notes than last year.
| Year | Count |
|---|---|
| 2023 | 33 |
| 2022 | 36 |
Usually, when these notes start to get long, I turn them into blog posts. Quick thoughts about Snapdragon Summit 2023 is an example of that. However, I haven't set a criteria for what makes a note "long". This post for example I think is getting to the "blog post" length. I can't tell you why though, it's just "vibes". One of the benefits of starting with notes types of posts is that the frame of mind is more informal which lets me just write and post without thinking too much about what the post "should be". In 2024, I want to continue using notes as the starting point for these types of posts. Maybe later in the future, I just merge them both.
Responses
Responses are reactions to content created / published by someone else. These can include bookmarks, replies, likes (star), and reposts (reshare). This year, I posted significantly more responses than last year.
| Year | Count |
|---|---|
| 2023 | 216 |
| 2022 | 146 |
I'm very happy with this, especially my bookmark use explained later. Not only am I happy because I'm actually making use of my website and the work I put in previous years that enabled me to publish all types of content but also because these responses create a log of my interactions with the internet over the years I can look back at.
Responses by Type
Looking deeper into my responses and breaking them down by type, bookmarks take up the top spot with more than half of my responses being bookmarks. That makes sense since I'm usually bookmarking articles, papers, and other content I come across on the internet.
| Type | Count |
|---|---|
| bookmark | 151 |
| reshare | 48 |
| reply | 10 |
| star | 7 |
Let me start off with bookmarks. Bookmark style reponses on my website have slowly become my default capture system. Now, not everything I read and come across makes it onto my bookmarks. I'm experimenting with the first pass which I might just turn into another post. Generally, the things that are interesting or thought provoking, I post. Bookmark posts generally include:
- Post title - Gives me a readable way to see what the post is about
- Source link - Provides a direct link to the source material
- Tags - Enable me to index and organize related topics
- Quotes / Notes - Provide highlights and things I thought were interesting about the post
When all these pieces come together, they provide me with distilled bits of information that are organized in a way that enable quick retrieval and action when needed.
Moving on to other posts. Since the post type is effectively just metadata, the line between reshare, star, and reply is often blurry. It's not as blurry with replies because I use that to draft replies / comments to other posts and content on the internet. My Tracy Durnell 20th anniversary of blogging post is an example of a reply. In these examples, the replies were directed at someone. However, for star and reshare, I'm still trying to understand where they fit in my flow. Today other than visually expressing the post type, the role these post types serve is webmentions. However, I'm not sure how many websites I create these post types for actually use webmentions. Maybe some analysis worth doing for 2025.
Responses by Tag (Top 5)
AI and LLMs took the top spots which I think in general aligns with what was top of mind for everyone in 2023.
| Tag | Count |
|---|---|
| ai | 104 |
| llm | 42 |
| untagged | 41 |
| opensource | 31 |
| internet | 17 |
Not much commentary here. Tags have helped me organize related content on my website. I do think that I get too high level with my tags and could do a better job of being more specific. Ultimately, there's no limit to the number of tags I can use so why not be liberal with it. The only self-imposed limitation I've placed on myself is the first 3 tags should be the most important because they're the ones that show up when my articles are automatically cross-posted to Mastodon.
Conclusions
Overall, I'm happy with my activity and heavy use of my own website this year. I plan to make even more use of the bookmark type of posts in 2024 and plan on posting more whether that's as a note or blog post, just posting is something I want to work towards.
Exciting developments in the ActivityPub space. A few months ago, the WordPress plugin was released. In the last few days, Threads recently started testing their ActivityPub integration. Not so new but new to me, I saw that Discourse, the forum software, also has an ActivityPub plugin. Flipboard is one of the latest names to express plans for ActivityPub integration. Not sure what the end result will look like when all these platforms are all interoping with each other but I'm excited to see platforms building on open protocols.
Trying something new out I'm calling Crate Finds. I'm using it as a means to look back at either new music I came across or music I'm listening to at various points in time. Kind of like Spotify Wrapped, but less stats and aggregates and more point-in-time snapshots without the granuliarity of scrobbler services like Last.fm.
This is the first drop from Fall 2023.
My Mastodon instance crashed this morning due to a combination of the usual running out of space issue and me being too lazy to remember to remove federated media regularly from my instance BEFORE it crashes. Now I know you can schedule this with CRON jobs but for some reason I've never been able to configure that correctly nor have I been motivated to get to the bottom of it.
Anyway, I went through the usual dance of starting up my services and using the CLI to clean up my instance.
However, none of my commands worked because it couldn't connect to the database. A quick look at the status showed the database and all my services were running which led me to go down a troubleshooting rabbit hole with no end in sight and little guidance as to what might be the problem.
Eventually, before gave up I thought, "my instance is down anyway, couldn't I just turn it off and on again?" I did exactly that and when it restarted I was able to continue with my cleanup tasks as normal.
So as a reminder, if all else fails, try turning it off and on again.
Kind of late, but here's my Spotify Wrapped for the year. No idea how Eslabon Armado snuck in there at the end. It'd be cool if I was also able to get data from my MP3 player which is where I mainly listen to music. Though the artists wouldn't change much.

This was a nice surprise to see when I opened up Antennapod the other day. Using my listening statistics, it was able to compile a yearly summary for me (locally).
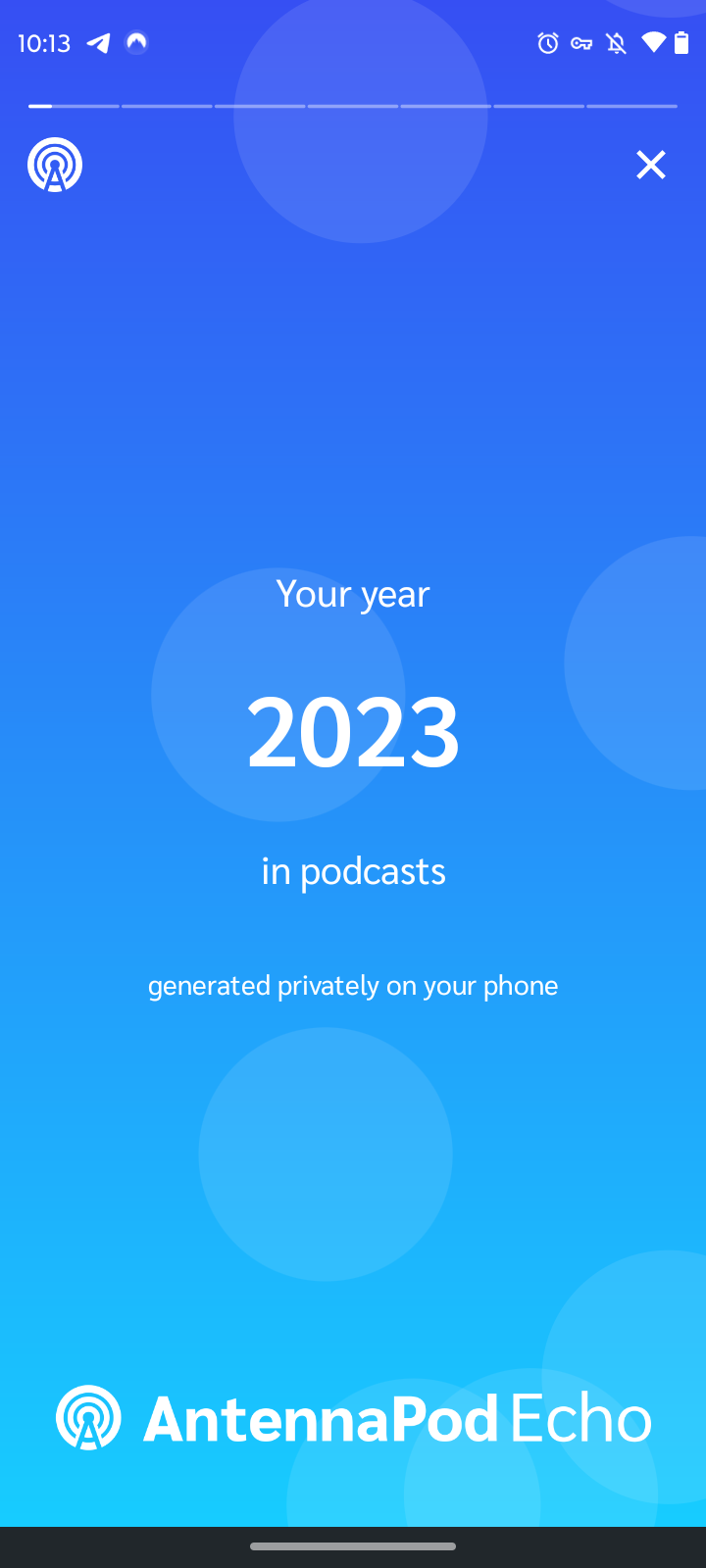
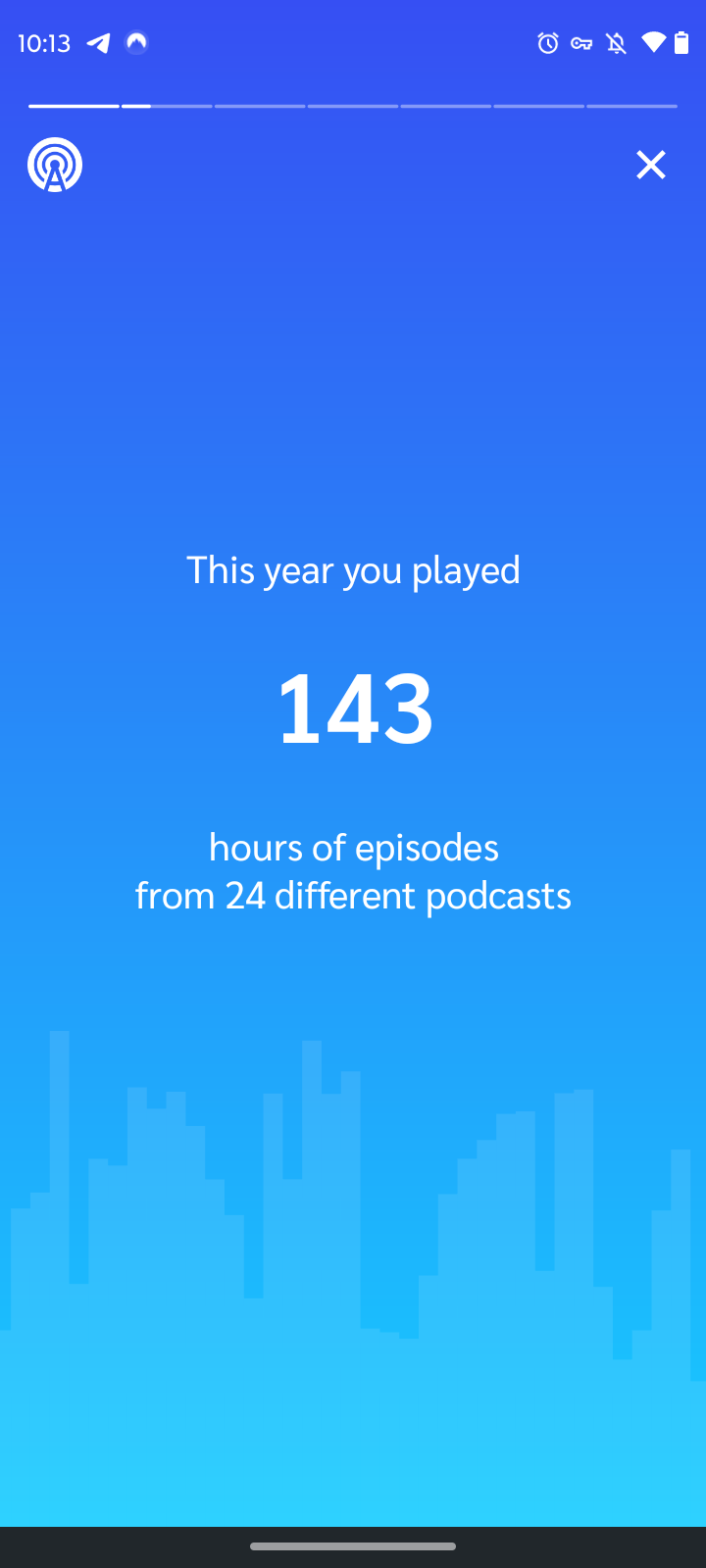
Looks like I have a lot of catching up to do on the backlog.
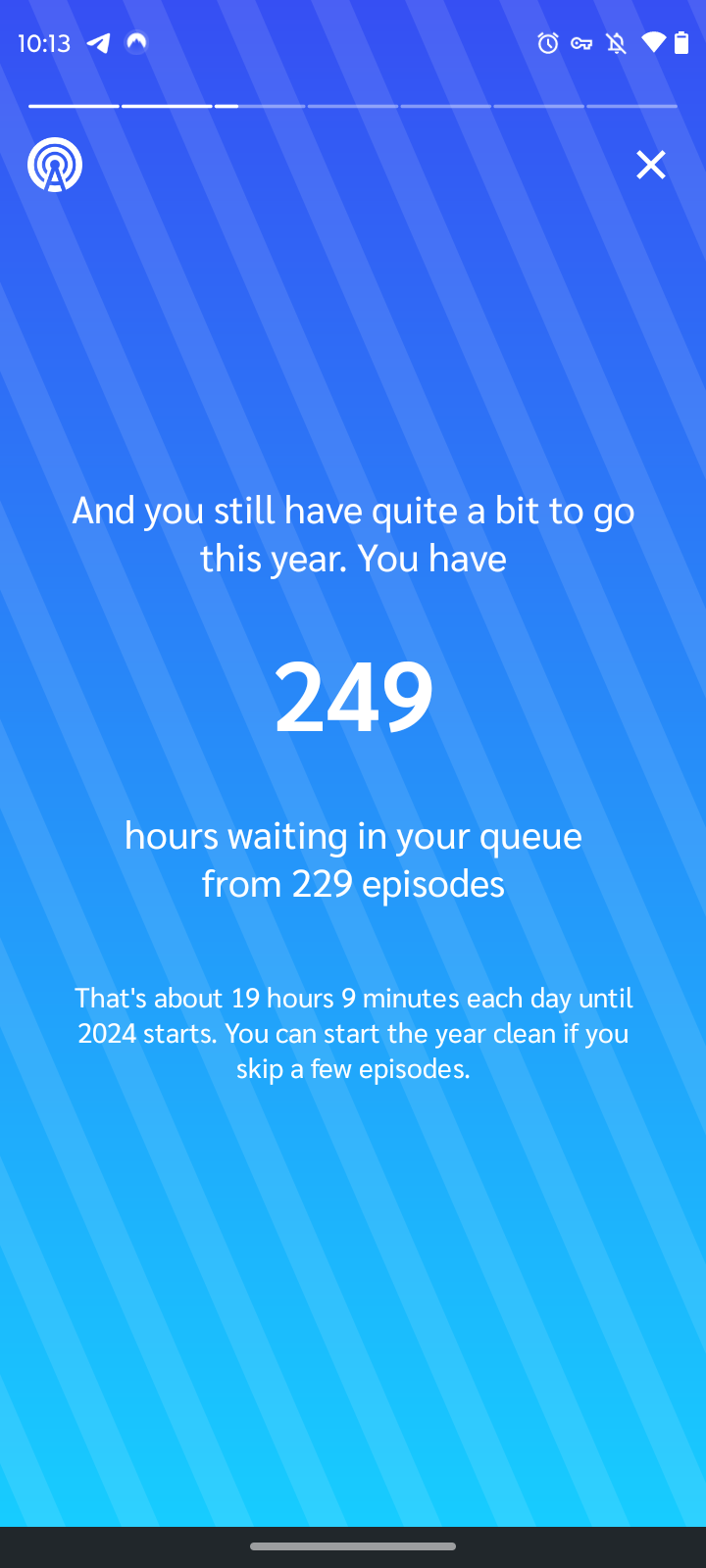

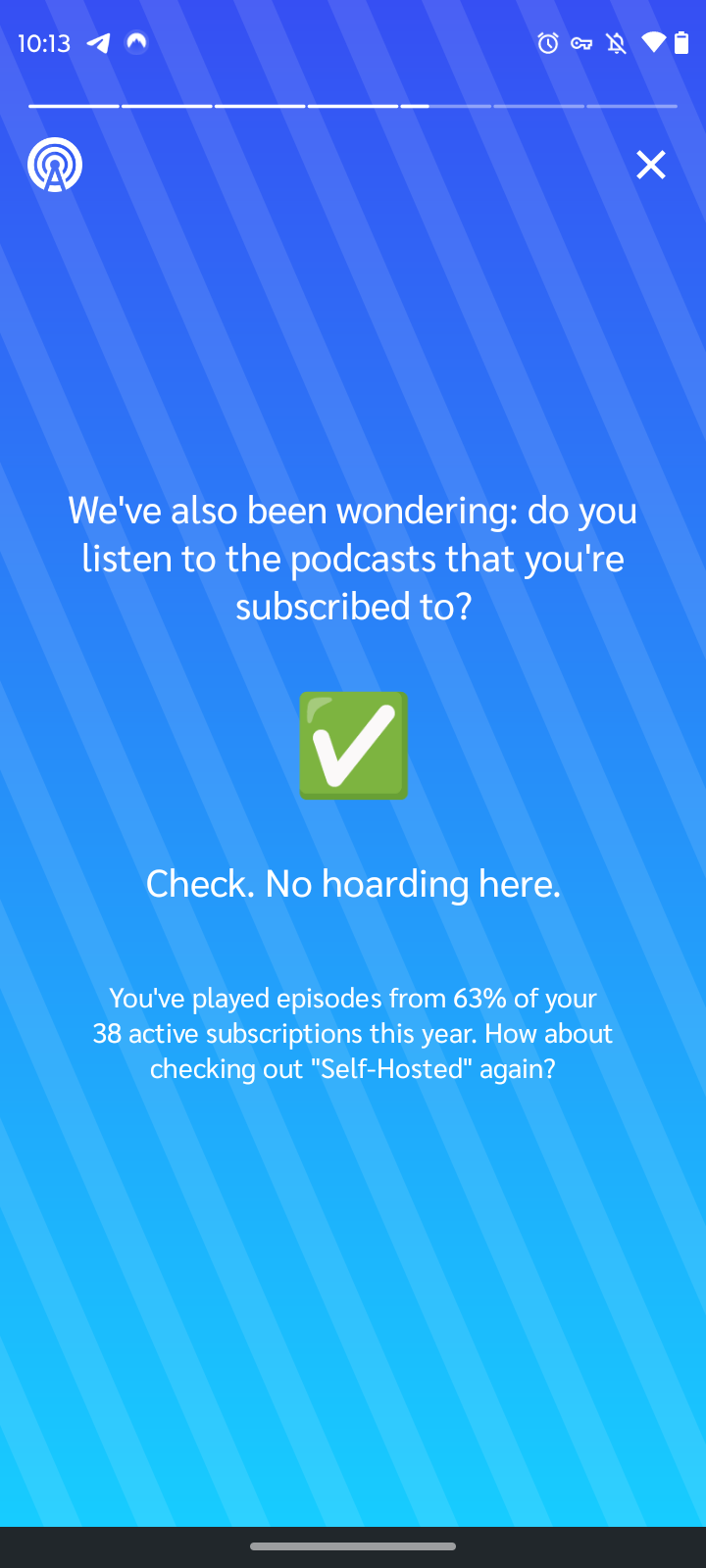
I stumbled upon theunderground blog by Chris McLeod which is an interesting twist on RSS Club. Currently theunderground has a page that serves as the homepage and the RSS feed itself. I wonder whether it's possible to take it even further by using XSL(T) to style the RSS feed as shown in this Style Your RSS Feed post by Darek Kay. By styling the RSS feed, it can serve as the homepage as well. Using redirection, when people land on your domain, they would instead be presented with the styled RSS feed.

Obligatory yearly website update post. When I built this website, I started on .NET 5. 3 years later and although my code has changed to add new features, I haven't had to make any code changes to account for a new version of .NET. I love that I can get all the benefits of the new version without having to do any rewrites.
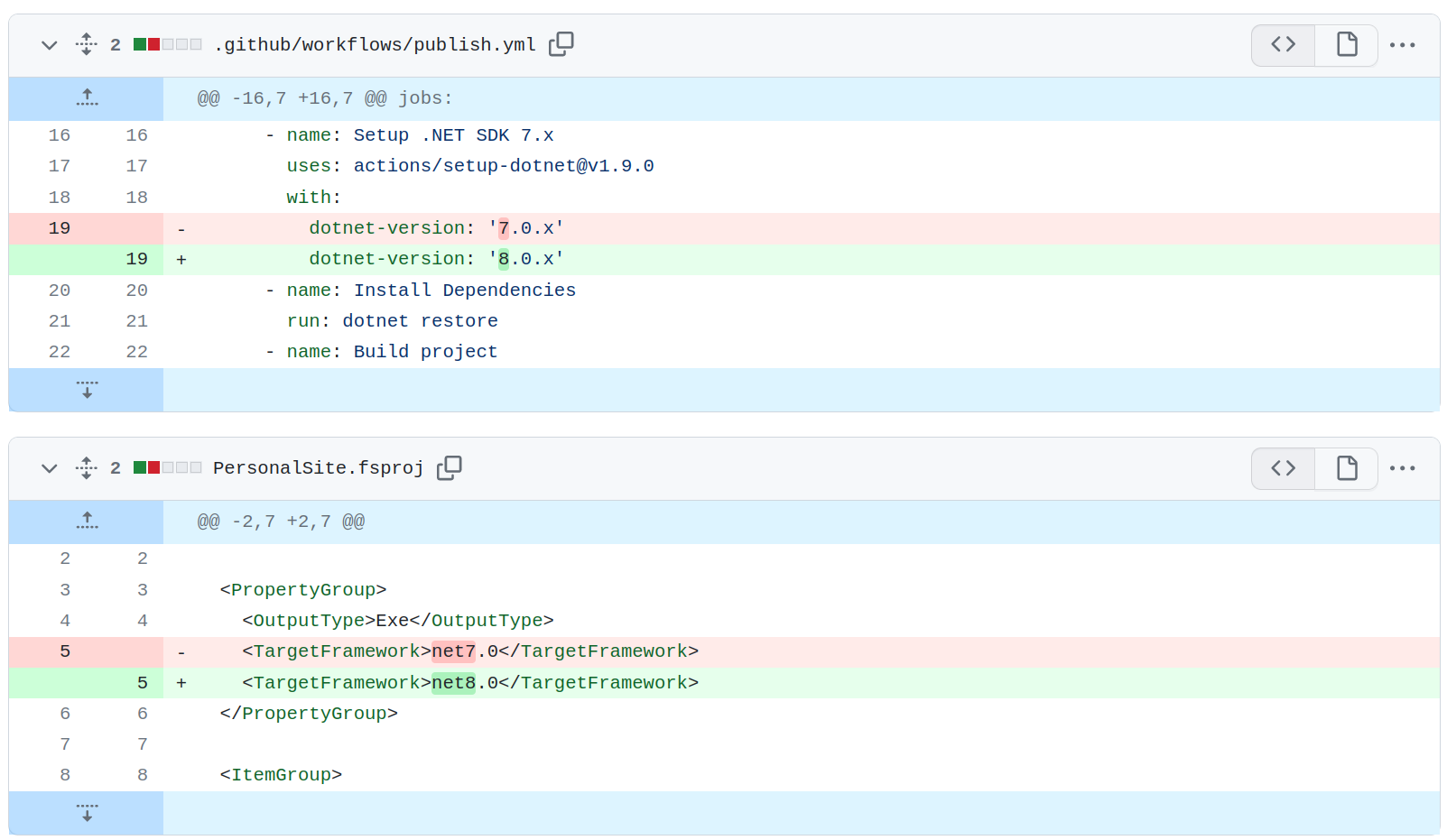
Following up on the theme of cycles and looking back at things from yesteryear explored in my post AI abundance after scarcity cycles, I came across another example.
While looking through some of my old books, I came across Stephen Covey's "7 Habits of Highly Effective People". I remember reading it over ten years ago. At the time, the habits and themes explored in the book had an impact on me. However, since that time I haven't looked at the book again. Today, I cracked it open and skimmed through the foreword. In it, Stephen talks about common human challenges such as:
- Fear and insecurity - This could mean a fear of the future, like losing your job.
- Lack of life balance - Put in the context of being always online, our lives continue to get more complex and demanding.
Given recent talking points of AI coming for our jobs and the accelerated rate of technological innovation, you could pluck these challenges from the time they were written and they'd still be relevant today. You could also place them 500 or 1000 years ago and they'd also be relevant which made me think of the Lindy Effect. In short, it states that the longer a technology or idea continues to live, the higher the likelihood it will continue to exist into the future.
I found it funny though that while flipping through the book and reading about these timeless challenges and principles, I came across the opposite of that. One of my bookmarks was a Borders membership card. If you don't know or remember what Borders was, in a gist, it was one of the large bookstores which succumbed to disruption from e-commerce (i.e. Amazon)

While writing the post RSS for new event notifications I mentioned how the flow of getting new event notifications through RSS might work:
When a new event is added to the calendar, the RSS feed can be updated. The
channelproperty has the link to the shared calendar you can subscribe to and the individual events have .ics files embedded in theenclosure.
I actually didn't know if that was possible until I looked at the RSS enclosure syntax. Based on that page, as long as you provide the URL to the .ics file, length of the file, and the MIME type (text/calendar), you can link to your events inside enclosures. So it is possible.
That's not the point of this post though. When I was looking at the references, I came across this post talking about the use case for RSS enclosures. I don't know when this post was published but given the problems mentioned with accessing high quality video, I assume it was in the days when the internet was on dial-up or DSL speeds. At that time, downloading webpages or e-mail was slow. Forget about downloading multimedia. As that post mentions, with enclosures, you could schedule your RSS client to download content like videos during off-peak hours so any content you'd want to access would download overnight and be available to you in the morning. About 30 years later, in many places, even with a connection that has 1MB download speeds, downloading a podcast that's 100MB or a video that's 2GB is relatively fast. It might take a while, but compared to 30 years ago, it's "instant". So at this point, it's not really technical challenge as much as it is an access challenge.
Low bandwith speeds forced people to get creative in how they utilized their resources. The internet was not the only time this happened. About 30 years ago or so when cell phones were just becoming mainstream they too suffered from scarcity. Cell phones and plans were very expensive. You had limited minutes and when SMS became a thing, those too were limited. If you wanted to have hour long conversations with friends and loved ones, you'd have to wait until off-peak hours so you could use your "free" minutes. Fast-forward 30 years later, cell phones and cell phone plans are relatively affordable. When you purchase these plans, you get access to unlimited minutes, messages, and data. So again, the technical limitations aren't as prevalent. It's mainly a matter of access and whether your cell phone provider offers good coverage in your area.
This brings me to my point. We're seeing this cycle again with AI. Large Language Models today are expensive to run and I'm not overindexing on the financial perspective. You pay per call, access to these models can be throttled at times, there's only so many GPUs you can get access to in a data center to run them, you pay the latency penalty by going through the network as well as the cost of inferencing, and you also have token limits. About a year into the release of ChatGPT, access to these models has been expanded, the models have gotten more capable (GPT-4V and GPT4 with 128k tokens), it's become cheaper to run these models. At the same time, computing is becoming more efficient and smaller "open-source" models are becoming more capable. Today, we have to be creative with how we utilize our resources, but we're only a year in. If we extrapolate how these cycles play out though, in 30 years we'll forget how challenging it was to use and access early AI technologies and AI will become more abundant like the internet, cell phones, and other technologies before it.
After my post on Shared calendars and RSS I kept thinking about what else you can get out of sharing a calendar using RSS. What I didn't see immediately is the main use case of RSS, though I did mention it as a drawback.
The main drawbacks I see are that I can't get notifications or see it in my calendar.
Actually, with RSS, I can get notifications when a new event has been added to the calendar. With iCal for example, when a new event is added to the calendar, it'll automatically be populated in my calendar client. However, I won't get a notification that a new event has been added. Conversely, with RSS, I won't see it in my calendar client but I will get a notification in my RSS reader.
When paired together though you could use RSS to get notified when a new event is added to the calendar and also be able to view it in your calendar client since it'll automatically be populated (assuming you're already subscribed to the shared calendar). That means managing two feeds, but the more I think about it, the RSS format makes some sense. The shared calendar could be the source of truth. When a new event is added to the calendar, the RSS feed can be updated. The channelproperty has the link to the shared calendar you can subscribe to and the individual events have .ics files embedded in the enclosure. As a consumer, the new event notification will then appear in my RSS reader.
I just came across a new use for RSS - shared calendars. Well, not exactly sharing calendars in RSS format. While I have seen calendars in RSS format as I'll mention later in this post, I think there's enough downsides that make this impractical. However, for discoverability, there's some RSS patterns that shared calendars could benefit from.
While reading a recent post on Doc Searls' blog it got me thinking about using public calendars for sharing community events. By leveraging iCal or CalDav, this could be a good alternative to current solutions like Facebook Events or Meetup. It could also be a great way to foster interoperability. There's still the discoverability problem, but platforms like Meetup and Facebook Events could enable subscribing to shared public calendars.
This sent me down a search to see whether others were using shared calendars, similar to The Big Calendar. It was nice to see that Penn State has shared calendars for their various sports. That shouldn't be surprising. As a university, they already share their academic calendars. The part that I found surprising though was that RSS was one of the options.
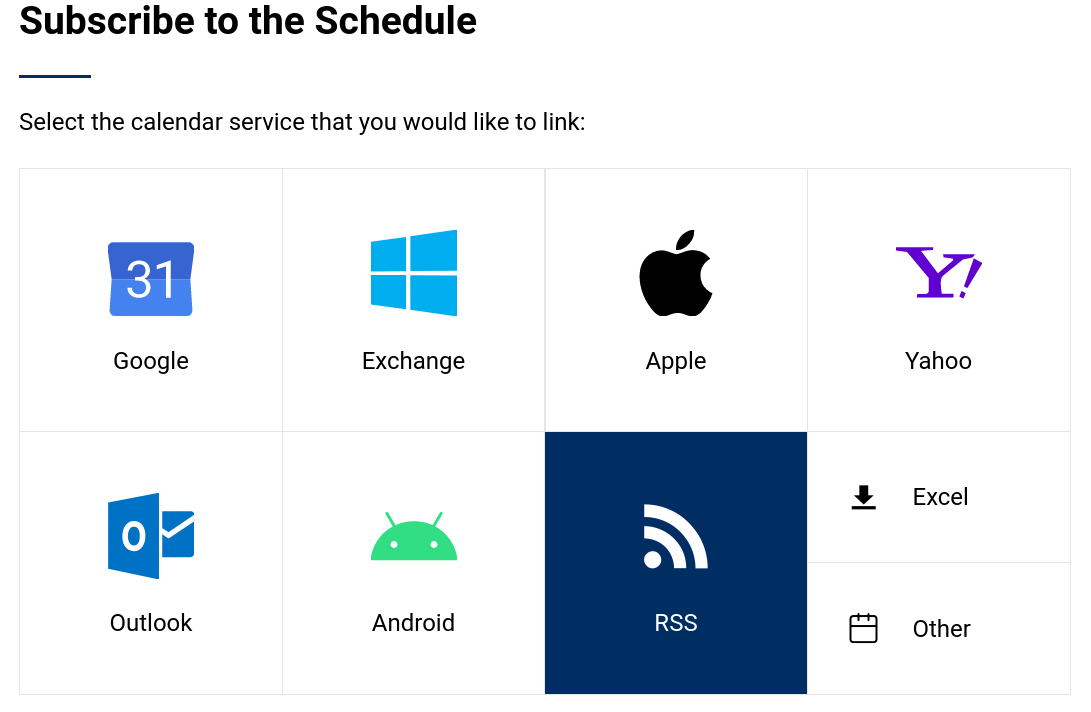
Downloading the RSS feed enabled me to import it into my feed reader and view it there. I'd prefer if instead of downloading the RSS feed as a file, they just provided the link so I could copy and paste it into my feed reader. However, it's still nice that just like podcasts and YouTube feeds, I can now also see Penn State athletic events in my feed.
I'm not sure what the benefit of subscribing to this feed via RSS as opposed to the calendar itself has. The main drawbacks I see are that I can't get notifications or see it in my calendar. I also don't know if changes and updates to events also propagate to the RSS feed. That's why I'd prefer to just subscribe to the calendar directly.
Going back to the broader topic of shared calendars and discoverability mentioned in the DataPress proposal for community calendars, you could imagine a solution similar to how websites can make their RSS feeds discoverable. As a calendar and community maintainer, you could post the link to your shared calendars on your website. As a community member, you'd just need to point your calendar client to the respective website's domain (i.e. gopsusports.com) and your client would automatically import the shared calendars. This is how shared calendars work today. The difference is, you don't need the exact link to the calendar, you just need the website domain. The calendar client is what handles the discovery and import process.
One important thing to highlight, doing something like this isn't exclusive to communities. You could imagine businesses being able to implement similar practices to communicate their business hours and availability. Platforms like Yelp or Google could then just import the public calendar for that business and display the business hours on their platform. To schedule your next oil change, imagine looking at your auto service shop's shared calendar and sending a calendar invite for one of their open slots. This is no different to solutions like Microsoft Bookings. The difference is, instead of using these platforms, you would do it from your preferred calendar client of choice.
You could also see this working for individuals as well. If you need to coordinate something with other people, instead of the constant back and forth to find availability, you can just share your public calendar and they can find a time that works for them.
Anyway, the point of this longish post is that by building on simple components like calendars, iCal, CalDAV, and RSS, communities, businesses, and individuals could communicate and collaborate more effectively without being constrained to any single platform.
Apple unveiled their M3 family of chips and new devices.
First off, The Verge always does a great job covering and condensing these events into a short video.

My initial impressions of the anouncement, this is why Apple wins.
I'm excited by the Snapdragon announcement last week. However, as I mentioned in my post, "the biggest miss from Qualcomm and Windows partners today was not having a lineup of devices ready for purchase".
That wasn't the case for Apple. Not only did they announce their new chips but they also announced devices which will be available as late as the end of November.
I understand Apple owns the entire process so they can align their chip and device announcements. However, Qualcomm brought out many partners on stage. Unless I missed it, I don't remember seeing any PC announcements that would be ready for purchase within the next 2-3 months.
Yesterday I wrote a post with some quick thoughts on why I'm excited for the new Snapdragon X Elite set of chips.
There's something I missed which came to mind this morning.
If your Snapdragon X Elite powered computer is running Windows, and it also has calling and messaging capabilities like a phone, does that mean that you're now the proud owner of a "Windows Phone"? As a fan of Windows Phone, that sounds interesting.
Now you might say, "Windows doesn't have all my apps". Fair point but with Windows Subsystem for Android (WSA), maybe the app gap isn't much of a concern. More importantly, as I mentioned in the post, if the apps no longer become the main mode of interaction and instead are relegated to serve as background services to the AI interface, does it even matter?
In the post, I also mentioned how I'd prefer my mobile computer runs Linux (and no, I don't mean AOSP). Even that is not a strict limitation, since I can run Windows Subsystem for Linux (WSL) inside Windows. So technically I can still have Linux on my mobile computer even if it's running Windows.
Let's see if 2024 becomes the Year of the Windows (or Linux) Phone.
Good thing I'd upgraded to 4.1.7 just a few weeks ago, so getting to 4.2.0 was relatively easy. The wiki where I'm tracking updates makes it easy to quickly remember the general process. I haven't tried all of the new features, but it's nice to see there's a new onboarding flow to the Web UI which should make it easier to get started for new folks.
I didn't inspect the changelog between 4.1.0 and 4.1.7 in great detail, but the latest stable version feels snappy.
College football is back!
Penn State had a great win. Looking back at a post from last year, some of my thoughts around the upcoming class were right. Looking at the upcoming schedule it looks well spaced out and if they can stay healthy, they'll have a great season.
Tough losses for LSU and Clemson.
This year I'm trying a new way to experience games: blogs + audio streams.
This past week, although I tuned into the games, I didn't watch any of them on TV. Instead, I tuned into the live audio streams on The Varsity Network and for live discusson, I tuned into the various team blogs / communities provided by SBNation (fun fact: I learned SB stands for Sports Blogs). For example, Black Shoe Diaries, the Penn State blog, had a live thread for each of the quarters where site writers and fans got to interact in real-time. Other team blogs had similar threads.
Overall, I thought it was a fun experience, and I'm most likely going to do it again this week.
Games I'm most looking forward to Week 2:
- Stanford vs USC
- Temple vs Rutgers
- Texas vs Alabama

I really need to automate my website updates. I had forgotten to update the "checkmark" (for lack of better words) for the month of July. Usually, I try to have an icon show up as my "blue check" (Twitter inspired) that is relevant for each month. July is Roswell month mostly because I think I already used the sun emoji for one of the other summer months. I guess being in the US, the US flag would've made sense here, but somehow aliens seemed more fun. Anyway, I need to find a good way to automate this so it's not one of those things that happen when I remember. Since I just changed to the alien emoji, it means I probably will only have it up for a week. August is Tux month because of Linux (again, sun and aliens were already taken). Recommendations are appreciated. Though I'm excited for spooky season in September & October.
Time to distro hop. Maybe. For the past two years I've been happily using Manjaro as my main distribution. During that time I've also kept an eye on the immutable distributions. One of the main ones I've been paying attention to is NixOS. Like Arch, it's taken me some time to wrap my head around it. Now that it's gotten easier to set up through a graphical installer, I'll start out with a live install to see how I like it.
I've been thinking about shifting at least some of my communications from e-mails to blogs especially in the context of business communications.
Blogs are pull rather than push, so I'm not innundating other's inboxes. People who are interested in the projects or topics I'm working on can subscribe and consume the content as they wish. Also it's a way to be more expressive since it's a medium where ideas can be connected to provide more relevant context. That doesn't mean chats and even e-mail couldn't be used for urgent communication. For async non-urgent communciation though, blogs might be a good alternative to e-mail.
These two articles provide a good introduction into how individuals and companies have implemented similar practices:
Spent the day playing sysadmin and removed about 50GB worth of data from my Matrix Synapse instance. Like Mastodon, most of that data wasn't even mine. Most of it comes is remote data from other users in large rooms. I really like Matrix and the ability to host my own messaging server that provides end-to-end encryption as well as federation with other instances. However, not having a straight-forward way of managing my server and cleaning up resources is painful.
Anyway, if anyone is interested, here are some resources that have helped me in this process.
Matrix Synapse Server Administration
I'm really liking my new phone wallpaper. Courtesy of DALL-E.

In case anyone is interested in the prompt - "pug in the utah desert on mushrooms opening his third eye and being beamed up by aliens"
While flipping through a local (physical) newspaper, I came across an ad for a sale happening at a nearby record store.

Having nothing planned, I decided to check it out and ended up with a nice haul of about 15 CDs and 2 DVDs.

I fired up my portable CD/DVD drive to transfer my new purchases to my portable MP3 player.
Once finished, I popped one of the DVDs into the drive, made popcorn, and settled in. If I didn't know any better, this could easily be a scene from 2006.
Although titles are optional for RSS feed items and it's a common practice for microblog platforms like Mastodon to exclude them, it unfortunately means some clients like Elfeed don't know how to render those posts.
Mastodon v4.1.0 was released yesterday. This was a highly anticipated release for me since it introduced the option to remove old cached profile media which was taking up a significant portion of my disk space.
After upgrading, I was able to cut my used disk space in half.
If you're running your own instance or have the ability to contact your instance admin, I can't recommend upgrading to this version enough.
Testing untagged notes which is the same as notes with less than three tags
Testing whether notes appear with title
As the feedback post suggests, Skype offers the option to have encrypted conversations (chat & calls) using the Signal protocol. However, it's not the detault. If you're using Skype and this is something you'd like added, feel free to upvote the feedback request.
https://feedbackportal.microsoft.com/feedback/idea/0b770e9e-bca0-ed11-a81b-002248519701
Testing whether my site can handle embedding Microsoft Forms. Useful for polls across a variety of channels.
Nice! i3-gaps was recently merged into the main i3 codebase some time ago and with the 4.22 release a few weeks ago, you can now use it with your existing i3 configuration. I've started tinkering with it and I like the way it makes my desktop look.
Just created a new .NET page on the IndieWeb Wiki. If your personal website or blog is using .NET, feel free to add it there. Also, if you're building any services or libraries for the IndieWeb, add them as well.
Looking to learn more about IndieWeb? https://indiewebify.me/ or the IndieWeb Wiki are great places to get started.
The next version of Mastodon can't come soon enough.
About 20GB of disk space on my instance are being taken up by media from remote users. And this is for a single user instance! I can't imagine how it must be on other instances with multiple accounts.
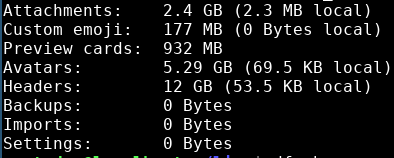
A recent PR should make things much better though by allowing you to remove these files.
The only thing you need to do is pass the --prune-profiles flag to the media remove CLI command.
The PR is already merged so hopefully that means it's coming the next release.
Upgrading my server to 4.0.2 wasn't bad, especially considering I was coming from a 3.x version. Also posting this to make sure that there have been no changes to the API and my website can still post to Mastodon on my behalf.
I wasn't really planning on this, but here we are. I've been using Neofetch on my PC to display system information whenever the terminal opens. However, in some cases, that would hang and it would take a while before I was able to use my terminal.
I then ran into Nitch which is simple and fast. However, it was missing the local and public IP information Neofetch provides out of the box. Nitch is written using the Nim programming language. Originally, I had planned on extending Nitch and I figured out the code I needed to write to support IP information. However, my program wouldn't build and I was unable to find any information online to unblock myself.
That's when I looked at the existing components in Nitch and found that it was basically just reading files from the /proc and /etc system directories. At that point, I decided to see if I could build my own utility using F#. A couple of hours later and the result was Fitch. This works well enough for my needs and in the future, I might publish it as a dotnet global tool to make it easy for others to use.
Well, that's time that I'm never going to get back.
Imagine that you wanted to redirect a URL,
From: https://mydomain/github/repo-name
To: https://github.com/username/repo-name
You could use regular expressions to parse out the repo-name part of the URL path from the source URL to the destination URL. This is what it might look like using something like NGINX.
location ~ ^/github/(.*) {
return 307 https://github.com/yourGHusername/$1;
}
Unless I wasn't looking at the right documentation, it's not obvious that the rules engine for most Azure CDN plans don't support this feature, except for the Verizon Premium. While the standard rules engine supports wildcards for source URLs, lack of regular expresssions support means there's no way to parameterize the values of the destination URL. If this is something you need, make sure to use the Verizon Premium plan.
It took me a while to get all the pieces working but I'm excited that my website now accepts webmentions!
A few months ago I implemented sending webmentions.
Accepting them was a bit tricky because there were a few design decisions I was optimizing for.
In the meantime, you can check out WebmentionFs, an F# library I built for validating and receiving webmentions along with the WebmentionService Azure Functions backend that I'm using to process webmentions for my website.
Also, feel free to send me a webmention. Here's my endpoint for now https://lqdevwebmentions.azurewebsites.net/api/inbox. Check out this blog post where I show how you can send webmentions using F#. You can use any HTTP Client of your choosing to send an HTTP POST request to that endpoint with the body containing a link to one of my articles (target) and the link to your post (source).
Stay tuned for a more detailed post coming on December 21st!
Today I learned about Firefox Task Manager. Typing about:performance into the address bar brings up the task manager which lets you inspect the tabs and extensions consuming the most energy and resources.
I've never had a blue checkmark on Twitter so I can't say what that process is like. Looking at it from the outside though it seems the process isn't simple or straightforward. My experience with verification has been with other applications such as Mastodon and IndieAuth. In both of these cases, the main verification techniques use your domain and/or the rel=me link type. Although with Mastodon you can add multiple verified links to your profile, verification on those external domains pose challenges which include but are not limited to:
- You can't edit the HTML directly so you can't add a
rel=melink. - You can only add one link, so you're forced to choose between your website and Mastodon.
- In scenarios where multiple links (i.e. e-mail, webpage, Twitter) are supported, Mastodon isn't one of the options
So how do you overcome these challenges? By using your domain.
A few months ago I wrote about owning your links. The general concept of owning your links is, using your domain to redirect to other properties and profiles you own. For example, instead of telling people to visit my Twitter profile at twitter.com/ljquintanilla, I can instead point them to lqdev.me/twitter. Not only does my domain become the source of truth, but in general it's easier to remember compared to usernames and proprietary domains. Since my site is statically generated, I own my links by using http-equiv meta tags. Although the only job for these pages is to redirect to the specified site, in the end they are still HTML pages. This means, I can embed any other HTML I want, including rel=me links. By including the rel=me link in the redirect page, you satisfy the requirements of applications like Mastodon because that's the page they'll land on before being redirected to the target site. As a result, I can verify my GitHub, Twitter, or any other online property I want with Mastodon using my own domain without having to make any changes or overcome any of the challenges imposed by those other platforms. What you end up with is something like this:
Before signing off, I'll note that this isn't a perfect solution and technically anyone could do the same thing on their own domain in an attempt to impersonate you, so just be aware of that.
Soon after .NET 7 was released, I upgraded the static site generator I use as well as the GitHub Actions that build and publish my website. Having upgraded last year from .NET 6, the process was as smooth as I had expected with no code refactoring required.
When it comes to development environments, for quick status updates like the ones on my feed or minor edits, I've been using github.dev. However, there's been times where I've needed to run and debug code to confirm that my changes work. This is where I hit some of the limitation of github.dev which means unless I set up a Codespace, I have to save my work and move offline to my PC. Codespaces are great, but given that Codespaces are nice to haves not a requirement for my workflow at this time, it didn't make sense for me to pay for them. That's why I was excited to learn that GitHub is providing up to 60 hours per month of free Codespace usage to all developers. That's more than enough for me.
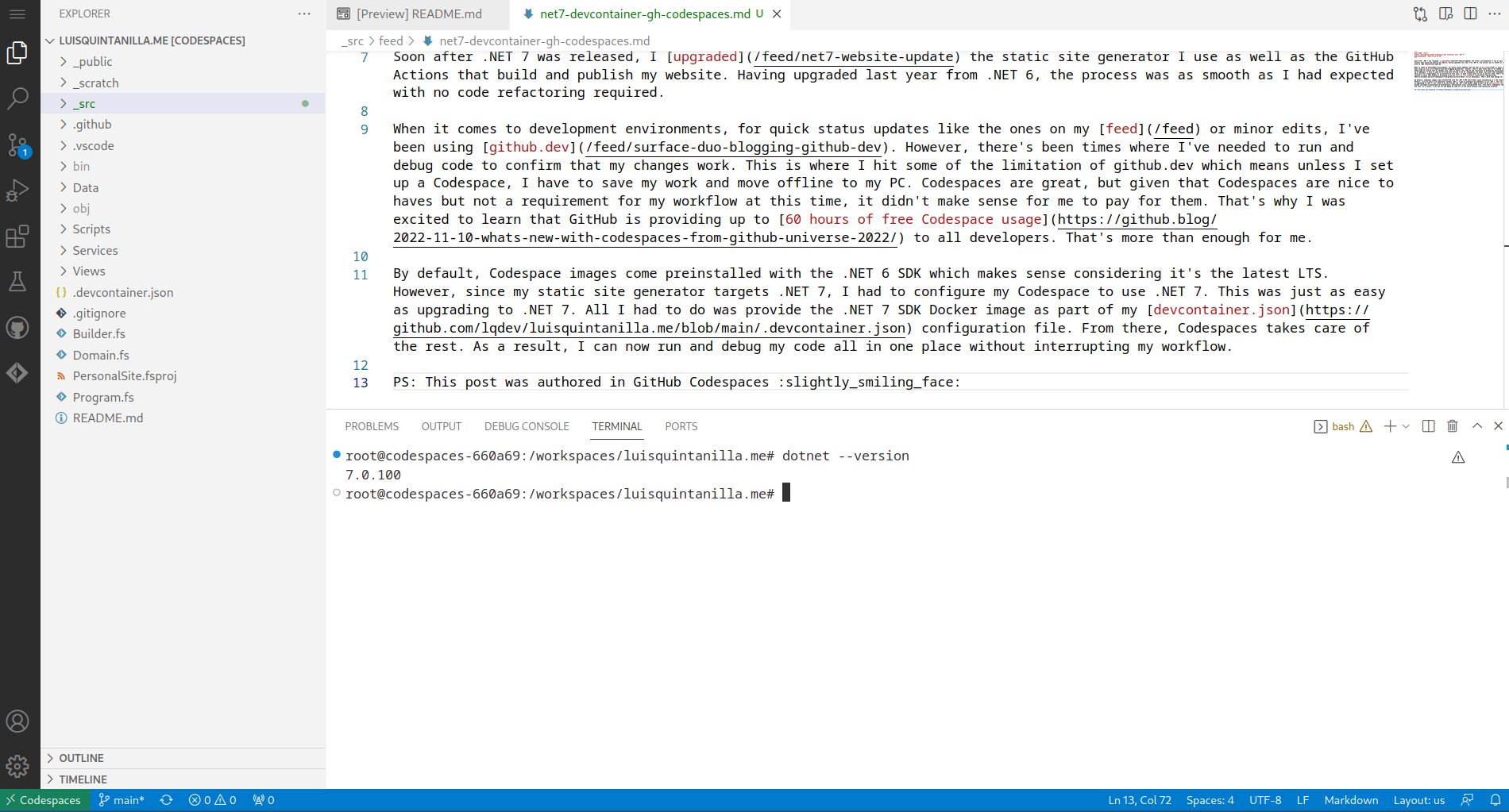
By default, Codespace images come preinstalled with the .NET 6 SDK which makes sense considering it's the latest LTS. However, since my static site generator targets .NET 7, I had to configure my Codespace to use .NET 7. This was just as easy as upgrading to .NET 7. All I had to do was provide the .NET 7 SDK Docker image as part of my devcontainer.json configuration file. From there, Codespaces takes care of the rest. As a result, I can now run and debug my code all in one place without interrupting my workflow.
PS: This post was authored in GitHub Codespaces 🙂
It's been great to see many old and new friends joining Mastodon and considering alternatives to online communities over the past few weeks. Selfishly my feed had been quiet since I started using it and self-hosting back in 2018 so it's nice to see more activity. As folks have started to settle in and get a better understanding of Mastodon, I'd like to point out that Mastodon is only one of many apps and services on the Fediverse. Now I won't try to explain the Fediverse but in general, it's the collection of applications and services that interoperate in a federated manner, Mastodon being one of them. If in general you like Mastodon and are looking for alternatives to services like Instagram, YouTube, SoundCloud, the Fediverse has a few options:
You can create an account for each of these services using different instances, just like Mastodon. You also have the option of self-hosting which I find amazing. However, because for the most part these services implement the ActivityPub protocol, it means federation extends beyond Mastodon. You can follow people on PixelFed, PeerTube, and many of these other services using your Mastodon account which means you don't have to create accounts for those services just to follow people. While I don't have experience with all of these services, I recommend checking them out. I especially like what Pixelfed, PeerTube and Owncast are doing but those are the main ones I have experience with.
Last year, I posted about upgrading this website to .NET 6 and how easy that process was. I just had a chance to upgrade to .NET 7 and the experience was just as smooth. All I had to do was change the version in two places:
GitHub Actions *.yml file
dotnet-version: '7.0.x'
*.fsproj file
<TargetFramework>net7.0</TargetFramework>
I'm happy that with such a simple change, I can get all the benefits of .NET 7 without doing a lot of work.
Slow start but good bounce back by Penn State after two straight losses. This game also gave a good glimpse of the future class and it looks promising especially at the QB and RB spots. If they can stay healthy, they may be playoff contenders in a couple of years.
11:58
Hoping for a good game.

12:22
Defense is clutch. As always in big games, they'll have to work overtime just to keep the offense in the game.
12:42
Progress...at least there was no turnover on the last series.
12:59

13:16

14:53

15:09
Going for it on 4th & 2 feels like that 4th & 5 from a few years ago.
15:30
Defense showed up today. Can't expect to win a game with 3 turnovers.

15:33
This is hard to watch.

I can probably count the number of times I've used the Azure Cloud Shell inside the Azure Portal with one hand. However, I recently had a need to use it and was impressed by the experience.
I wanted to create an Azure Function app but didn't want to install all the tools required. Currently I'm running Manjaro on an ASUS L210MA. That's my daily driver and although the specs are incredibly low I like the portability. The Azure set of tools run on Linux but are easier to install on Debian distributions. The low specs plus the Arch distro didn't make me want to go through the process of installing the Azure tools locally for a throwaway app.
That's when I thought about using Azure Cloud Shell. Setup was relatively quick and easy. It was also great to see the latest version of .NET, Azure Functions Core Tools, and Azure CLI were already installed. Even Git was already there. After creating the function app, I was able to make some light edits using the built-in Monaco editor. When I was ready to test the app, I was able to open up a port, create a proxy, and test the function locally. It's not a high-end machine so I won't be training machine learning models on it anytime soon. However, for experimentation and working with my Azure account it's more than I need.
Last I heard of Tumblr, they were owned by Verizon. While readying the book Indie Microblogging by Manton Reece, I learned (and later confirmed) they were owned by Automaticc, the company behind WordPress. Out of the the different homes it's had, I can't think of a better place for it.

Finally got a working prototype. A few days ago I added the request and webmention verification components.
I just finished creating the web API and Azure Table Storage components. Now I just need to run some additional tests and deploy it 🙂

It's been a year since I created this feed and started posting mainly on my website. Since then, I've:
- Used a shorter domain to redirect to my website domain.
- Created VS Code snippets to simplify metadata tagging.
- Used github.dev as the main interface for authoring and editing posts. For longer posts, I use VS Code locally but for these smaller microblog-style posts, github.dev makes it really easy.
- Syndicated posts to Twitter and Mastodon.
- Created a response feed for interactions like replies, reshares (repost), and likes (favorites) with support for sending Webmentions.
- Created RSS feeds for each of my feeds.
It hasn't happened overnight. Instead, it's been the result of small incremental efforts over time.
Overall, I don't think I've posted any more or less than I do on other platforms.
What I have enjoyed the most though has been:
- Learning.
- Building the tools and processes to author and share content.
- Owning my content. My website acts as the single source of truth.
- Not requiring others to have or create accounts on individual platforms to access content.
- Choosing how I author content. I'm sure this post is way over the 280 character limit and if there's a typo, I can just edit the post and republish the website 🙂
Going forward, I plan to:
- Update RSS feeds to include post content, not just link to the post.
- Accept Webmentions. I'm about halfway done with the main parts of my implementation.
- Implement tags for easier discoverability / search.
- Consolidate metadata for posts (articles, microblogs, responses).
Success! I just partially implemented Webmentions for my website. Although I haven't figured out a good way to receive Webmentions yet, I'm able to send them. Fortunately most of the work was done, as detailed in the post Sending Webmentions with F#. The rest was mainly a matter of adapting it to my static site generator.
Below is an example of a post on my website being displayed in the Webmention test suite website.
Source
Target

What does this mean? It means I can comment on any website I want, regardless of whether they allow comments or not. As if that weren't enough, I have full ownership of my content as my website is the single source of truth. As a bonus, if the website I comment on supports receiving Webmentions, my post will be displayed on their website / articles as a comment. The next step is to handle deleted comments, but so far I'm happy with the progress.
Very cool!

Same... 🙏
Praying on Ohio State's downfall
— Barstool Penn State (@PSUBarstool) September 3, 2022
Source: https://twitter.com/PSUBarstool/status/1566230451378950144
Today I Learned about the VS Code Live Preview extension. While reading the release notes for the latest version of VS Code, I noticed a note on the Live Preview extension. Usually to preview static content, I use Python's HTTP server with the python -m http.server command. This extension simplifies the process because it's built into Visual Studio Code. If you do any kind of web development, it's definitely worth a look.
College football is definitely back. I don't miss those 4th quarter heart attacks, but a win is a win.
Very cool! QRZ just announced the New Ham Jumpstart Program, a new program to make it easier for new ham radio operators to quickly get on the air.
Things are heating up in the AI generative model space. OpenAI just announced Outpainting. A few days ago, Stability.ai released Stable Diffusion and recently a painting generated using Midjourney won first place in the digital category of the Colorado State Fair fine art competition.
I know what I'm doing October 6th.


Can't believe I hadn't heard about these podcasts before:
Love the horror anthology vibes like Tales From The Crypt and Freakshow for Radio Rental. For Dark Air, I really like the Space Ghost Coast to Coast and actual Coast to Coast feel. Best of all, the host Terry Carnation is Rainn Wilson. Even Terry's website has a great 90's web feel to it. Looks like Dark Air has been off the air for some time, but hopefully Radio Rental keeps publishing content.
Apple just announced they're discontinuing the iPod Touch. I'm surprised it hadn't happened earlier! Still, it's sad to see the end of an era for these devices which are effectively smartphones without the phone / cellular data connectivity. I still have my iPod Touch from 2014 that I use occasionally for FaceTime which aside from poor battery life and being stuck on an older version of iOS, it still works smoothly.
For the past two years, my audio solution has been a dedicated MP3 device. Since most of the content I consume I download and listen to offline, a dedicated MP3 device doesn't drain my phone's battery or take up storage space.
I started with the FiiO M5, which is like an iPod Shuffle. The device was great, but all it took was one drop for the screen to crack at which point I upgraded to the FiiO M6. The nice thing about the M6 is that the OS is a stripped down version of Android meaning you can side-load applications such as Spotify. The bad thing, the hardware can't handle (even heavily optimized versions) of these applications making the user experience frustrating. The touchscreen interface is great for navigation especially when you have large collections. However, since I only use the device for podcasts and audiobooks and don't get the benefits of installing streaming music apps, I'd be better off with a more affordable device like those from SanDisk.
It's been a little over a year since I started hosting my website on Azure. The resources I use include:
- Azure Storage: Where all my site assets are stored.
- Azure CDN: Content delivery
- Azure Logic Apps: Event-based jobs to syndicate new posts on Twitter and Mastodon.
I haven't tracked traffic for the entire year but since October of last year the site has gotten roughly 5,000 visitors.
Taking all that into account, I've only had to pay $2.06 most of it being the storage I use for the site. In comparison, I was previously hosting my website through my domain provider in a shared server where it cost about $60!

If you're interested in how this site is built, check out the colophon.

Twitter is testing a new feature called Twitter Circles where you can restrict the reach of your tweets to up to 150 people. I remember the days of MySpace where many relationships were made / broken as a result of being in someone's Top 8 Friends list 😆
Hello Mastodon from lqdev.me. Got POSSE (Publish (on your) Own Site, Syndicate Elsewhere) working for Mastodon! I already had an Azure Logic App which took the latest post from my RSS feed and published to Twitter. Now it's also enabled for Mastodon. Might do a writeup later in the blog on how to do it.
Yesterday I ran into more feed goodness. When going to a website to get the weather forecast, weather alerts are displayed (if there are any).
I thought, wouldn't it be great to be able to subscribe to those alerts without having to go to the website?
A quick search revealed the National Weather Service provides these alerts in ATOM format for each of the states in the U.S. You have the option of tracking updates at the national, state, zone, and county level.
Subscribing is as easy as adding the link for the respective feed to your favorite feed reader. If you're interested, you can find the list of feeds at https://alerts.weather.gov/
In light of recent developments on Twitter, I see more people looking for alternative platforms. Personally, I don't think anything beats the level of customization and control you get from using your own website and RSS for sharing ideas and publishing content. However, it's great to see so many new friends in the Fediverse on platforms like Mastodon. I won't go into what the Fediverse is but you can check out the Fediverse wiki for more info. In many ways the Fediverse will feel familiar, yet foreign. Many people have shared tips on getting started, but I'll share some of the ones I've personally used to organically curate my feed.
- Use hashtags. Similar to Twitter, hashtags are a good way of finding people and content related to the topic of interest.
- Follow feditips and FediFollows. As the names suggest, they provide good tips and suggest interesting accounts to follow in the Fediverse.
As an alternative if you're not ready to create an account, you can use RSS. I'm a big fan of RSS. Appending .rss to any account on platforms like Mastodon (for example https://mastodon.online/@FediFollows.rss) provides you with the RSS feed of an account's posts letting you subscribe to their content through your favorite RSS feed reader.
Feel free to say hi at toot.lqdev.tech/@lqdev. See you in the Fediverse!
Here's a few links I found in the interwebs today that I thought were worth sharing.
Ubuntu 22.04 LTS Released
For my personal computing needs, Manjaro has been my default Linux distro. However, for hosting and cloud VMs I go back and forth between Debian and Ubuntu depending on which better supports the software I'm running. Canonical announced the release of the latest Ubuntu LTS version 22.04. Check out their blog post for more details on what's new.
Self-hosting Bitwarden on DigitalOcean
When it comes to password managers, other than KeePass, my favorite it Bitwarden. It's open-source, built on .NET, has excellent features that get even better with the low-cost paid version, but most importantly provides you the option of self-hosting. If you're looking to self-host Bitwarden on DigitalOcean, make sure to check out the guide they just published.
How DALLE-2 Actually Works
A few weeks ago, OpenAI announced the release of DALLE-2. Open AI describes DALLE-2 as, "...a new AI system that can create realistic images and art from a description in natural language." If you want to understand the details of how it works, you could read the 27 page research paper Hierarchical Text-Conditional Image Generation with CLIP Latents. AssemblyAI just published an approachable guide into the inner workings of DALLE-2. If you're interested in that, check out their blog post on the topic.
Emacs Configuration Generator
In my early days of using Emacs, I often found it difficult to customize it to my needs. Not only did I not know what was possible, but it also caused some anxiety because I didn't feel confident enough making major tweaks. If you're getting started with Emacs and aren't sure how to configure it, this neat utility helps you generate a config file for Emacs.
PostgresML
If you're building machine learning applications, one of the main things you'll need is data. This data can reside in databases such as MySQL, SQL Server, and Postgres. Algorithms are applied to this data downstream using libraries written in languages like Python, R, and .NET. This not only means potentially moving the data from the database to another process but also using another library to train models. According to the project description on GitHub, "PostgresML is an end-to-end machine learning system. It enables you to train models and make online predictions using only SQL, without your data ever leaving your favorite database." If that's something you're interested in, check out the project on GitHub.
About 2 episodes into the show Archive 81 on Netflix and so far so good. I listened to a few episodes of the podcast (by the same name) it's based on a few years ago. Now it makes me want to go back and listen to it again. It also makes me think about what the Black Tapes could've been had it gotten a TV or movie adaptation. If you're into the found footage, cult horror type of stories (think Blair Witch + Midsommar + Rosemary's Baby), definitely check it out.
Vertigo is one of my all time favorite movies, so I was excited to learn about Vertigo AI. Vertigo AI is an experiment that trained a model on footage from the film Vertigo to produce its own original short film. There aren't many details on the AI aspects of it, but I suspect there's a Generative Adversarial Network (GAN) similar to Norman behind it. Check out the generated movie.

That was easy. Site's been updated to .NET 6 and all it took was a one-line change.

I got a reminder on the importance of backups last night. New Jami username is lqdev1. Fortunately I wasn't as active on there so not a big deal to lose my original username.
I recently came accross the Terms of Service, Didn't Read (TOSDR) website. Like most people, I'm guilty of clicking "I have read and agree to the terms of service" without actually doing so. TOSDR simplifies terms of service documents by highlighting the main points for many popular services. I'm not sure how maintenance and the frequency of that maintenance work. There's a rating systems which I also am not sure how it works. However, you are provided with the documents that were used to come up with the ratings and summaries, so you can look into it yourself. Overall, I think it's an incredibly useful tool to make sense of how your data is managed across these platforms.

Found these while cleaning out some drawers 😢. Good times.

I've written before about how versatile the RSS protocol is for publishing and consuming content. Podcasts are one of the many media types that largely rely on RSS, making it easy to subscribe and manage using an RSS client of your choice. Like RSS, VLC is versatile in the type of media it can play. When you combine the two, you're able to stay updated on the latest episodes from your favorite podcasts using the RSS reader of your choice and use the episode's URL to stream the audio in VLC.

Lately I've been using github.dev to author posts and make light edits on this site. One use case where it's come extremely handy has been authoring content, specifically these microblog-like posts from my Surface Duo. Instead of opening the laptop, I can open up my Surface Duo and visit my site's repo through github.dev. When I orient the device in landscape mode I have one screen display the VS Code-like web environment while the other screen displays the keyboard. Snippets, version control, extensions, and themes all carry over making the experience consistent. Committing changes through the version control utilities immediately kicks off the GitHub Action to build and publish the site with the latest changes. Pairing the GitHub online editor environment with the Duo's dual-screen form factor showcases the productivity and convenience both of these products provide.

I've been looking at different alternatives to Google Analytics for website stats. I don't need anything fancy, just basic page counts. Eventually I settled on GoatCounter because it's lightweight, open-source, and privacy-friendly. You can either use their managed service or self-host. Deployment with Docker felt a bit much so I did a standalone deployment to a VM. The Linode StackScript is probably the easiest way to do it.
While browsing the interwebs, I ran into the site United States Early Radio History which contains events spanning different time periods. As an operator it's fascinating to learn about the history and see how radio continues to play a large role in our day-to-day.
While browsing the interwebs I came across the Web Neural Network API spec from the W3C Web Machine Learning Working Group. The abstract defines it as "a dedicated low-level API for neural network inference hardware acceleration.". Although there are already a few frameworks like ONNX & TensorFlow.js that allow you to inference in the browser, this spec looks interesting because it provides an abstraction that allows you to take advantage of hardware acceleration using the framework of your choice. As the explainer document mentions, "this architecture allows JavaScript frameworks to tap into cutting-edge machine learning innovations in the operating system and the hardware platform underneath it without being tied to platform-specific capabilities, bridging the gap between software and hardware through a hardware-agnostic abstraction layer.". It's just a working draft for now but I'm looking forward to how this develops.
The other day I was going down a Wikipedia rabbit hole and learned those click-baity "Top 10 ..." or "Worst 10 ..." articles apparently have a name, listicles. The more you know...
That was easier than I thought. Visiting lqdev.me now redirects to this site. Redirect isn't limited to the main page though. You can also access any other resources as well. For example, visiting lqdev.me/feed would redirect you to the main feed on this site.
Today I learned about canonical URLs. While looking into how I can syndicate content from this site, specifically longer form blog posts on other sites like dev.to, I came across canonical tags.
Basically they're a way of telling the internet, specifically search engines, what version of your content is the main copy or single-source of truth.
Currently I've configured my site so it's not indexed or crawled. However, for sites I don't own I don't have the same level of control. Check out the canonicalization and SEO best practices for canonical URLs articles from Moz if you're interested in learning more.
I have almost zero artistic skills, so when I came across NVIDIA Canvas I was extremely excited!
Essentially it's an application that takes simple brushstrokes as input and uses a Generative Adversarial Network (GAN) to turn them into realistic landscape photos.
I had known about GANs being used to generate faces (see This Person Does Not Exist) but it's one of the first times I've seen them used to enhance drawings.
Time to take my stick figures to the next level!
Came accross this event series via Chris Aldrich's microblog.
Here's Chris' original post
Every Monday, I sit down with a cup of coffee and learn something interesting about history through old manuscripts. Join our friends Dot Porter (@leoba) and the Schoenberg Institute for Manuscript Studies (@sims_mss) at Coffee with a Codex.
Basically it's a virtual meeting where experts go over manuscripts on a variety of topics. I'll probably check out next week's event.
It only took 6 hours but I was able to get it done with a little help.

No Windows 11 upgrade for me. 😥

Just because I can't doesn't mean you can't though. Go and check if you're eligible at Windows Update
Start > Settings > Update & Security > Windows Update.
See Manage updates in Windows for more details.
For alternative install options, check out the Download Windows 11 page.
Just jumping on the bandwagon. A few online services are down at the moment 😬

Not to worry...the personal site is still chugging along 😌
Just read an interesting article publised in Technology Review called Digital gardens let you cultivate your own little bit of the internet.
In a sense, some of the updates to this site like the addition of the different feeds can be thought of as "cultivating" my own digital garden.
I would've been okay with The Many Saints of Newark being a 4 hour movie. I didn't want it to end. Now I have to rewatch The Sopranos.
For personal use, I tend to default to Skype for my video / audio call needs.
Great to see there are some long-term plans for the app and it'll be around for a while more.
The future of Skype: Fast, playful, delightful and buttery smooth
Found this interesting video by Chackram & Riley Thompson. My favorite part starts around the 7:15 mark.
Hello World! First post in the personal feed.