In my experience, the supermajority of engagement on viral AI Facebook pages is just as artificially-generated as the content they publish.
Whether it's a child transforming into a water bottle cyborg, a three-armed flight attendant rescuing Tiger Jesus from a muddy plane crash, or a hybrid human-monkey baby being stung to death by giant hornets, all tend to have copy+pasted captions, reactions & comments which usually make no sense in the observed context.
I've noticed similar patterns on YouTube. Sometime the comments include timestamp links which makes them seem more credible, but upon further inspection, it's all bot activity.
https://orgmode.org/manual/Capture-templates.html
Testing org-capture template generated response file
https://maggieappleton.com/home-cooked-software
The emerging golden age of home-cooked software, barefoot developers, and why the local-first community should help build it
This is a talk I presented Local-first Conference in Berlin, May 2024. It's specifically directed at the local-first community, but its relevant to anyone involved in building software.
For the last ~year I've been keeping a close eye on how language models capabilities meaningfully change the speed, ease, and accessibility of software development. The slightly bold theory I put forward in this talk is that we're on a verge of a golden age of local, home-cooked software and a new kind of developer – what I've called the barefoot developer.
https://huggingface.co/collections/facebook/llm-compiler-667c5b05557fe99a9edd25cb
Large Language Models (LLMs) have demonstrated remarkable capabilities across a variety of software engineering and coding tasks. However, their application in the domain of code and compiler optimization remains underexplored. Training LLMs is resource-intensive, requiring substantial GPU hours and extensive data collection, which can be prohibitive. To address this gap, we introduce Meta Large Language Model Compiler (LLM Compiler), a suite of robust, openly available, pre-trained models specifically designed for code optimization tasks. Built on the foundation of Code Llama, LLM Compiler enhances the understanding of compiler intermediate representations (IRs), assembly language, and optimization techniques. The model has been trained on a vast corpus of 546 billion tokens of LLVM-IR and assembly code and has undergone instruction fine-tuning to interpret compiler behavior. LLM Compiler is released under a bespoke commercial license to allow wide reuse and is available in two sizes: 7 billion and 13 billion parameters. We also present fine-tuned versions of the model, demonstrating its enhanced capabilities in optimizing code size and disassembling from x86_64 and ARM assembly back into LLVM-IR. These achieve 77% of the optimising potential of an autotuning search, and 45% disassembly round trip (14% exact match). This release aims to provide a scalable, cost-effective foundation for further research and development in compiler optimization by both academic researchers and industry practitioners.

Nice job by Cal debunking misconceptions about AI model capabilities. The segment highlights a few points I cover in my unpublished NoLM - Not Only Language Models blog post. Specifically the fact that Language Models on their own can't do much and need to be connected to data sources and other systems. Complex AI systems will be built with more specialized roles and leverage various components for their planning and execution. In the end though, models will require integration into existing systems. Those integrations need to be done by people, meaning humans are still in control of the AI-assisted system capabilities.
Later in the podcast, Cal takes a question about distributed webs of trust. I agree with Cal's point of using existing open standards like RSS for content consumption. It's the reason you often hear the phrase, "or wherever you get your podcasts". Assuming you have a program that can read an RSS feed, you can follow all types of content. On the topic of discovery, Cal makes the suggestion of using distributed webs of trust. Using domain names and linking as ways of discovering content. While blogrolls were not directly called out, it's one of the benefits a curated set of links provides.
https://ntietz.com/blog/blogging-affirmations/
The affirmations
Here are the things I've seen and learned. Each of these will be expanded in its own section.
- You have things to write about.
- Your perspective matters.
- You are good enough.
- Posts don't have to be novel.
- People will read it.
- Mistakes are okay!
- It's okay to ask for things.
- You can get started quickly.
- You can write on a schedule.

Despite the odds, cassette tapes are making a comeback. And one family-owned company in Springfield, Missouri is a leader in the revival.
Hopefully this also means that players are also making a comeback because you need something to play them on. Having visited a museum recently full of old radio recordings on cassette tapes, I was sad to find out I couldn't listen to them because the tape player was broken. It's hard enough finding a decent MP3 player, I'm sure it must be just as hard if not harder finding a tape player.
https://www.modular.com/blog/deep-dive-into-ownership-in-mojo
In the second part of the ownership series in Mojo, we built on the mental model developed in the first part and provided practical examples to illustrate how ownership works in Mojo. We covered the different kinds of values (BValue, LValue, and RValue) and how they propagate through expressions. We also explained the function argument conventions (borrowed, inout, owned) and demonstrated how these conventions help manage memory safely and efficiently. We concluded with three fundamental rules:
- Rule 1: Owned arguments take RValue on the caller side but are LValue on the callee side.
- Rule 2: Owned arguments own the type if the transfer operator ^ is used; otherwise, they copy the type if it is Copyable.
- Rule 3: Copy operations are optimized to move operations if the type is Copyable and Movable and isn’t used anymore, reducing unnecessary overhead.
Lastly, we emphasized that the main goals of ownership in Mojo are:
- Memory Safety: Enforcing exclusive ownership and proper lifetimes to prevent memory errors such as use-after-free and double-free.
- Performance Optimization: Converting unnecessary copy operations into move operations to reduce overhead and enhance performance.
- Ease of Use: Automating memory management through ownership rules and the transfer operator, simplifying development.
- Compile-Time Guarantees: Providing strong compile-time guarantees through type-checking and dataflow lifetime analysis, catching errors early in the development process.
https://www.eff.org/deeplinks/2024/05/bigfoot
I’m proud to share the first post in a series from our friends, The Encryptids—the rarely-seen enigmas who inspire campfire lore. But this time, they’re spilling secrets about how they survive this ever-digital world. We begin by checking in with the legendary Bigfoot de la Sasquatch...
People say I'm the most famous of The Encryptids, but sometimes I don't want the spotlight. They all want a piece of me: exes, ad trackers, scammers, even the government. A picture may be worth a thousand words, but my digital profile is worth cash (to skeezy data brokers). I can’t hit a city block without being captured by doorbell cameras, CCTV, license plate readers, and a maze of street-level surveillance. It can make you want to give up on privacy altogether. Honey, no. Why should you have to hole up in some dank, busted forest for freedom and respect? You don’t.
Privacy isn't about hiding. It's about revealing what you want to who you want on your terms. It's your basic right to dignity.
https://www.anthropic.com/research/mapping-mind-language-model
Today we report a significant advance in understanding the inner workings of AI models. We have identified how millions of concepts are represented inside Claude Sonnet, one of our deployed large language models. This is the first ever detailed look inside a modern, production-grade large language model. This interpretability discovery could, in future, help us make AI models safer.
Previously, we made some progress matching patterns of neuron activations, called features, to human-interpretable concepts. We used a technique called "dictionary learning", borrowed from classical machine learning, which isolates patterns of neuron activations that recur across many different contexts. In turn, any internal state of the model can be represented in terms of a few active features instead of many active neurons. Just as every English word in a dictionary is made by combining letters, and every sentence is made by combining words, every feature in an AI model is made by combining neurons, and every internal state is made by combining features.
In October 2023, we reported success applying dictionary learning to a very small "toy" language model and found coherent features corresponding to concepts like uppercase text, DNA sequences, surnames in citations, nouns in mathematics, or function arguments in Python code.
We used the same scaling law philosophy that predicts the performance of larger models from smaller ones to tune our methods at an affordable scale before launching on Sonnet.
We successfully extracted millions of features from the middle layer of Claude 3.0 Sonnet, (a member of our current, state-of-the-art model family, currently available on claude.ai), providing a rough conceptual map of its internal states halfway through its computation. This is the first ever detailed look inside a modern, production-grade large language model.
https://www.anthropic.com/research/claude-character
Companies developing AI models generally train them to avoid saying harmful things and to avoid assisting with harmful tasks. The goal of this is to train models to behave in ways that are "harmless". But when we think of the character of those we find genuinely admirable, we don’t just think of harm avoidance. We think about those who are curious about the world, who strive to tell the truth without being unkind, and who are able to see many sides of an issue without becoming overconfident or overly cautious in their views. We think of those who are patient listeners, careful thinkers, witty conversationalists, and many other traits we associate with being a wise and well-rounded person.
AI models are not, of course, people. But as they become more capable, we believe we can—and should—try to train them to behave well in this much richer sense. Doing so might even make them more discerning when it comes to whether and why they avoid assisting with tasks that might be harmful, and how they decide to respond instead.
Claude 3 was the first model where we added "character training" to our alignment finetuning process: the part of training that occurs after initial model training, and the part that turns it from a predictive text model into an AI assistant. The goal of character training is to make Claude begin to have more nuanced, richer traits like curiosity, open-mindedness, and thoughtfulness.
Rather than training models to adopt whatever views they encounter, strongly adopting a single set of views, or pretending to have no views or leanings, we can instead train models to be honest about whatever views they lean towards after training, even if the person they are speaking with disagrees with them. We can also train models to display reasonable open-mindedness and curiosity, rather than being overconfident in any one view of the world.
In order to steer Claude’s character and personality, we made a list of many character traits we wanted to encourage the model to have...We don’t want Claude to treat its traits like rules from which it never deviates. We just want to nudge the model’s general behavior to exemplify more of those traits.
Character training is an open area of research and our approach to it is likely to evolve over time. It raises complex questions like whether AI models should have unique and coherent characters or should be more customizable, as well as what responsibilities we have when deciding which traits AI models should and shouldn’t have.
https://github.com/fixie-ai/ultravox
Ultravox is a new kind of multimodal LLM that can understand text as well as human speech, without the need for a separate Audio Speech Recognition (ASR) stage. Building on research like AudioLM, SeamlessM4T, Gazelle, SpeechGPT, and others, we've extended Meta's Llama 3 model with a multimodal projector that converts audio directly into the high-dimensional space used by Llama 3. This direct coupling allows Ultravox to respond much more quickly than systems that combine separate ASR and LLM components. In the future this will also allow Ultravox to natively understand the paralinguistic cues of timing and emotion that are omnipresent in human speech.
The current version of Ultravox (v0.1), when invoked with audio content, has a time-to-first-token (TTFT) of approximately 200ms, and a tokens-per-second rate of ~100, all using a Llama 3 8B backbone. While quite fast, we believe there is considerable room for improvement in these numbers. We look forward to working with LLM hosting providers to deliver state-of-the-art performance for Ultravox.
Ultravox currently takes in audio and emits streaming text. As we evolve the model, we'll train it to be able to emit a stream of speech tokens that can then be converted directly into raw audio by an appropriate unit vocoder. We're interested in working with interested parties to build this functionality!
https://security.apple.com/blog/private-cloud-compute/
We set out to build Private Cloud Compute with a set of core requirements:
- Stateless computation on personal user data. ...we want a strong form of stateless data processing where personal data leaves no trace in the PCC system.
- Enforceable guarantee. Security and privacy guarantees are strongest when they are entirely technically enforceable, which means it must be possible to constrain and analyze all the components that critically contribute to the guarantees of the overall Private Cloud Compute system.
- No privileged runtime access. Private Cloud Compute must not contain privileged interfaces that would enable Apple’s site reliability staff to bypass PCC privacy guarantees, even when working to resolve an outage or other severe incident.
- Non-targetability. An attacker should not be able to attempt to compromise personal data that belongs to specific, targeted Private Cloud Compute users without attempting a broad compromise of the entire PCC system.
- Verifiable transparency. Security researchers need to be able to verify, with a high degree of confidence, that our privacy and security guarantees for Private Cloud Compute match our public promises.
https://machinelearning.apple.com/research/introducing-apple-foundation-models
Apple Intelligence is comprised of multiple highly-capable generative models that are specialized for our users’ everyday tasks, and can adapt on the fly for their current activity. The foundation models built into Apple Intelligence have been fine-tuned for user experiences such as writing and refining text, prioritizing and summarizing notifications, creating playful images for conversations with family and friends, and taking in-app actions to simplify interactions across apps.
In the following overview, we will detail how two of these models — a ~3 billion parameter on-device language model, and a larger server-based language model available with Private Cloud Compute and running on Apple silicon servers — have been built and adapted to perform specialized tasks efficiently, accurately, and responsibly. These two foundation models are part of a larger family of generative models created by Apple to support users and developers; this includes a coding model to build intelligence into Xcode, as well as a diffusion model to help users express themselves visually, for example, in the Messages app.
Pre-training
Our foundation models are trained on Apple's AXLearn framework, an open-source project we released in 2023. It builds on top of JAX and XLA, and allows us to train the models with high efficiency and scalability on various training hardware and cloud platforms, including TPUs and both cloud and on-premise GPUs. We used a combination of data parallelism, tensor parallelism, sequence parallelism, and Fully Sharded Data Parallel (FSDP) to scale training along multiple dimensions such as data, model, and sequence length.
Post-training
We find that data quality is essential to model success, so we utilize a hybrid data strategy in our training pipeline, incorporating both human-annotated and synthetic data, and conduct thorough data curation and filtering procedures. We have developed two novel algorithms in post-training: (1) a rejection sampling fine-tuning algorithm with teacher committee, and (2) a reinforcement learning from human feedback (RLHF) algorithm with mirror descent policy optimization and a leave-one-out advantage estimator. We find that these two algorithms lead to significant improvement in the model’s instruction-following quality.
Optimization
Both the on-device and server models use grouped-query-attention. We use shared input and output vocab embedding tables to reduce memory requirements and inference cost. These shared embedding tensors are mapped without duplications. The on-device model uses a vocab size of 49K, while the server model uses a vocab size of 100K, which includes additional language and technical tokens.
For on-device inference, we use low-bit palletization, a critical optimization technique that achieves the necessary memory, power, and performance requirements. To maintain model quality, we developed a new framework using LoRA adapters that incorporates a mixed 2-bit and 4-bit configuration strategy — averaging 3.5 bits-per-weight — to achieve the same accuracy as the uncompressed models.
Additionally, we use an interactive model latency and power analysis tool, Talaria, to better guide the bit rate selection for each operation. We also utilize activation quantization and embedding quantization, and have developed an approach to enable efficient Key-Value (KV) cache update on our neural engines.
Model Adaptation
Our foundation models are fine-tuned for users’ everyday activities, and can dynamically specialize themselves on-the-fly for the task at hand...
We represent the values of the adapter parameters using 16 bits, and for the ~3 billion parameter on-device model, the parameters for a rank 16 adapter typically require 10s of megabytes. The adapter models can be dynamically loaded, temporarily cached in memory, and swapped — giving our foundation model the ability to specialize itself on the fly for the task at hand while efficiently managing memory and guaranteeing the operating system's responsiveness.
Performance and Evaluation
We compare our models with both open-source models (Phi-3, Gemma, Mistral, DBRX) and commercial models of comparable size (GPT-3.5-Turbo, GPT-4-Turbo)1. We find that our models are preferred by human graders over most comparable competitor models. On this benchmark, our on-device model, with ~3B parameters, outperforms larger models including Phi-3-mini, Mistral-7B, and Gemma-7B. Our server model compares favorably to DBRX-Instruct, Mixtral-8x22B, and GPT-3.5-Turbo while being highly efficient.
To further evaluate our models, we use the Instruction-Following Eval (IFEval) benchmark to compare their instruction-following capabilities with models of comparable size. The results suggest that both our on-device and server model follow detailed instructions better than the open-source and commercial models of comparable size.
https://www.apple.com/newsroom/2024/06/introducing-apple-intelligence-for-iphone-ipad-and-mac/
Apple today introduced Apple Intelligence, the personal intelligence system for iPhone, iPad, and Mac that combines the power of generative models with personal context to deliver intelligence that’s incredibly useful and relevant.
Apple Intelligence unlocks new ways for users to enhance their writing and communicate more effectively. With brand-new systemwide Writing Tools built into iOS 18, iPadOS 18, and macOS Sequoia, users can rewrite, proofread, and summarize text nearly everywhere they write...
Apple Intelligence powers exciting image creation capabilities to help users communicate and express themselves in new ways. With Image Playground, users can create fun images in seconds, choosing from three styles: Animation, Illustration, or Sketch...All images are created on device, giving users the freedom to experiment with as many images as they want.
Powered by Apple Intelligence, Siri becomes more deeply integrated into the system experience. With richer language-understanding capabilities, Siri is more natural, more contextually relevant, and more personal, with the ability to simplify and accelerate everyday tasks.
A cornerstone of Apple Intelligence is on-device processing, and many of the models that power it run entirely on device. To run more complex requests that require more processing power, Private Cloud Compute extends the privacy and security of Apple devices into the cloud to unlock even more intelligence.
Apple is integrating ChatGPT access into experiences within iOS 18, iPadOS 18, and macOS Sequoia, allowing users to access its expertise — as well as its image- and document-understanding capabilities — without needing to jump between tools.
https://www.youtube.com/watch?v=sBXdyUA6A88
I always look forward to watching these recap videos from the Verge.


https://bair.berkeley.edu/blog/2024/05/29/tiny-agent/

The ability of LLMs to execute commands through plain language (e.g. English) has enabled agentic systems that can complete a user query by orchestrating the right set of tools...recent multi-modal efforts such as the GPT-4o or Gemini-1.5 model, has expanded the realm of possibilities with AI agents. While this is quite exciting, the large model size and computational requirements of these models often requires their inference to be performed on the cloud. This can create several challenges for their widespread adoption. First and foremost, uploading data such as video, audio, or text documents to a third party vendor on the cloud, can result in privacy issues. Second, this requires cloud/Wi-Fi connectivity which is not always possible...latency could also be an issue as uploading large amounts of data to the cloud and waiting for the response could slow down response time, resulting in unacceptable time-to-solution. These challenges could be solved if we deploy the LLM models locally at the edge.
...current LLMs like GPT-4o or Gemini-1.5 are too large for local deployment. One contributing factor is that a lot of the model size ends up memorizing general information about the world into its parametric memory which may not be necessary for a specialized downstream application.
...this leads to an intriguing research question:
Can a smaller language model with significantly less parametric memory emulate such emergent ability of these larger language models?
Achieving this would significantly reduce the computational footprint of agentic systems and thus enable efficient and privacy-preserving edge deployment. Our study demonstrates that this is feasible for small language models through training with specialized, high-quality data that does not require recalling generic world knowledge.
Such a system could particularly be useful for semantic systems where the AI agent’s role is to understand the user query in natural language and, instead of responding with a ChatGPT-type question answer response, orchestrate the right set of tools and APIs to accomplish the user’s command. For example, in a Siri-like application, a user may ask a language model to create a calendar invite with particular attendees. If a predefined script for creating calendar items already exists, the LLM simply needs to learn how to invoke this script with the correct input arguments (such as attendees’ email addresses, event title, and time). This process does not require recalling/memorization of world knowledge from sources like Wikipedia, but rather requires reasoning and learning to call the right functions and to correctly orchestrate them.
Our goal is to develop Small Language Models (SLM) that are capable of complex reasoning that could be deployed securely and privately at the edge. Here we will discuss the research directions that we are pursuing to that end. First, we discuss how we can enable small open-source models to perform accurate function calling, which is a key component of agentic systems. It turns out that off-the-shelf small models have very low function calling capabilities. We discuss how we address this by systematically curating high-quality data for function calling, using a specialized Mac assistant agent as our driving application. We then show that fine-tuning the model on this high quality curated dataset, can enable SLMs to even exceed GPT-4-Turbo’s function calling performance. We then show that this could be further improved and made efficient through a new Tool RAG method. Finally, we show how the final models could be deployed efficiently at the edge with real time responses.

https://genai-handbook.github.io/
This document aims to serve as a handbook for learning the key concepts underlying modern artificial intelligence systems. Given the speed of recent development in AI, there really isn’t a good textbook-style source for getting up-to-speed on the latest-and-greatest innovations in LLMs or other generative models, yet there is an abundance of great explainer resources (blog posts, videos, etc.) for these topics scattered across the internet. My goal is to organize the “best” of these resources into a textbook-style presentation, which can serve as a roadmap for filling in the prerequisites towards individual AI-related learning goals. My hope is that this will be a “living document”, to be updated as new innovations and paradigms inevitably emerge, and ideally also a document that can benefit from community input and contribution. This guide is aimed at those with a technical background of some kind, who are interested in diving into AI either out of curiosity or for a potential career. I’ll assume that you have some experience with coding and high-school level math, but otherwise will provide pointers for filling in any other prerequisites.
Cool project.
Turn a fresh Ubuntu installation into a fully-configured, beautiful, and modern web development system by running a single command.
Omakub is an opinionated take on what Linux can be at its best.
Omakub includes a curated set of applications and tools that one might discover through hours of watching YouTube, reading blogs, or just stumbling around Linux internet. All so someone coming straight from a platform like Windows or the Mac can immediately start enjoying a ready-made system, without having to do any configuration and curation legwork at all.
I'm guilty of owning way too many domains but this short-hand (lqdev.me) and other permadomain (luisquintanilla.me) are the ones I use mostly.
A potential happy medium I've seen is using subdomains (i.e. project.lqdev.me).
Jim Nielsen has great examples of how he's doing that today. Though that's an older post, he also addressed it most recently in the post Domain Sins of My Youth.
That somehow feels better than the URL you get when you use free hosting like GitHub Pages. As a bonus, it's already tied to your identity (if using your personal domain). Also, you save some money.
There's a few ways I practice this today. In addition to the previously mentioned domains, I also own lqdev.tech. Services and projects I host live there.
For example:
- Mastodon Instance (toot.lqdev.tech)
- Matrix server (matrix.lqdev.tech)
- Webmentions service (webmentions.lqdev.tech)
So far it's been working well.
https://www.manton.org/2024/05/29/podcast-hosting-for.html
This is cool! The Micro.blog premium plan has tons of great features as well.
Six years ago, we launched our $10/month plan with podcast hosting. Since then we’ve added several big features to the plan...
Today, I want to bring the podcast feature to more people, so we’re moving it down to the standard $5/month plan.
https://github.com/karpathy/llm.c/discussions/481
...the TLDR is that we're training a 12-layer GPT-2 (124M), from scratch, on 10B tokens of FineWeb, with max sequence length of 1024 tokens.
The 124M model is the smallest model in the GPT-2 series released by OpenAI in 2019, and is actually quite accessible today, even for the GPU poor. With llm.c, which is quite efficient at up to ~60% model flops utilization, reproducing this model on one 8X A100 80GB SXM node takes ~90 minutes. For example, on Lambda this node goes for ~$14/hr, so the total cost of reproducing this model today is about $20. You can train the model with a single GPU too, it would just take proportionally longer (e.g. ~4-24 hours depending on the GPU).
21 years since Mike and I did the first release of WordPress, forking Michel’s work on b2/cafélog.
I’ve been thinking a lot about elements that made WordPress successful in its early years that we should keep in mind as we build this year and beyond. Here’s 11 opinions:
- Simple things should be easy and intuitive, and complex things possible.
...- Wikis are amazing, and our documentation should be wiki-easy to edit.
...- It’s important that we all do support, go to meetups and events, anything we can to stay close to regular end-users of what we make.
Congrats to WordPress and the team on 21 years. I think the following are some good elements to keep building on.
https://www.theverge.com/2024/5/23/24163225/daylight-dc1-tablet-livepaper
Like many in the comments, I like the idea of this device and what it's aiming to do.
The "LivePaper" display technology seems interesting.
At $729 though, it seems a little steep. I paid a fraction of that for my Onyx Boox Nova Air 2 and I have most of the functionality of this device. As an e-reader, note-taking device, and tablet that can install any Android app, it works perfectly fine for my use cases and I'm very happy with it.
Still, I'm interested in seeing whether this takes off or whether it ends up being another Rabbit R1 or Humane Ai Pin.
🙋
Great post.
One of the challenges I've found, even when using appliances like those from hosting providers like Linode or tools like YunoHost is connecting them to your domain.
Usually, that's specific to your domain name provider and usually a manual process.
In cases where that's easy, you're often overcharged for the convenience. Compared to "free" social media and publishing websites, it makes using your own domain a less desirable option.
Maybe advocating for a multi-staged approach like IndieWebify.Me could make the journey more approachable. More importantly, making it a journey, rather than a destination could help with meeting folks where they are and guide them closer towards their goals.
In any case, the proposed list of goals seem like a great start towards helping people create their own place on the web.
https://www.theverge.com/2024/5/24/24163865/doge-meme-shiba-inu-kabosu-dead-crypto
The face of one of the defining memes of the 2010s, the doge meme, died on Friday. Kabosu, the shiba inu with the knowing face that launched a million internet jokes, was 18 when she died


Between this article and The Dumbphone Boom is Real, I'm seeing more publications on the subject. Far from a comeback, but still cool to see.
https://kamasiwashington.ffm.to/fearlessmovement
2024 just keeps getting better in terms of new music releases.
Kamasi Washington has a new album coming out this week called Fearless Movement.
The most recent single, Dream State, with Andre 3000 is great.
https://www.newyorker.com/culture/infinite-scroll/the-dumbphone-boom-is-real
Will Stults spent too much time on his iPhone, doom-scrolling the site formerly known as Twitter and tweeting angrily at Elon Musk as if the billionaire would actually notice. Stults’s partner, Daisy Krigbaum, was addicted to Pinterest and YouTube, bingeing videos on her iPhone before going to sleep. Two years ago, they both tried Apple’s Screen Time restriction tool and found it too easy to disable, so the pair decided to trade out their iPhones for more low-tech devices. They’d heard about so-called dumbphones, which lacked the kinds of bells and whistles—a high-resolution screen, an app store, a video camera—that made smartphones so addictive. But they found the process of acquiring one hard to navigate. “The information on it was kind of disparate and hard to get to. A lot of people who know the most about dumbphones spend the least time online,” Krigbaum said. A certain irony presented itself: figuring out a way to be less online required aggressive online digging.
The growing dumbphone fervor may be motivated, in part, by the discourse around child safety online. Parents are increasingly confronted with evidence that sites like Instagram and TikTok intentionally try to hook their children. Using those sites can increase teens’ anxiety and lower their self-esteem, according to some studies, and smartphones make it so that kids are logged on constantly. Why should this situation be any healthier for adults? After almost two decades with iPhones, the public seems to be experiencing a collective ennui with digital life. So many hours of each day are lived through our portable, glowing screens, but the Internet isn’t even fun anymore. We lack the self-control to wean ourselves off, so we crave devices that actively prevent us from getting sucked into them. That means opting out of the prevailing technology and into what Cal Newport, a contributing writer for The New Yorker, has called a more considered “digital minimalism.”
While dumbphones aren't a cure-all for unhealthy technology habits, as a dumbphone user, I can relate to the frustrations that come from the lack of device availability and support. Even when new devices hit the market, they tend to be targeted towards non-US markets.
https://www.snowflake.com/blog/arctic-open-efficient-foundation-language-models-snowflake/
Today, the Snowflake AI Research Team is thrilled to introduce Snowflake Arctic, a top-tier enterprise-focused LLM that pushes the frontiers of cost-effective training and openness. Arctic is efficiently intelligent and truly open.
- Efficiently Intelligent: Arctic excels at enterprise tasks such as SQL generation, coding and instruction following benchmarks even when compared to open source models trained with significantly higher compute budgets. In fact, it sets a new baseline for cost-effective training to enable Snowflake customers to create high-quality custom models for their enterprise needs at a low cost.
- Truly Open: Apache 2.0 license provides ungated access to weights and code. In addition, we are also open sourcing all of our data recipes and research insights.
Snowflake Arctic is available from Hugging Face, NVIDIA API catalog and Replicate today or via your model garden or catalog of choice, including Snowflake Cortex, Amazon Web Services (AWS), Microsoft Azure, Lamini, Perplexity and Together over the coming days.
https://www.theverge.com/2024/4/24/24139057/pbs-retro-free-roku-channel-fast-streaming
PBS is making child edutainment classics like Zoboomafoo, Mister Rogers’ Neighborhood, and Reading Rainbow available for free on a new ‘PBS Retro’ channel on Roku.
This is cool! Although I'm kind of bummed the stuff I grew up watching is now considered "retro".
https://www.noemamag.com/we-need-to-rewild-the-internet/
The internet has become an extractive and fragile monoculture. But we can revitalize it using lessons learned by ecologists.
Our online spaces are not ecosystems, though tech firms love that word. They’re plantations; highly concentrated and controlled environments...
We all know this. We see it each time we reach for our phones. But what most people have missed is how this concentration reaches deep into the internet’s infrastructure — the pipes and protocols, cables and networks, search engines and browsers. These structures determine how we build and use the internet, now and in the future.
They’ve concentrated into a series of near-planetary duopolies.
Two kinds of everything may be enough to fill a fictional ark and repopulate a ruined world, but can’t run an open, global “network of networks” where everyone has the same chance to innovate and compete.
The internet made the tech giants possible. Their services have scaled globally, via its open, interoperable core. But for the past decade, they’ve also worked to enclose the varied, competing and often open-source or collectively provided services the internet is built on into their proprietary domains. Although this improves their operational efficiency, it also ensures that the flourishing conditions of their own emergence aren’t repeated by potential competitors. For tech giants, the long period of open internet evolution is over. Their internet is not an ecosystem. It’s a zoo.
Up close, internet concentration seems too intricate to untangle; from far away, it seems too difficult to deal with. But what if we thought of the internet not as a doomsday “hyperobject,” but as a damaged and struggling ecosystem facing destruction? What if we looked at it not with helpless horror at the eldritch encroachment of its current controllers, but with compassion, constructiveness and hope?
Rewilding “aims to restore healthy ecosystems by creating wild, biodiverse spaces,” according to the International Union for Conservation of Nature. More ambitious and risk-tolerant than traditional conservation, it targets entire ecosystems to make space for complex food webs and the emergence of unexpected interspecies relations. It’s less interested in saving specific endangered species. Individual species are just ecosystem components, and focusing on components loses sight of the whole. Ecosystems flourish through multiple points of contact between their many elements, just like computer networks. And like in computer networks, ecosystem interactions are multifaceted and generative.
Whatever we do, the internet isn’t returning to old-school then-common interfaces like FTP and Gopher, or organizations operating their own mail servers again instead of off-the-shelf solutions like G-Suite. But some of what we need is already here, especially on the web. Look at the resurgence of RSS feeds, email newsletters and blogs, as we discover (yet again) that relying on one app to host global conversations creates a single point of failure and control. New systems are growing, like the Fediverse with its federated islands, or Bluesky with algorithmic choice and composable moderation.
We don’t know what the future holds. Our job is to keep open as much opportunity as we can, trusting that those who come later will use it. Instead of setting purity tests for which kind of internet is most like the original, we can test changes against the values of the original design. Do new standards protect the network’s “generality,” i.e. its ability to support multiple uses, or is functionality limited to optimize efficiency for the biggest tech firms?
...our internet took off because it was designed as a general-purpose network, built to connect anyone.
Our internet was built to be complex and unbiddable, to do things we cannot yet imagine.
Internet infrastructure is a degraded ecosystem, but it’s also a built environment, like a city. Its unpredictability makes it generative, worthwhile and deeply human.
We need to stop thinking of internet infrastructure as too hard to fix. It’s the underlying system we use for nearly everything we do.
Rewilding the internet connects and grows what people are doing across regulation, standards-setting and new ways of organizing and building infrastructure, to tell a shared story of where we want to go. It’s a shared vision with many strategies. The instruments we need to shift away from extractive technological monocultures are at hand or ready to be built.
Calculus Made Easy is a book on calculus originally published in 1910 by Silvanus P. Thompson, considered a classic and elegant introduction to the subject.
https://projects.kwon.nyc/internet-is-fun/
I’ve been meaning to write some kind of Important Thinkpiece™ on the glory days of the early internet, but every time I sit down to do it, I find another, better piece that someone else has already written. So for now, here’s a collection of articles that to some degree answer the question “Why have a personal website?” with “Because it’s fun, and the internet used to be fun.”
This is a great catalog of posts about the personal web. Courtesy of Rachel Kwon
This is a site encouraging non-technical people and organisations to create their own online services such as websites, social networks, personal clouds, instant messaging etc.
Large language models (LLMs) have revolutionized a wide range of tasks and applications that were previously reliant on manually crafted machine learning (ML) solutions, streamlining through automation. However, despite these advances, a notable challenge persists: the need for extensive prompt engineering to adapt these models to new tasks. New generations of language models like GPT-4 and Mixtral 8x7B advance the capability to process long input texts. This progress enables the use of longer inputs, providing richer context and detailed instructions to language models. A common technique that uses this enhanced capacity is the Retrieval Augmented Generation (RAG) approach. RAG dynamically incorporates information into the prompt based on the specific input example.
To address these challenges, we developed the Structure-Aware Multi-objective Metaprompt Optimization (SAMMO) framework. SAMMO is a new open-source tool that streamlines the optimization of prompts, particularly those that combine different types of structural information like in the RAG example above. It can make structural changes, such as removing entire components or replacing them with different ones. These features enable AI practitioners and researchers to efficiently refine their prompts with little manual effort.
Central to SAMMO’s innovation is its approach to treating prompts not just as static text inputs but as dynamic, programmable entities—metaprompts. SAMMO represents these metaprompts as function graphs, where individual components and substructures can be modified to optimize performance, similar to the optimization process that occurs during traditional program compilation.
The following key features contribute to SAMMO’s effectiveness:
- Structured optimization: Unlike current methods that focus on text-level changes, SAMMO focuses on optimizing the structure of metaprompts. This granular approach facilitates precise modifications and enables the straightforward integration of domain knowledge, for instance, through rewrite operations targeting specific stylistic objectives.
- Multi-objective search: SAMMO’s flexibility enables it to simultaneously address multiple objectives, such as improving accuracy and computational efficiency. Our paper illustrates how SAMMO can be used to compress prompts without compromising their accuracy.
- General purpose application: SAMMO has proven to deliver significant performance improvements across a variety of tasks, including instruction tuning, RAG, and prompt compression.
Reading this post and attached image brings back so many memories.
I remember in the last few years of Blockbuster and early days of Netflix, for about $20/month you could rent unlimited movies (I think it was up to three at a time).
If you binge watched them or weren't happy with the choices you made, you could just drive down to your local store, return them, and grab a new set of movies.
Initially you had a return period, but towards the end, there were none so you basically got to keep some movies as long as you liked.
Good times.
https://activitypub.ghost.org/
In 2024, Ghost is adopting ActivityPub and connecting with other federated platforms across the web.
This means that, soon, Ghost publishers will be able to follow, like and interact with one another in the same way that you would normally do on a social network — but on your own website.
The difference, of course, is that you’ll also be able to follow, like, and interact with users on Mastodon, Threads, Flipboard, Buttondown, WriteFreely, Tumblr, WordPress, PeerTube, Pixelfed... or any other platform that has adopted ActivityPub, too. You don’t need to limit yourself to following people who happen to use the same platform as you.
For the past few years the choice has been difficult. Either participate in closed networks at the mercy of algorithms, or set up an independent website at the expense of your growth.
Email gave us private messaging technology that isn’t owned by a single company.
ActivityPub is doing the same for social technology.
The open web is coming back, and with it returns diversity. You can both publish independently and grow faster than ever before with followers from all over the world & the web.
I can't express how much I love this. Personally I don't use Ghost, but given platforms like WordPress and now Ghost are adding support for ActivityPub, it empowers people to build their own platforms.
That said, this still doesn't address the challenges of building your own website, which as mentioned in the post are one of the appealing aspects of current closed networks.
Still though, there is a vast number of creators, businesses, and company websites or blogs that can benefit from this today. When paired with RSS, it gives people choice and autonomy in how they create and consume content as I mentioned in a previous post, Rediscovering the RSS protocol
https://github.com/google-deepmind/penzai
A JAX research toolkit for building, editing, and visualizing neural networks.
Penzai is a JAX library for writing models as legible, functional pytree data structures, along with tools for visualizing, modifying, and analyzing them. Penzai focuses on making it easy to do stuff with models after they have been trained, making it a great choice for research involving reverse-engineering or ablating model components, inspecting and probing internal activations, performing model surgery, debugging architectures, and more. (But if you just want to build and train a model, you can do that too!)

https://azure.microsoft.com/en-us/blog/introducing-phi-3-redefining-whats-possible-with-slms/
Starting today, Phi-3-mini, a 3.8B language model is available on Microsoft Azure AI Studio, Hugging Face, and Ollama.
- Phi-3-mini is available in two context-length variants—4K and 128K tokens. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.
- It is instruction-tuned, meaning that it’s trained to follow different types of instructions reflecting how people normally communicate. This ensures the model is ready to use out-of-the-box.
- It is available on Azure AI to take advantage of the deploy-eval-finetune toolchain, and is available on Ollama for developers to run locally on their laptops.
- It has been optimized for ONNX Runtime with support for Windows DirectML along with cross-platform support across graphics processing unit (GPU), CPU, and even mobile hardware.
- It is also available as an NVIDIA NIM microservice with a standard API interface that can be deployed anywhere. And has been optimized for NVIDIA GPUs.
In the coming weeks, additional models will be added to Phi-3 family to offer customers even more flexibility across the quality-cost curve. Phi-3-small (7B) and Phi-3-medium (14B) will be available in the Azure AI model catalog and other model gardens shortly.
https://llama.meta.com/llama3/
Build the future of AI with Meta Llama 3
Now available with both 8B and 70B pretrained and instruction-tuned versions to support a wide range of applications
Llama 3 models take data and scale to new heights. It’s been trained on our two recently announced custom-built 24K GPU clusters on over 15T token of data – a training dataset 7x larger than that used for Llama 2, including 4x more code. This results in the most capable Llama model yet, which supports a 8K context length that doubles the capacity of Llama 2.
http://radiobilingue.org/rb-programas/alterlatino/
While listening to KHOL earlier today, they were rebroadcasting a recording of A Todo Pulmon, a radio show from Radio Bilingue in Fresno, CA. Good stuff.
https://proton.me/blog/proton-standard-notes-join-forces
...today, we’re happy to announce that Standard Notes will also join us to advance our shared mission.
Both Proton and Standard Notes share a strong commitment to our communities, so Standard Notes will remain open source, freely available, and fully supported. Prices are not changing, and if you have a current subscription to Standard Notes, it will continue to be honored. Proton aspires to do the right thing and be a responsible home for open-source projects, and just as we did with SimpleLogin, we are committed to preserving what makes Standard Notes special and much loved.
In the coming months, we hope to find ways to make Standard Notes more easily accessible to the Proton community. This way, in addition to protecting your email, calendar, files, passwords, and online activity, you can also protect your notes.
This is another exciting acquisition! I mainly use org-mode in Emacs for note taking. However, I love the ecosystem Proton is building with their security and privacy focused set of collaborative software offerings.
https://arxiv.org/abs/2402.19427
Recurrent neural networks (RNNs) have fast inference and scale efficiently on long sequences, but they are difficult to train and hard to scale. We propose Hawk, an RNN with gated linear recurrences, and Griffin, a hybrid model that mixes gated linear recurrences with local attention. Hawk exceeds the reported performance of Mamba on downstream tasks, while Griffin matches the performance of Llama-2 despite being trained on over 6 times fewer tokens. We also show that Griffin can extrapolate on sequences significantly longer than those seen during training. Our models match the hardware efficiency of Transformers during training, and during inference they have lower latency and significantly higher throughput. We scale Griffin up to 14B parameters, and explain how to shard our models for efficient distributed training.
https://arxiv.org/abs/2402.09910
How can we detect if copyrighted content was used in the training process of a language model, considering that the training data is typically undisclosed? We are motivated by the premise that a language model is likely to identify verbatim excerpts from its training text. We propose DE-COP, a method to determine whether a piece of copyrighted content was included in training. DE-COP's core approach is to probe an LLM with multiple-choice questions, whose options include both verbatim text and their paraphrases. We construct BookTection, a benchmark with excerpts from 165 books published prior and subsequent to a model's training cutoff, along with their paraphrases. Our experiments show that DE-COP surpasses the prior best method by 9.6% in detection performance (AUC) on models with logits available. Moreover, DE-COP also achieves an average accuracy of 72% for detecting suspect books on fully black-box models where prior methods give ≈ 4% accuracy. Our code and datasets are available at this https URL
https://arxiv.org/abs/2401.02115
Text-to-SQL models can generate a list of candidate SQL queries, and the best query is often in the candidate list, but not at the top of the list. An effective re-rank method can select the right SQL query from the candidate list and improve the model's performance. Previous studies on code generation automatically generate test cases and use them to re-rank candidate codes. However, automatic test case generation for text-to-SQL is an understudied field. We propose an automatic test case generation method that first generates a database and then uses LLMs to predict the ground truth, which is the expected execution results of the ground truth SQL query on this database. To reduce the difficulty for LLMs to predict, we conduct experiments to search for ways to generate easy databases for LLMs and design easy-to-understand prompts. Based on our test case generation method, we propose a re-rank method to select the right SQL query from the candidate list. Given a candidate list, our method can generate test cases and re-rank the candidate list according to their pass numbers on these test cases and their generation probabilities. The experiment results on the validation dataset of Spider show that the performance of some state-of-the-art models can get a 3.6% improvement after applying our re-rank method.
https://github.com/google-deepmind/recurrentgemma
RecurrentGemma is a family of open-weights Language Models by Google DeepMind, based on the novel Griffin architecture. This architecture achieves fast inference when generating long sequences by replacing global attention with a mixture of local attention and linear recurrences.
This repository contains the model implementation and examples for sampling and fine-tuning. We recommend most users adopt the Flax implementation, which is highly optimized. We also provide an un-optimized PyTorch implementation for reference.
https://blog.allenai.org/hello-olmo-a-truly-open-llm-43f7e7359222
Today, The Allen Institute for AI (AI2) has released OLMo 7B, a truly open, state-of-the-art large language model released alongside the pre-training data and training code. This empowers researchers and developers to use the best and open models to advance the science of language models collectively.
https://github.com/karpathy/llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.
https://www.theverge.com/2024/4/9/24124179/beeper-app-automattic-acquisition-matrix-messaging
Beeper, the upstart messaging app that attempts to corral all your messaging services into one inbox, is being acquired by Automattic, the giant that runs Wordpress.com, Tumblr, and a number of other hugely popular web properties
This is exciting especially given some of the recent developments in the EU. What's most interesting to me is how Beeper leverages open protocols like Matrix and for bridging capabilities where possible to provide secure messaging.
With more people moving to smaller spaces to communicate with their communities, being able to do so in a single place without everyone being on the same platform like in the early days of the internet is a welcome development.
Additional coverage from the Beeper blog.
What we’re announcing today…
- No more waitlist – Beeper is now available to everyone!
- Beeper has been acquired by Automattic
- Our new Android app is out of beta
- We’re renaming Beeper Cloud → Beeper (sorry for the confusion)
Today the announcement went out that we’re combining the best technology from Beeper and Texts to create a great private, secure, and open source messaging client for people to have control of their communications. We’re going to use the Beeper brand, because it’s fun. This is not unlike how browsers have evolved, where solid tech and encryption on top of an open ecosystem has created untold value for humanity.
A lot of people are asking about iMessage on Android… I have zero interest in fighting with Apple, I think instead it’s best to focus on messaging networks that want more engagement from power-user clients. This is an area I’m excited to work on when I return from my sabbatical next month.
https://arxiv.org/abs/2404.01037
Retrieval-Augmented Generation (RAG) is essential for integrating external knowledge into Large Language Model (LLM) outputs. While the literature on RAG is growing, it primarily focuses on systematic reviews and comparisons of new state-of-the-art (SoTA) techniques against their predecessors, with a gap in extensive experimental comparisons. This study begins to address this gap by assessing various RAG methods' impacts on retrieval precision and answer similarity. We found that Hypothetical Document Embedding (HyDE) and LLM reranking significantly enhance retrieval precision. However, Maximal Marginal Relevance (MMR) and Cohere rerank did not exhibit notable advantages over a baseline Naive RAG system, and Multi-query approaches underperformed. Sentence Window Retrieval emerged as the most effective for retrieval precision, despite its variable performance on answer similarity. The study confirms the potential of the Document Summary Index as a competent retrieval approach. All resources related to this research are publicly accessible for further investigation through our GitHub repository ARAGOG (this https URL). We welcome the community to further this exploratory study in RAG systems.
https://www.mollywhite.net/blogroll/
Bookmarking for reference.
I'm already subscribed to many of these websites and publications. However, there's several new ones I found that I think will eventually make their rotation into my blogroll.
New fine-tuning API features
Today, we’re introducing new features to give developers even more control over their fine-tuning jobs, including:
- Epoch-based Checkpoint Creation: Automatically produce one full fine-tuned model checkpoint during each training epoch, which reduces the need for subsequent retraining, especially in the cases of overfitting
- Comparative Playground: A new side-by-side Playground UI for comparing model quality and performance, allowing human evaluation of the outputs of multiple models or fine-tune snapshots against a single prompt
- Third-party Integration: Support for integrations with third-party platforms (starting with Weights and Biases this week) to let developers share detailed fine-tuning data to the rest of their stack
- Comprehensive Validation Metrics: The ability to compute metrics like loss and accuracy over the entire validation dataset instead of a sampled batch, providing better insight on model quality
- Hyperparameter Configuration: The ability to configure available hyperparameters from the Dashboard (rather than only through the API or SDK)
- Fine-Tuning Dashboard Improvements: Including the ability to configure hyperparameters, view more detailed training metrics, and rerun jobs from previous configurations
Expanding our Custom Models Program
- Assisted Fine-Tuning
Today, we are formally announcing our assisted fine-tuning offering as part of the Custom Model program. Assisted fine-tuning is a collaborative effort with our technical teams to leverage techniques beyond the fine-tuning API, such as additional hyperparameters and various parameter efficient fine-tuning (PEFT) methods at a larger scale. It’s particularly helpful for organizations that need support setting up efficient training data pipelines, evaluation systems, and bespoke parameters and methods to maximize model performance for their use case or task.
- Custom-Trained Model
In some cases, organizations need to train a purpose-built model from scratch that understands their business, industry, or domain. Fully custom-trained models imbue new knowledge from a specific domain by modifying key steps of the model training process using novel mid-training and post-training techniques. Organizations that see success with a fully custom-trained model often have large quantities of proprietary data—millions of examples or billions of tokens—that they want to use to teach the model new knowledge or complex, unique behaviors for highly specific use cases.
https://txt.cohere.com/command-r-plus-microsoft-azure/
Command R+ is a state-of-the-art RAG-optimized model designed to tackle enterprise-grade workloads, and is available first on Microsoft Azure
Command R+, like our recently launched Command R model, features a 128k-token context window and is designed to offer best-in-class:
- Advanced Retrieval Augmented Generation (RAG) with citation to reduce hallucinations
- Multilingual coverage in 10 key languages to support global business operations
- Tool Use to automate sophisticated business processes
https://github.com/ngruver/llmtime
By encoding time series as a string of numerical digits, we can frame time series forecasting as next-token prediction in text. Developing this approach, we find that large language models (LLMs) such as GPT-3 and LLaMA-2 can surprisingly zero-shot extrapolate time series at a level comparable to or exceeding the performance of purpose-built time series models trained on the downstream tasks. To facilitate this performance, we propose procedures for effectively tokenizing time series data and converting discrete distributions over tokens into highly flexible densities over continuous values. We argue the success of LLMs for time series stems from their ability to naturally represent multimodal distributions, in conjunction with biases for simplicity, and repetition, which align with the salient features in many time series, such as repeated seasonal trends. We also show how LLMs can naturally handle missing data without imputation through non-numerical text, accommodate textual side information, and answer questions to help explain predictions. While we find that increasing model size generally improves performance on time series, we show GPT-4 can perform worse than GPT-3 because of how it tokenizes numbers, and poor uncertainty calibration, which is likely the result of alignment interventions such as RLHF.
https://github.com/intel-analytics/ipex-llm
IPEX-LLM is a PyTorch library for running LLM on Intel CPU and GPU (e.g., local PC with iGPU, discrete GPU such as Arc, Flex and Max) with very low latency
https://arxiv.org/abs/2403.20329
Reference resolution is an important problem, one that is essential to understand and successfully handle context of different kinds. This context includes both previous turns and context that pertains to non-conversational entities, such as entities on the user's screen or those running in the background. While LLMs have been shown to be extremely powerful for a variety of tasks, their use in reference resolution, particularly for non-conversational entities, remains underutilized. This paper demonstrates how LLMs can be used to create an extremely effective system to resolve references of various types, by showing how reference resolution can be converted into a language modeling problem, despite involving forms of entities like those on screen that are not traditionally conducive to being reduced to a text-only modality. We demonstrate large improvements over an existing system with similar functionality across different types of references, with our smallest model obtaining absolute gains of over 5% for on-screen references. We also benchmark against GPT-3.5 and GPT-4, with our smallest model achieving performance comparable to that of GPT-4, and our larger models substantially outperforming it.
https://stability.ai/news/stable-audio-2-0
Stable Audio 2.0 sets a new standard in AI-generated audio, producing high-quality, full tracks with coherent musical structure up to three minutes in length at 44.1kHz stereo.
The new model introduces audio-to-audio generation by allowing users to upload and transform samples using natural language prompts.
Stable Audio 2.0 was exclusively trained on a licensed dataset from the AudioSparx music library, honoring opt-out requests and ensuring fair compensation for creators.
Deadline reports that The Martian writer Drew Goddard has been tapped to pen and direct another Matrix movie executive produced by Lana Wachowski. Currently, the new film has no title or projected premiere date, and there’s been no announcement as to whether franchise stars like Keanu Reeves, Carrie-Anne Moss, Laurence Fishburne, Yahya Abdul-Mateen II, or Jessica Henwick will return.
Not sure how to feel about this, but I'll end up watching anyway.
Good article. I felt this way when Google Reader and a few other services were shut down.
That being said, this is kind of a good thing.
Luckily, there are plenty of good podcast apps out there, like Pocket Casts, Overcast, Antennapod, and even Apple Podcasts.
This line basically says it all. Podcasts, like blogging, continue to be an open ecosystem and where the saying,"wherever you get your podcasts", is still going strong.
https://openai.com/blog/start-using-chatgpt-instantly
We’re making it easier for people to experience the benefits of AI without needing to sign up.
We may use what you provide to ChatGPT to improve our models for everyone. If you’d like, you can turn this off through your Settings - whether you create an account or not.
We’ve also introduced additional content safeguards for this experience, such as blocking prompts and generations in a wider range of categories.
https://www.theverge.com/24115039/danger-hiptop-t-mobile-sidekick-jump-button
Bring back the Sidekick! Ayaneo Slide is probably the closest to this today. Would love to see a smaller version of it running on Windows on ARM-based Snapdragon processors.
Before the iPhone, before Android, before webOS, a revolutionary soap bar of a phone made it incredibly easy to get shit done. The Danger Hiptop, better known as the T-Mobile Sidekick, made the internet portable and affordable like no phone before.
https://www.databricks.com/blog/announcing-dbrx-new-standard-efficient-open-source-customizable-llms
Today, we are excited to advance our mission by open sourcing DBRX, a general purpose large language model (LLM) built by our Mosaic Research team that outperforms all established open source models on standard benchmarks. We believe that pushing the boundary of open source models enables generative AI for all enterprises that is customizable and transparent.
We are excited about DBRX for three distinct reasons. First, it handily beats open source models, such as, LLaMA2-70B, Mixtral, and Grok-1 on language understanding, programming, math, and logic...
Second, DBRX beats GPT-3.5 on most benchmarks...
Third, DBRX is a Mixture-of-Experts (MoE) model built on the MegaBlocks research and open source project, making the model extremely fast in terms of tokens/second.
https://tianweiy.github.io/dmd/
Our one-step generator achieves comparable image quality with StableDiffusion v1.5 while being 30x faster.
Diffusion models are known to approximate the score function of the distribution they are trained on. In other words, an unrealistic synthetic image can be directed toward higher probability density region through the denoising process (see SDS). Our core idea is training two diffusion models to estimate not only the score function of the target real distribution, but also that of the fake distribution. We construct a gradient update to our generator as the difference between the two scores, essentially nudging the generated images toward higher realism as well as lower fakeness (see VSD). Our method is similar to GANs in that a critic is jointly trained with the generator to minimize a divergence between the real and fake distributions, but differs in that our training does not play an adversarial game that may cause training instability, and our critic can fully leverage the weights of a pretrained diffusion model. Combined with a simple regression loss to match the output of the multi-step diffusion model, our method outperforms all published few-step diffusion approaches, reaching 2.62 FID on ImageNet 64x64 and 11.49 FID on zero-shot COCO-30k, comparable to Stable Diffusion but orders of magnitude faster. Utilizing FP16 inference, our model generates images at 20 FPS on modern hardware.
https://www.404media.co/404-media-now-has-a-full-text-rss-feed/
We paid for the development of full text RSS feeds for Ghost-based publishers. Now we can offer them to our paid subscribers, and other Ghost sites can use the service too.
Our friends Anil Dash and Ernie Smith have recently written passionately and persuasively about the importance of RSS to the open web, and about how a technology that turns 25 years old this month remains both subversive and quite versatile. RSS-based distribution underpins a podcasting ecosystem that has allowed for shows to be distributed not just on Apple Podcasts but on Spotify, Google Podcasts, Pocket Casts, Overcast, and whatever other podcast player you might want to listen on. “Being able to say, ‘wherever you get your podcasts’ is a radical statement,” Dash wrote. “Because what it represents is the triumph of exactly the kind of technology that's supposed to be impossible: open, empowering tech that's not owned by any one company, that can't be controlled by any one company, and that allows people to have ownership over their work and their relationship with their audience.”
RSS has empowered podcasters, but that it needs a “creator economy rethink” for text.
https://stability.ai/news/stabilityai-announcement
Earlier today, Emad Mostaque resigned from his role as CEO of Stability AI and from his position on the Board of Directors of the company to pursue decentralized AI.
https://arxiv.org/abs/2312.00752
Foundation models, now powering most of the exciting applications in deep learning, are almost universally based on the Transformer architecture and its core attention module. Many subquadratic-time architectures such as linear attention, gated convolution and recurrent models, and structured state space models (SSMs) have been developed to address Transformers' computational inefficiency on long sequences, but they have not performed as well as attention on important modalities such as language. We identify that a key weakness of such models is their inability to perform content-based reasoning, and make several improvements. First, simply letting the SSM parameters be functions of the input addresses their weakness with discrete modalities, allowing the model to selectively propagate or forget information along the sequence length dimension depending on the current token. Second, even though this change prevents the use of efficient convolutions, we design a hardware-aware parallel algorithm in recurrent mode. We integrate these selective SSMs into a simplified end-to-end neural network architecture without attention or even MLP blocks (Mamba). Mamba enjoys fast inference (5× higher throughput than Transformers) and linear scaling in sequence length, and its performance improves on real data up to million-length sequences. As a general sequence model backbone, Mamba achieves state-of-the-art performance across several modalities such as language, audio, and genomics. On language modeling, our Mamba-3B model outperforms Transformers of the same size and matches Transformers twice its size, both in pretraining and downstream evaluation.
https://huggingface.co/blog/Pclanglais/common-corpus
We announce today the release of Common Corpus on HuggingFace:
- Common Corpus is the largest public domain dataset released for training LLMs.
- Common Corpus includes 500 billion words from a wide diversity of cultural heritage initiatives.
- Common Corpus is multilingual and the largest corpus to date in English, French, Dutch, Spanish, German and Italian.
- Common Corpus shows it is possible to train fully open LLMs on sources without copyright concerns.
https://huggingface.co/learn/ml-games-course/unit0/introduction
Welcome to the course that will teach you the most fascinating topic in game development: how to use powerful AI tools and models to create unique game experiences.
New AI models are revolutionizing the Game Industry in two impactful ways:
- On how we make games:
- Generate textures using AI
- Using AI voice actors for the voices.
- How we create gameplay:
- Crafting smart Non-Playable Characters (NPCs) using large language models.
This course will teach you:
- How to integrate AI models for innovative gameplay, featuring intelligent NPCs.
- How to use AI tools to help your game development pipeline.
In the same way that every little place in America used to have a printed newspaper, every little place in America could have an online local chronicle.
Broadly speaking, an online local chronicle is a collection of facts organized mostly in chronological order. The “pages” of the chronicle can be thought of as subsets of a community’s universal timeline of events. These online local chronicles could become the backbone of local news operations.
Nice project. Unfortunately, it's rare you get local news. I like publications / websites like Hoboken Girl and Block Club Chicago. I wish there were more of them in more cities and towns. I know they're there in some forms like Facebook Groups. Even better, it'd be great to have the websites for these publications be the main source of truth that then syndicated their content to the various platforms out there.
https://huggingface.co/blog/quanto-introduction
Quantization is a technique to reduce the computational and memory costs of evaluating Deep Learning Models by representing their weights and activations with low-precision data types like 8-bit integer (int8) instead of the usual 32-bit floating point (float32).
Today, we are excited to introduce quanto, a versatile pytorch quantization toolkit, that provides several unique features:
- available in eager mode (works with non-traceable models)
- quantized models can be placed on any device (including CUDA and MPS),
- automatically inserts quantization and dequantization stubs,
- automatically inserts quantized functional operations,
- automatically inserts quantized modules (see below the list of supported modules),
- provides a seamless workflow for a float model, going from a dynamic to a static quantized model,
- supports quantized model serialization as a state_dict,
- supports not only int8 weights, but also int2 and int4,
- supports not only int8 activations, but also float8.
https://arxiv.org/abs/2310.04475
Embeddings have become a pivotal means to represent complex, multi-faceted information about entities, concepts, and relationships in a condensed and useful format. Nevertheless, they often preclude direct interpretation. While downstream tasks make use of these compressed representations, meaningful interpretation usually requires visualization using dimensionality reduction or specialized machine learning interpretability methods. This paper addresses the challenge of making such embeddings more interpretable and broadly useful, by employing Large Language Models (LLMs) to directly interact with embeddings -- transforming abstract vectors into understandable narratives. By injecting embeddings into LLMs, we enable querying and exploration of complex embedding data. We demonstrate our approach on a variety of diverse tasks, including: enhancing concept activation vectors (CAVs), communicating novel embedded entities, and decoding user preferences in recommender systems. Our work couples the immense information potential of embeddings with the interpretative power of LLMs.
https://huggingface.co/spaces/Xenova/the-tokenizer-playground
Experiment with different tokenizers (running locally in your browser). I really love doing this thing
https://stability.ai/news/introducing-stable-video-3d
Today we are releasing Stable Video 3D (SV3D), a generative model based on Stable Video Diffusion, advancing the field of 3D technology and delivering greatly improved quality and view-consistency.
This release features two variants: SV3D_u and SV3D_p. SV3D_u generates orbital videos based on single image inputs without camera conditioning. SV3D_p extends the capability by accommodating both single images and orbital views, allowing for the creation of 3D video along specified camera paths.
Stable Video 3D can be used now for commercial purposes with a Stability AI Membership. For non-commercial use, you can download the model weights on Hugging Face and view our research paper here.
https://www.theverge.com/2024/3/18/24105157/nvidia-blackwell-gpu-b200-ai
Nvidia reveals Blackwell B200 GPU, the ‘world’s most powerful chip’ for AI
‘Built to democratize trillion-parameter AI.’
Nvidia says the new B200 GPU offers up to 20 petaflops of FP4 horsepower from its 208 billion transistors. Also, it says, a GB200 that combines two of those GPUs with a single Grace CPU can offer 30 times the performance for LLM inference workloads while also potentially being substantially more efficient. It “reduces cost and energy consumption by up to 25x” over an H100, says Nvidia.
https://arxiv.org/abs/2403.09611
In this work, we discuss building performant Multimodal Large Language Models (MLLMs). In particular, we study the importance of various architecture components and data choices. Through careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of image-caption, interleaved image-text, and text-only data is crucial for achieving state-of-the-art (SOTA) few-shot results across multiple benchmarks, compared to other published pre-training results. Further, we show that the image encoder together with image resolution and the image token count has substantial impact, while the vision-language connector design is of comparatively negligible importance. By scaling up the presented recipe, we build MM1, a family of multimodal models up to 30B parameters, consisting of both dense models and mixture-of-experts (MoE) variants, that are SOTA in pre-training metrics and achieve competitive performance after supervised fine-tuning on a range of established multimodal benchmarks. Thanks to large-scale pre-training, MM1 enjoys appealing properties such as enhanced in-context learning, and multi-image reasoning, enabling few-shot chain-of-thought prompting.
A practical guide to constructing and retrieving information from knowledge graphs in RAG applications with Neo4j and LangChain
Graph retrieval augmented generation (Graph RAG) is gaining momentum and emerging as a powerful addition to traditional vector search retrieval methods. This approach leverages the structured nature of graph databases, which organize data as nodes and relationships, to enhance the depth and contextuality of retrieved information.
https://github.com/lavague-ai/LaVague
Redefining internet surfing by transforming natural language instructions into seamless browser interactions.
https://en.algorithmica.org/hpc/
This is an upcoming high performance computing book titled “Algorithms for Modern Hardware” by Sergey Slotin.
Its intended audience is everyone from performance engineers and practical algorithm researchers to undergraduate computer science students who have just finished an advanced algorithms course and want to learn more practical ways to speed up a program than by going from O(nlogn)O(nlogn) to O(nloglogn)O(nloglogn).
https://spreadsheets-are-all-you-need.ai/index.html
A low-code way to learn AI - Learn how AI works from a real LLM implemented entirely in Excel
https://engineering.fb.com/2024/03/12/data-center-engineering/building-metas-genai-infrastructure/
- Marking a major investment in Meta’s AI future, we are announcing two 24k GPU clusters. We are sharing details on the hardware, network, storage, design, performance, and software that help us extract high throughput and reliability for various AI workloads. We use this cluster design for Llama 3 training.
- We are strongly committed to open compute and open source. We built these clusters on top of Grand Teton, OpenRack, and PyTorch and continue to push open innovation across the industry.
- This announcement is one step in our ambitious infrastructure roadmap. By the end of 2024, we’re aiming to continue to grow our infrastructure build-out that will include 350,000 NVIDIA H100 GPUs as part of a portfolio that will feature compute power equivalent to nearly 600,000 H100s.
https://github.com/openai/transformer-debugger
Transformer Debugger (TDB) is a tool developed by OpenAI's Superalignment team with the goal of supporting investigations into specific behaviors of small language models. The tool combines automated interpretability techniques with sparse autoencoders.
TDB enables rapid exploration before needing to write code, with the ability to intervene in the forward pass and see how it affects a particular behavior. It can be used to answer questions like, "Why does the model output token A instead of token B for this prompt?" or "Why does attention head H attend to token T for this prompt?" It does so by identifying specific components (neurons, attention heads, autoencoder latents) that contribute to the behavior, showing automatically generated explanations of what causes those components to activate most strongly, and tracing connections between components to help discover circuits.
https://www.tonyduan.com/diffusion/index.html
Here, we'll cover the derivations from scratch to provide a rigorous understanding of the core ideas behind diffusion. What assumptions are we making? What properties arise as a result?
A reference [codebase] is written from scratch, which provides minimalist re-production of the MNIST example below. It clocks in at under 500 lines of code.
Each page takes up to an hour to read thoroughly. Approximately a lecture each.
https://www.chenyang.co/diffusion.html
This tutorial aims to introduce diffusion models from an optimization perspective as introduced in our paper (joint work with Frank Permenter). It will go over both theory and code, using the theory to explain how to implement diffusion models from scratch. By the end of the tutorial, you will learn how to implement training and sampling code for a toy dataset, which will also work for larger datasets and models.
https://arxiv.org/abs/2311.12224
We introduce a new algorithm called the Free-pipeline Fast Inner Product (FFIP) and its hardware architecture that improve an under-explored fast inner-product algorithm (FIP) proposed by Winograd in 1968. Unlike the unrelated Winograd minimal filtering algorithms for convolutional layers, FIP is applicable to all machine learning (ML) model layers that can mainly decompose to matrix multiplication, including fully-connected, convolutional, recurrent, and attention/transformer layers. We implement FIP for the first time in an ML accelerator then present our FFIP algorithm and generalized architecture which inherently improve FIP's clock frequency and, as a consequence, throughput for a similar hardware cost. Finally, we contribute ML-specific optimizations for the FIP and FFIP algorithms and architectures. We show that FFIP can be seamlessly incorporated into traditional fixed-point systolic array ML accelerators to achieve the same throughput with half the number of multiply-accumulate (MAC) units, or it can double the maximum systolic array size that can fit onto devices with a fixed hardware budget. Our FFIP implementation for non-sparse ML models with 8 to 16-bit fixed-point inputs achieves higher throughput and compute efficiency than the best-in-class prior solutions on the same type of compute platform.
https://github.com/xai-org/grok-1
This repository contains JAX example code for loading and running the Grok-1 open-weights model.
https://ollama.com/blog/amd-preview
Ollama now supports AMD graphics cards in preview on Windows and Linux. All the features of Ollama can now be accelerated by AMD graphics cards on Ollama for Linux and Windows.
https://hugo.blog/2024/03/11/vision-pro/
Friends and colleagues have been asking me to share my perspective on the Apple Vision Pro as a product.
This started as blog post and became an essay before too long, so I’ve structured my writing in multiple sections each with a clear lead to make it a bit easier to digest — peppered with my own ‘takes’. I’ve tried to stick to original thoughts for the most part and link to what others have said where applicable.
Some of the topics I touch on:
- Why I believe Vision Pro may be an over-engineered “devkit”
- The genius & audacity behind some of Apple’s hardware decisions
- Gaze & pinch is an incredible UI superpower and major industry ah-ha moment
- Why the Vision Pro software/content story is so dull and unimaginative
- Why most people won’t use Vision Pro for watching TV/movies
- Apple’s bet in immersive video is a total game-changer for Live Sports
- Why I returned my Vision Pro… and my Top 10 wishlist to reconsider
- Apple’s VR debut is the best thing that ever happened to Oculus/Meta
- My unsolicited product advice to Meta for Quest Pro 2 and beyond
https://bsky.social/about/blog/03-12-2024-stackable-moderation
Bluesky was created to put users and communities in control of their social spaces online. The first generation of social media platforms connected the world, but ended up consolidating power in the hands of a few corporations and their leaders. Our online experience doesn’t have to depend on billionaires unilaterally making decisions over what we see. On an open social network like Bluesky, you can shape your experience for yourself.
Today, we’re excited to announce that we’re open-sourcing Ozone, our collaborative moderation tool. With Ozone, individuals and teams can work together to review and label content across the network. Later this week, we’re opening up the ability for you to run your own independent moderation services, seamlessly integrated into the Bluesky app. This means that you'll be able to create and subscribe to additional moderation services on top of what Bluesky requires, giving you unprecedented control over your social media experience.
https://proton.me/blog/proton-mail-desktop-app
Today, we’re excited to broaden the horizons of secure communication by launching the Proton Mail desktop app. Anyone can now use the new Proton Mail desktop app for Windows and macOS, with a Linux version in beta.
With the new Proton Mail desktop apps, you get a dedicated email experience, allowing you to enjoy all the productivity innovations of our web app, allowing you to go through your emails and events faster without the potential distractions that pop up anytime you open your browser. And, of course, your privacy remains protected at all times.
https://huyenchip.com//2024/03/14/ai-oss.html
So many cool ideas are being developed by the community. Here are some of my favorites.
- Batch inference optimization: FlexGen, llama.cpp
- Faster decoder with techniques such as Medusa, LookaheadDecoding
- Model merging: mergekit
- Constrained sampling: outlines, guidance, SGLang
- Seemingly niche tools that solve one problem really well, such as einops and safetensors.
https://www.answer.ai/posts/2024-03-06-fsdp-qlora.html
Today, we’re releasing Answer.AI’s first project: a fully open source system that, for the first time, can efficiently train a 70b large language model on a regular desktop computer with two or more standard gaming GPUs (RTX 3090 or 4090). This system, which combines FSDP and QLoRA, is the result of a collaboration between Answer.AI, Tim Dettmers (U Washington), and Hugging Face’s Titus von Koeller and Sourab Mangrulkar.
https://jxnl.github.io/blog/writing/2024/02/28/levels-of-complexity-rag-applications/
This post comprehensive guide to understanding and implementing RAG applications across different levels of complexity. Whether you're a beginner eager to learn the basics or an experienced developer looking to deepen your expertise, you'll find valuable insights and practical knowledge to help you on your journey. Let's embark on this exciting exploration together and unlock the full potential of RAG applications.
https://www.zdnet.com/article/5-reasons-why-desktop-linux-is-finally-growing-in-popularity/
StatCounter reported that desktop Linux reached over 4% market share for the first time.
Why is Linux finally growing?
While Windows is the king of the hill with 72.13% and MacOS comes in a distant second at 15.46%, it's clear that Linux is making progress.
- Microsoft isn't that interested in Windows
- Linux gaming, thanks to Steam, is also growing
- Users are finally figuring out that some Linux distros are easy to use
- Finding and installing Linux desktop software is easier than ever
- The Linux desktop is growing in popularity in India
https://inflection.ai/inflection-2-5
At Inflection, our mission is to create a personal AI for everyone. Last May, we released Pi—a personal AI, designed to be empathetic, helpful, and safe. In November we announced a new major foundation model, Inflection-2, the second best LLM in the world at the time.
Now we are adding IQ to Pi’s exceptional EQ.
We are launching Inflection-2.5, our upgraded in-house model that is competitive with all the world's leading LLMs like GPT-4 and Gemini. It couples raw capability with our signature personality and unique empathetic fine-tuning. Inflection-2.5 is available to all Pi's users today, at pi.ai, on iOS, on Android, or our new desktop app.
We achieved this milestone with incredible efficiency: Inflection-2.5 approaches GPT-4’s performance, but used only 40% of the amount of compute for training.
Quick take: How do you spend your time at work and what is it costing you? Slack’s Workforce Index, based on survey responses from more than 10,000 desk workers around the globe, uncovers new findings on how to structure the workday to maximize productivity and strengthen employee well-being and satisfaction.
Key learnings include:
- Employees who log off at the end of the workday register 20% higher productivity scores than those who feel obligated to work after hours.
- Making time for breaks during the workday improves employee productivity and well-being, and yet half of all desk workers say they rarely or never take breaks.
- On average, desk workers say that the ideal amount of focus time is around four hours a day, and more than two hours a day in meetings is the tipping point at which a majority of workers feel overburdened by meetings.
- Three out of every four desk workers report working in the 3 to 6pm timeframe, but of those, only one in four consider these hours highly productive.
https://www.yitay.net/blog/training-great-llms-entirely-from-ground-zero-in-the-wilderness
Given that we’ve successfully trained pretty strong multimodal language models at Reka, many people have been particularly curious about the experiences of building infrastructure and training large language & multimodal models from scratch from a completely clean slate.
I complain a lot about external (outside Google) infrastructure and code on my social media, leading people to really be curious about what are the things I miss and what I hate/love in the wilderness. So here’s a post (finally). This blogpost sheds light on the challenges and lessons learned.
Figuring out things in the wilderness was an interesting experience. It was unfortunately not painless. Compute scarcity and also unreliable compute providers made things significantly harder than expected but we’re glad we pulled through with brute technical strength.
All in all, this is only a small part of the story of how we started a company, raised some money, bought some chips and matched Gemini pro/GPT 3.5 and outperformed many others in less than a year having to build everything from scratch.
https://tylerhou.com/posts/datalog-go-brrr/
The datatype for a graph is a relation, and graph algorithms are queries on the relation. But modern languages need better support for the relational model.
This post is a response to/inspired by The Hunt for the Missing Data Type (HN) by Hillel Wayne. I suggest reading his article first.
I claim the reason why it is so difficult to support graphs in languages nowadays is because the imperative/structured programming model of modern programming languages is ill-suited for graph algorithms. As Wayne correctly points out, the core problem is that when you write a graph algorithm in an imperative language like Python or Rust, you have to choose some explicit representation for the graph. Then, your traversal algorithm is dependent on the representation you chose. If you find out later that your representation is no longer efficient, it is a lot of work to adapt your algorithms for a new representation.
So what if we just, like, didn’t do this?
We already have a declarative programming language where expressing graph algorithms is extremely natural—Datalog, whose semantics are based on* the relational algebra, which was developed in the 1970s.
Wonderful! Except for the “writing Datalog” part.
If Datalog is so great, why hasn’t it seen more adoption?
The short answer is that Datalog is relatively esoteric outside of academia and some industry applications and, as a result, is not a great language from a “software engineering” perspective. It is hard for programmers accustomed to imperative code to write Datalog programs, and large Datalog programs can be hard to write and understand.
https://www.theverge.com/2024/3/5/24091555/apple-podcasts-transcripts-ios-17-4-update
Apple Podcasts will auto-generate transcripts for podcasts beginning today, thanks to the 17.4 update for iPhones and iPads. Transcripts will automatically appear for new podcast episodes shortly after their publication, while Apple will transcribe podcast back catalogs over time.
The podcast transcripts are searchable, allowing users to type in a specific word or phrase and skip to that part of an episode. Users can find transcripts for individual podcast episodes on the bottom-left corner of the “Now Playing” screen.
Podcasters who don’t want to use Apple’s automated transcription can opt to upload their own transcripts via RSS tags or in Apple Podcasts Connect for premium episodes, or they can download and edit Apple’s transcript before reuploading.
This is cool and great for accessibility.
I recently chose to read the latest episode of Decoder instead of listening to it. One of the advantages this also provided was that I could reference direct quotes in my post from the episode.
I could see Apple taking this further by making it easier to generate show notes / descriptions based on the episode using AI.
https://www.theverge.com/2024/3/5/24091370/microsoft-windows-11-android-apps-end-of-support
Microsoft is ending support for its Android subsystem in Windows 11 next year. The software giant first announced it was bringing Android apps to Windows 11 with Amazon’s Appstore nearly three years ago, but this Windows Subsystem for Android will now be deprecated starting March 5th, 2025.
That's unfortunate considering the new lineup of ARM-based PCs expected later this year. It would've been nice to have a mobile PC with 5G support that could run mobile apps for scenarios where there are no web / native PC apps.
https://stability.ai/news/stable-diffusion-3-research-paper
Key Takeaways:
Today, we’re publishing our research paper that dives into the underlying technology powering Stable Diffusion 3.
Stable Diffusion 3 outperforms state-of-the-art text-to-image generation systems such as DALL·E 3, Midjourney v6, and Ideogram v1 in typography and prompt adherence, based on human preference evaluations.
Our new Multimodal Diffusion Transformer (MMDiT) architecture uses separate sets of weights for image and language representations, which improves text understanding and spelling capabilities compared to previous versions of SD3.
https://www.theverge.com/2024/3/4/24090095/wix-ai-website-generator-chatbot
You can now build a website, images and all, using only prompts in Wix’s new AI website builder. Creating a website is free, but you’ll have to upgrade to one of Wix’s premium plans if you want to do things like accept payments or don’t want to be limited to using a Wix domain name.
You’d probably need to delve into Wix’s advanced editing features and know things about actual web development for that. But it was very easy to use the basic AI generator to create something that looks close to a legitimate site to start with, making it much easier to get to a basic starting point.
https://www.theverge.com/24080426/smart-home-tech-matter-pets-kitchen-hubs-how-to
The Verge team and others share their experiences of how smart technologies affect their lives — how it can often help and sometimes frustrate.
In these articles, we’ve concentrated on how our own experiences, and the experiences of others, have affected how we regard smart home tech. We’ve got personal accounts by one reporter who decided to put together a brand-new smart home and another whose brother moved into a home haunted by the ghosts of someone else’s smart tech. Several of our staffers wax enthusiastically about their favorite devices and automations. A writer describes how smart tech makes his home more accessible. Our smart home reviewer tells how she uses technology to keep her varied pets (and she has a lot of them) happy and healthy. We talk to people who use smart devices to help them care for their parents — and more.
...the last platform on the web of any scale or influence is Google Search. And so, over time, webpages have become dramatically optimized for Google Search. And that means the kinds of things people write about, the containers that we write in, are mostly designed to be optimized for Google Search. They’re not designed for, “I need to just quickly tell you about this and move on.” Our little insight was, “Well, what if we just don’t do that? What if we only write for the people who come directly to our website instead of the people who find our articles through Search or Google Discover or whatever other Google platforms are in the world?” And so we just made these little blog posts, and the idea was, if you just come to our website one more time a day because there’s one more thing to look at that you’ll like, we will be fine.
more and more people are starting to realize, “Oh, we should just make the websites more valuable.
...if you start writing for other people, which is the heart of what a blog post really is: it’s you trying to entertain yourself and trying to entertain just a handful of other people, you’re going to go really much farther than trying to satisfy the robot.
Why am I writing in the text box that pays money to Elon and Mark [Zuckerberg] and not my text box?
Why do we all work for free? Look, we want to talk about the platform era and media. Why do we all work for free?
...It’s very confusing, and there are a lot of reasons. If you just sit back and think about why, there are a million reasons why.
One, the software is nicer to use than most CMSes. You just pick one. Name a company that makes a CMS. They’re like, “Is this as fun to use as Twitter?” And the answer is no. Flatly no. Even the one we have now for quick posts is not as fun to use as Twitter was in its heyday. Will this immediately bring me the dopamine hit of immediate feedback? No.
[When redesigning the website]...the first instinct was, “Let’s at least make it easier to publish. Let’s at least remove the barriers to entry to getting on the website, and then we can do comments, and then we can think about how we can distribute in different ways.” So that is working. My team is happier. We did not know that the Twitter thing would happen, but the Twitter thing happened, and our desire to publish in the boxes we controlled went up as a group. And then, on top of it, our audience saw that we were having fun. And once you are having fun anywhere on the internet, people sort of gravitate to you. So traffic has gone up.
The distribution actually just creates the work or creates the pressures that force all the work to be the same. And I think over time that’s what drives the audiences away. So there’s a real change in how these platforms work, where, over time, they just become more and more of the same thing and the creators become more and more the same. And that’s a little exhausting. And every place where you see open distribution, you see a huge variety of creators and content.
Podcasts have basically open distribution. Like podcast or distributor RSS feeds, that means people kind of own their distribution, there’s a vast array of podcast creators. There’s a vast array of podcast formats. They don’t all sound like the beginning of YouTube videos or whatever. And I hate to keep picking on YouTube; you can pick any algorithmic platform, and it’s the same. TikTokers are more the same than different. Podcasters are more different than the same. The web is distributed largely through websites and through RSS. There’s a huge variety of websites and the way websites look. But then you see the algorithmic search pressure push web design kind of all under the same box.
Newsletters distributed by email: open distribution. The newsletter economy is full of a huge variety of creators doing a huge variety of things. They’re more different than the same. So all I see with the fediverse is, “Oh, this is going to open social distribution up a little bit.” It’s going to allow us to control our distribution networks. It’s going to say, “I’m not on Twitter, but people on Twitter can follow my website, and I can go promote that follow anywhere I want in different ways and build an audience outside of the pressures of the algorithm.” To me, just that, that ability to try, is 1 percent better.
If you’re me and you run a big website and you are thinking, “How can I redistribute this website, how can I reach people more directly?” my brain is lit up. You should be able to follow me at TheVerge.com and see all my quick posts in your Threads account when Threads federates.
https://github.com/google/gemma_pytorch
Gemma is a family of lightweight, state-of-the art open models built from research and technology used to create Google Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights, pre-trained variants, and instruction-tuned variants.
This is the official PyTorch implementation of Gemma models. We provide model and inference implementations using both PyTorch and PyTorch/XLA, and support running inference on CPU, GPU and TPU.
https://www.anthropic.com/news/claude-3-family
Today, we're announcing the Claude 3 model family, which sets new industry benchmarks across a wide range of cognitive tasks. The family includes three state-of-the-art models in ascending order of capability: Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. Each successive model offers increasingly powerful performance, allowing users to select the optimal balance of intelligence, speed, and cost for their specific application.
Claude 3 Opus is our most intelligent model, with best-in-market performance on highly complex tasks. It can navigate open-ended prompts and sight-unseen scenarios with remarkable fluency and human-like understanding. Opus shows us the outer limits of what’s possible with generative AI.
Claude 3 Sonnet strikes the ideal balance between intelligence and speed—particularly for enterprise workloads. It delivers strong performance at a lower cost compared to its peers, and is engineered for high endurance in large-scale AI deployments.
Claude 3 Haiku is our fastest, most compact model for near-instant responsiveness. It answers simple queries and requests with unmatched speed. Users will be able to build seamless AI experiences that mimic human interactions.
https://vickiboykis.com/2024/02/28/gguf-the-long-way-around/
We’ve been on a whirlwind adventure to build up our intuition of how machine learning models work, what artifacts they produce, how the machine learning artifact storage story has changed over the past couple years, and finally ended up in GGUF’s documentation to better understand the log that is presented to us when we perform local inference on artifacts in GGUF.
https://huyenchip.com//2024/02/28/predictive-human-preference.html
Human preference has emerged to be both the Northstar and a powerful tool for AI model development. Human preference guides post-training techniques including RLHF and DPO. Human preference is also used to rank AI models, as used by LMSYS’s Chatbot Arena.
Chatbot Arena aims to determine which model is generally preferred. I wanted to see if it’s possible to do predictive human preference: determine which model is preferred for each query.
This post first discusses the correctness of Chatbot Arena, which will then be used as a baseline to evaluate the correctness of preference predictions. It then discusses how to build a preference predictor and the initial results.
https://arxiv.org/abs/2402.17764
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.
https://www.theverge.com/2024/2/28/24085869/tubi-redesign-shows-movies-turple
Tubi says its new ‘turple’-forward brand identity is all about encouraging viewers to fall down rabbit holes to find exciting shows and movies to watch.
I've often found good content to watch on Tubi. Sure, they're not the latest blockbusters but there are decades worth of movies out there. Just like today, not all movies that come out are good but there's still tons of great content. Sometimes, there's even overlooked gems.
http://www.eastgate.com/garden/Enter.html
The time, care, and expense devoted to creating and promoting a hypertext are lost if readers arrive, glance around, and click elsewhere. How can the craft of hypertext invite readers to stay, to explore, and to reflect?
https://www.theverge.com/24084772/celebrities-no-phone-bieber-sheeran-cruise-cera-ipad
...[phone-free celebs are] not trying to disconnect from everyone, but they are trying to get away from that feeling of being tapped constantly on the shoulder by all the calls, texts, and emails.
So many celebrities ditch their phone, disconnect from their social media, log off entirely.
A few years ago, Ed Sheeran shared a strategy...He hasn’t had a phone since 2015...Being phoneless hadn’t cut his contact to the world, Sheeran said, just reduced it — and that was the point. “I have friends email and people email, and every few days I’ll sit down and open up my laptop, and I’ll answer 10 emails at a time,” he said. “I’ll send them off, and I close my laptop, and then that’ll be it. And then I’ll go back to living my life, and I don’t feel overwhelmed by it.”
Read and watch enough celebrity interviews, and the lesson becomes obvious: that the most powerful and connected device in your life shouldn’t be within arm’s reach at all times. All that does is invite distraction and makes it too easy to disengage from your life every time you get bored or sad or curious even for a second.
It sounds a little like I’m advocating for the return of the ’90s, when the computer was a giant box that lived in a central room of your home and the only way to use it was to go to it. And to some extent, I am! I’m increasingly convinced that my primary computer should be a device I use on purpose — that I sit down at, operate, and then extract myself from until the next time. Whether it’s a laptop on a desk or an iPad on your nightstand, your computer should be a place as much as it is a device. And when you’re not in that place, you’re somewhere else. The computer doesn’t come along.
Over the last few weeks, as an experiment, I’ve moved as many apps as possible — the obviously distracting social media stuff but also anything I can live without on a minute-to-minute basis — off my phone and onto my tablet and my laptop...
So far, it’s been great. I’m realizing how much of a crutch my phone really has become: I would open up TikTok just to keep me company on the walk to the kitchen or scroll through Threads while I waited for the microwave to finish. Now, I’m not sure I’m doing any less of those things in aggregate, but at least I’m doing them on purpose. I’ve turned time-wasting into a deliberate activity — I sit in my scrolling chair and scroll away, then I get up, and the scrolling stays put. And best of all, when I leave the house, there’s nothing to scroll at all.
There has always been talk in tech about removing friction: the obsessive corporate desire to make everything easier, faster, fewer clicks, fewer chances for you to decide not to click that ad or buy that thing or like that post or upload that photo...It should be a little harder for someone to distract me while I’m eating dinner with my wife or hanging out with my kid.
It’s not about ditching technology, just about doing technology on purpose.
Tumblr and WordPress.com are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
I generally enjoy what Automattic does for the web as a whole. However, if these claims are true, it's unfortunate. I believe there's a way to opt-out, but I'd love to learn more before jumping to conclusions.
That said, WordPress (.com not .org) and Tumblr are platforms just like Reddit, Twitter, and the Meta set of offerings. I'm sure somewhere in their Terms of Service, there's some clauses around their ownserhip of the data you published on their platforms and just like it's sold to data brokers and advertisers, they can also sell it to companies training AI models.
To counter these types of moves from platforms, I wish it were as easy as saying "build your own platform". Doing so can be as "simple" as setting up a website using your own domain. Unfortunately, today, it's still not as easy to do and one of the products / companies that help you do that is WordPress. I think it's important though to note the distinction there between WordPress the company and WordPress the technology. Another piece that complicates building your own site is, there's still other ways for companies training AI models to use data that's publicly available on the internet. These are the arguments that are currently being litigated in several legal cases. Maybe there are opportunities to explore a robots.txt for AI.
AI models need high quality data that's representative and as close as possible to the real world in order to improve. There is a role here for synthetic data. High quality synthetic data is behind groundbreaking models like Microsoft's Phi. Instincts tell me that synthetic data can only go so far though and real data is still needed. In that case, as an AI consumer who makes use of these AI models, but don't want to contribute my data, do I have a responsibility to contribute my data to improve the systems that I use? Piracy aside, in some ways it reminds me of torrenting. You usually run into scenarios where there are multiple people downloading a file. However, there's only a handful of seeders who once obtained, make the file available for others to download. There are also additional considerations such as how people are compensated for contributing their data to these systems. It's important to note that this is not a new problem and people had been thinking about this though in different contexts. Maybe it's time to reconsider ideas like inverse privacy and data dignity.
There are no clear answers here and there are a lot of things to consider. However, it's comforting that as a society we're having these conversations.
Microsoft Copilot will soon be able to be your default assistant app on Android.
It's a shame that Cortana never worked out for Microsoft. If things had lined up differently, we may have seen Copilot gain access to smart devices and commands like Gemini has with Google Assistant (though that setup isn't perfect). While Copilot has a place on a computer, I think an assistant on your smartphone needs to be able to do more day-to-day tasks.
So many things were ahead of their time. I just want a Windows Mobile PC (Windows Phone?) with an LLM-backed Cortana.
https://www.theverge.com/entertainment/24054458/physical-media-preservation-discs-cartridges-digital
The bright promise of streaming and digital stores has given way to a darker reality: we rarely have ownership over the art we love, and much is getting lost in the process. Only a fraction of movies released over the last century are available on streaming services, while a staggering 90 percent of classic video games are considered “critically endangered” by archivists. As these platforms continue to dominate the media landscape, a whole lot of cultural history is being abandoned.
In this special issue, The Verge will explore how physical media factors into this and its importance in keeping art alive and accessible. That could mean boutique publishers releasing beautiful special editions of games and movies, foundations dedicated to preserving the physical history of video games, or musicians releasing their latest albums on floppy discs. We’ll also be looking at some cautionary tales in the shift to subscription services and offering tips on building bookshelf-worthy collections.
Cartridges and discs have been hurtling toward obsolescence — but it turns out, they may be more important than ever.
https://joeroganexp.libsyn.com/rss
Since Joe Rogan went exclusive with Spotify, I maybe listened to a handful of episodes. The main reason for it is, I don't use Spotify to listen to podcasts. Periodically, I'd scroll through the feed to see if he had any intereting guests on. As part of his new contract, the podcast is now available on other platforms. That means you can listen wherever you get your podcasts.
After spending years reassuring myself that I don’t need physical copies of movies because of streaming, DVDs have officially reentered my life.
Walmart...Thrift stores, flea markets, the library, and even my local mall’s FYE have also become places I frequent to get my hands on oft-ignored discs.
It makes sense to subscribe to all these services if you’re into the exclusive content on each one and have the patience to sift through their massive libraries. However, all I’ve been watching lately is the junk on Discovery Plus, simply because I’m too tired to find anything else — especially when the extremely specific shows and movies I want to watch keep switching services or just aren’t available. One of the most devastating examples of this was when both The Office and Parks and Recreation moved from Netflix to Peacock, disrupting the casual binge-watching sessions that I would default to when I was done with work.
Within the past year, nearly every streaming service has raised its prices, including Netflix, Disney Plus, Hulu, Paramount Plus, Discovery Plus, and Apple TV Plus.
I’m not saying DVDs are flawless: there’s a reason no one wants them anymore!
Despite this, it’s still nice to have something that you physically own and don’t even need an internet connection to use. So when Best Buy confirmed it would stop selling DVDs this year and rumors emerged that Walmart would do the same, I was pretty disappointed. I can’t imagine Walmart without its bin of DVDs, nor can I even see Best Buy without its already-shrunken selection of movies.
It’s 2024, and I’m not ready to say goodbye to DVDs — in fact, I’m just getting started.
Great article from Emma.
Personally, I've been doing the same. Just a few weekends ago, I got something like 8-10 DVDs for ~$25 at my local thrift store. That haul included 3 seasons of The Sopranos.
With streaming services taking back control of their content and putting it on their own platforms, I don't want to have to keep signing up for a new service just to watch the shows and movies I enjoy. Also, that's assuming you can find the content to begin with (i.e. Westworld).
Parks and Recreation, The Office, and Breaking Bad were some of the first shows I started collecting and have slowly been building up my collection. To save on space, I've ditched the cases and have the DVDs organized in a CD case. I've not only limited myself to DVDs but have also started collecting CDs as well.
Whenever I want variety, I just use one of the free streaming services like:
Yes, there are ads but at least I'm not paying for it and I know that's part of the deal. There are a ton of good older (and sometimes original) TV shows and movies on those platforms to keep me entertained. The most recent ones being Stargate and Vampire's Kiss.
https://mistral.ai/news/mistral-large/
Mistral Large is our flagship model, with top-tier reasoning capacities. It is also available on Azure.
Mistral Large comes with new capabilities and strengths:
- It is natively fluent in English, French, Spanish, German, and Italian, with a nuanced understanding of grammar and cultural context.
- Its 32K tokens context window allows precise information recall from large documents.
- Its precise instruction-following enables developers to design their moderation policies – we used it to set up the system-level moderation of le Chat.
- It is natively capable of function calling. This, along with constrained output mode, implemented on la Plateforme, enables application development and tech stack modernisation at scale.
At Mistral, our mission is to make frontier AI ubiquitous. This is why we’re announcing today that we’re bringing our open and commercial models to Azure.
https://www.theverge.com/24078662/twin-peaks-zelda-links-awakening-influence
In a 2010 interview, Link’s Awakening director Takashi Tezuka revealed the inspiration for this memorably bizarre cast of characters. “At the time, Twin Peaks was rather popular. The drama was all about a small number of characters in a small town,” Tezuka said. “So I wanted to make something like that, while it would be small enough in scope to easily understand, it would have deep and distinctive characteristics.”
... [Mark] Frost reveals in an interview with The Verge, he actually spoke with Nintendo about the Zelda franchise. “I don’t want to overstate it. It was a single conversation. But it was fun,” he tells me.
“They were talking to me about a Twin Peaks game, and they mentioned Zelda at the time,” says Frost. “They said, ‘One of the things we love about your show is how there’s all sorts of sideways associations that can drive the story forward.’ They asked me about that as they were thinking about expanding the Zelda universe.”
Though he’d never played a Zelda game, Frost had enough experience with fantasy storytelling that he had some suggestions. “I’d played lots of Dungeons & Dragons when I was young, so I was familiar with the kind of story they were thinking about,” he says. “I think I said, ‘Don’t be afraid to use dreamlike, Jungian symbolism. Things can connect thematically without having to connect concretely.’ It was things like that that I was urging them [to consider].”
https://www.youtube.com/watch?v=eIm2eK5uuVA

Such a good fight. Frazier had no defense but just kept coming forward.
I wish they'd use AI to keep the ice cream machines from breaking instead.
https://www.youtube.com/watch?v=VrnEQ3TqZGE

Great performance. I remember the first time I listened to Salami was when she opened for Flying Lotus and she was amazing.
https://bsky.social/about/blog/02-22-2024-open-social-web
Today, we’re excited to announce that the Bluesky network is federating and opening up in a way that allows you to host your own data. What does this mean?
Your data, such as your posts, likes, and follows, needs to be stored somewhere. With traditional social media, your data is stored by the social media company whose services you've signed up for. If you ever want to stop using that company's services, you can do that—but you would have to leave that social network and lose your existing connections.
It doesn't have to be this way! An alternative model is how the internet itself works. Anyone can put up a website on the internet
We think social media should work the same way. When you register on Bluesky, by default we'll suggest that Bluesky will store your data. But if you'd like to let another company store it, or even store it yourself, you can do that. You'll also be able to change your mind at any point, moving your data to another provider without losing any of your existing posts, likes, or follows. From your followers' perspective, your profile is always available at your handle—no matter where your information is actually stored, or how many times it has been moved.
I don't spend a lot of time on Bluesky, but I love what they're doing.
They now:
Now you can self-host your data. I'm excited.
The other piece of this that's interesting is their feature which enables you to use your domain as a custom handle. Not only is your identity portable, but also your data. I'd be interested to see how this works in practice given you can already do some of this on the Fediverse on platforms like Mastodon. Again, that portable identity component to me is crucial. That's one of the challenges with Mastodon today. While you can move instances, your identity changes and while most of your data comes with you, there's tihngs that still dont transfer over. The other part that I'd be interested in seeing is whether or not they can be efficient in the storage of federated data. One of the challenges with Mastodon is, your server quickly fills up because of data from other instances (when you federate). It's gotten better, but this is an area I spend most of my time when maintaining my own self-hosted instance.
I'm excited to tinker and self-host my own data. Maybe I'll also syndicate to Bluesky just like I do with Mastodon today.
In the meantime, you can find me on Bluesky @lqdev.me.
https://stability.ai/news/stable-diffusion-3
Announcing Stable Diffusion 3 in early preview, our most capable text-to-image model with greatly improved performance in multi-subject prompts, image quality, and spelling abilities.
The Stable Diffusion 3 suite of models currently range from 800M to 8B parameters.
Stable Diffusion 3 combines a diffusion transformer architecture and flow matching.
The AI Study Guide: Discover Machine Learning with these free Azure resources
Welcome to the February edition of the Azure AI Study Guide. Every month I’ll be spilling the tea on the best and newest tools for skilling up on Azure AI. This month we’re putting on our thinking caps to investigate Azure Machine Learning (ML). I’ll give you a quick breakdown of what it is, then we’ll explore a four-week roadmap of our top FREE resources for you to continue your AI learning journey! And as a bonus, stay tuned to the end to see what makes machine learning and generative AI a dynamic duo.
https://doc.searls.com/2024/02/21/on-blogs/
Thoughts I jotted down on Mastodon:
- Blogs are newsletters that don’t require subscriptions.
- Blogrolls are lists of blogs.
- Both require the lowest possible cognitive and economic overhead.
- That’s why they are coming back.
I know, they never left. But you get my point.
Cool concept.

The likelihood of it happening is low, but there's a lot of really great opportunities here especially with the new wave or ARM PCs coming. I don't know what the device form factor looks like, but I wouldn't mind carrying around a pocket PC - a true mobile computer. Already with the Windows Store, you have access to tons of apps. For the apps that aren't in the Store, there's the browser. That seemed to be good enough for Apple's Vision Pro. Taking it a step further would the app gap matter as much if you have Copilot as your concierge orchestrating tasks for you using the various services? Better yet, what if these services had their own assistants / GPTs Copilot could talk to and coordinate on your behalf?
At some point, I might just use OpenAI's Sora model to live vicariously through an AI-generated video depicting this alternate reality where Windows Phone exists...
https://simonwillison.net/2024/Feb/21/gemini-pro-video/
I’ve been playing with Gemini Pro 1.5 for a few days, and I think the most exciting feature isn’t so much the token count... it’s the ability to use video as an input.
The ability to extract structured content from text is already one of the most exciting use-cases for LLMs. GPT-4 Video and LLaVA expanded that to images. And now Gemini Pro 1.5 expands that to video.
The ability to analyze video like this feels SO powerful. Being able to take a 20 second video of a bookshelf and get back a JSON array of those books is just the first thing I thought to try.
...as always with modern AI, there are still plenty of challenges to overcome...But this really does feel like another one of those glimpses of a future that’s suddenly far closer then I expected it to be.
https://huggingface.co/chat/assistants
The goal of this app is to showcase that it is now possible to build an open source alternative to ChatGPT.
https://blog.google/technology/developers/gemma-open-models/
Gemma is a family of lightweight, state-of-the-art open models built from the same research and technology used to create the Gemini models. Developed by Google DeepMind and other teams across Google, Gemma is inspired by Gemini, and the name reflects the Latin gemma, meaning “precious stone.” Accompanying our model weights, we’re also releasing tools to support developer innovation, foster collaboration, and guide responsible use of Gemma models.
https://signal.org/blog/phone-number-privacy-usernames/
Signal’s mission and sole focus is private communication. For years, Signal has kept your messages private, your profile information (like your name and profile photo) private, your contacts private, and your groups private – among much else. Now we’re taking that one step further, by making your phone number on Signal more private.
Here’s how:
New default: Your phone number will no longer be visible to everyone in Signal...
Connect without sharing your phone number...
Control who can find you on Signal by phone number...
Right now, these options are in beta, and will be rolling out to everyone in the coming weeks.
https://huggingface.co/datasets/HuggingFaceTB/cosmopedia
Cosmopedia is a dataset of synthetic textbooks, blogposts, stories, posts and WikiHow articles generated by Mixtral-8x7B-Instruct-v0.1.The dataset contains over 30 million files and 25 billion tokens, making it the largest open synthetic dataset to date.
It covers a variety of topics; we tried to map world knowledge present in Web datasets like RefinedWeb and RedPajama, and generate synthetic content that covers them. This is the v0.1 of Cosmopedia, with ample room for improvement and topics to be more comprehensively covered. We hope this dataset will help the community's research efforts in the increasingly intriguing domain of synthetic data.
This work is inspired by the great work of Phi1.5.
https://www.swift.org/blog/mlx-swift/
The Swift programming language has a lot of potential to be used for machine learning research because it combines the ease of use and high-level syntax of a language like Python with the speed of a compiled language like C++.
MLX is an array framework for machine learning research on Apple silicon. MLX is intended for research and not for production deployment of models in apps.
MLX Swift expands MLX to the Swift language, making experimentation on Apple silicon easier for ML researchers.
https://ollama.com/blog/windows-preview
Ollama is now available on Windows in preview, making it possible to pull, run and create large language models in a new native Windows experience. Ollama on Windows includes built-in GPU acceleration, access to the full model library, and the Ollama API including OpenAI compatibility.
https://www.jayeless.net/2024/02/staticrypt.html
...I was longing for a way to do friends-only blog posts on the open web, today I came across StatiCrypt , an open-source utility that lets you encrypt static HTML pages behind a password.
https://huggingface.co/learn/cookbook/index
The Open-Source AI Cookbook is a collection of notebooks illustrating practical aspects of building AI applications and solving various machine learning tasks using open-source tools and models.
https://observablehq.com/blog/observable-2-0
Today we’re launching Observable 2.0 with a bold new vision: an open-source static site generator for building fast, beautiful data apps, dashboards, and reports.
Our mission is to help teams communicate more effectively with data. Effective presentation of data is critical for deep insight, nuanced understanding, and informed decisions. Observable notebooks are great for ephemeral, ad hoc data exploration. But notebooks aren’t well-suited for polished dashboards and apps.
https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/
Today, we’re publicly releasing the Video Joint Embedding Predictive Architecture (V-JEPA) model, a crucial step in advancing machine intelligence with a more grounded understanding of the world.
This early example of a physical world model excels at detecting and understanding highly detailed interactions between objects.
In the spirit of responsible open science, we’re releasing this model under a Creative Commons NonCommercial license for researchers to further explore.
Magic is working on frontier-scale code models to build a coworker, not just a copilot.
Sora is an AI model that can create realistic and imaginative scenes from text instructions.
Sora can generate videos up to a minute long while maintaining visual quality and adherence to the user’s prompt.
Today, we’re announcing our next-generation model: Gemini 1.5.
Gemini 1.5 delivers dramatically enhanced performance. It represents a step change in our approach, building upon research and engineering innovations across nearly every part of our foundation model development and infrastructure. This includes making Gemini 1.5 more efficient to train and serve, with a new Mixture-of-Experts (MoE) architecture.
Gemini 1.5 Pro comes with a standard 128,000 token context window. But starting today, a limited group of developers and enterprise customers can try it with a context window of up to 1 million tokens via AI Studio and Vertex AI in private preview.
https://twit.tv/posts/inside-twit/club-shows-now-open-everyone
We are thrilled to announce that our Club TWiT shows are now available to everyone in audio form. That's right, you can now listen to your favorite shows anytime, anywhere, and it's all starting as early as the end of this week.
https://twit.tv/posts/inside-twit/twits-lesser-known-rss-feeds
Subscribed!
Many people are unaware that TWiT also has RSS feeds designed for news aggregators like Feedly, NetNewsWire, Mozilla Thunderbird, and Akregator. These feeds are not meant for podcast apps but are specifically designed for news aggregators. You can copy any of the RSS feed links below into your RSS feed reader of choice and get updates on the latest TWiT blog posts, articles, or podcasts as soon as they are published.
https://matthiasott.com/notes/we-love-rss
What makes RSS so powerful is that it is an open format. RSS is one of the reasons the blogosphere grew so rapidly and it is the reason why podcasting exploded: because this open format allowed everyone to participate by simply publishing a feed anywhere on the web, without being restricted by platform requirements, closed APIs, and paywalls. And this superpower is also why RSS is having a renaissance today: it allows everyone to subscribe to, share, syndicate, and cross-post content on the open web. And it also enables creative automations using tools like Zapier, IFTTT, Huggin, or n8n.
There is no denying that RSS is having a moment again. Not only because it allows us all to improve the discoverability of our work and explore online content in a personalized and deliberate way, but also because it remains one of the most powerful and influential technologies of the open web. RSS already is the cornerstone of many open technology systems like podcasting, which can’t be owned and controlled by any one company. As Anil Dash notes, this alone is radical, because it is the triumph of exactly the kind of technology that's supposed to be impossible: open and empowering tech that allows people to have ownership over their work and their relationship with their audience.
https://www.theverge.com/24067997/robots-txt-ai-text-file-web-crawlers-spiders
For three decades, a tiny text file has kept the internet from chaos. This text file has no particular legal or technical authority, and it’s not even particularly complicated. It represents a handshake deal between some of the earliest pioneers of the internet to respect each other’s wishes and build the internet in a way that benefitted everybody. It’s a mini constitution for the internet, written in code.
It’s called robots.txt and is usually located at yourwebsite.com/robots.txt. That file allows anyone who runs a website — big or small, cooking blog or multinational corporation — to tell the web who’s allowed in and who isn’t. Which search engines can index your site? What archival projects can grab a version of your page and save it? Can competitors keep tabs on your pages for their own files? You get to decide and declare that to the web.
It’s not a perfect system, but it works. Used to, anyway. For decades, the main focus of robots.txt was on search engines; you’d let them scrape your site and in exchange they’d promise to send people back to you. Now AI has changed the equation: companies around the web are using your site and its data to build massive sets of training data, in order to build models and products that may not acknowledge your existence at all.
The robots.txt file governs a give and take; AI feels to many like all take and no give. But there’s now so much money in AI, and the technological state of the art is changing so fast that many site owners can’t keep up. And the fundamental agreement behind robots.txt, and the web as a whole — which for so long amounted to “everybody just be cool” — may not be able to keep up either.
https://devblogs.microsoft.com/commandline/introducing-sudo-for-windows/
Sudo for Windows is a new way for users to run elevated commands directly from an unelevated console session. It is an ergonomic and familiar solution for users who want to elevate a command without having to first open a new elevated console.
We are also excited to announce that we are open-sourcing this project here on GitHub!
https://www.microsoft.com/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
Perhaps the greatest challenge – and opportunity – of LLMs is extending their powerful capabilities to solve problems beyond the data on which they have been trained, and to achieve comparable results with data the LLM has never seen. This opens new possibilities in data investigation, such as identifying themes and semantic concepts with context and grounding on datasets. In this post, we introduce GraphRAG, created by Microsoft Research, as a significant advance in enhancing the capability of LLMs.
https://everynoise.com/engenremap.html
Every Noise at Once is an ongoing attempt at an algorithmically-generated, readability-adjusted scatter-plot of the musical genre-space, based on data tracked and analyzed for 6,291 genre-shaped distinctions by Spotify as of 2023-11-19. The calibration is fuzzy, but in general down is more organic, up is more mechanical and electric; left is denser and more atmospheric, right is spikier and bouncier.
https://www.nvidia.com/ai-on-rtx/chat-with-rtx-generative-ai/
Chat With RTX is a demo app that lets you personalize a GPT large language model (LLM) connected to your own content—docs, notes, videos, or other data. Leveraging retrieval-augmented generation (RAG), TensorRT-LLM, and RTX acceleration, you can query a custom chatbot to quickly get contextually relevant answers. And because it all runs locally on your Windows RTX PC or workstation, you’ll get fast and secure results.
https://github.com/Stability-AI/StableCascade
Stable Cascade consists of three models: Stage A, Stage B and Stage C, representing a cascade for generating images, hence the name "Stable Cascade". Stage A & B are used to compress images, similarly to what the job of the VAE is in Stable Diffusion. However, as mentioned before, with this setup a much higher compression of images can be achieved. Furthermore, Stage C is responsible for generating the small 24 x 24 latents given a text prompt. The following picture shows this visually. Note that Stage A is a VAE and both Stage B & C are diffusion models.
For this release, we are providing two checkpoints for Stage C, two for Stage B and one for Stage A. Stage C comes with a 1 billion and 3.6 billion parameter version, but we highly recommend using the 3.6 billion version, as most work was put into its finetuning. The two versions for Stage B amount to 700 million and 1.5 billion parameters. Both achieve great results, however the 1.5 billion excels at reconstructing small and fine details. Therefore, you will achieve the best results if you use the larger variant of each. Lastly, Stage A contains 20 million parameters and is fixed due to its small size.
https://openai.com/blog/memory-and-new-controls-for-chatgpt
We’re testing memory with ChatGPT. Remembering things you discuss across all chats saves you from having to repeat information and makes future conversations more helpful.
You're in control of ChatGPT's memory. You can explicitly tell it to remember something, ask it what it remembers, and tell it to forget conversationally or through settings. You can also turn it off entirely.
We are rolling out to a small portion of ChatGPT free and Plus users this week to learn how useful it is. We will share plans for broader roll out soon.
https://gvwilson.github.io/sql-tutorial/
notes and working examples that instructors can use to perform a lesson
https://www.theverge.com/2024/2/6/24063705/whatsapp-interoperability-plans-eu-dma
WhatsApp, like many other major tech platforms, will have to make some significant changes to comply with the European Union’s Digital Markets Act (DMA). One of those changes is interoperability with other messaging platforms...
The shift toward interoperability will first include text messages, images, voice messages, videos, and files sent from one person to another. In theory, this would allow users to chat with people on WhatsApp through third-party apps, like iMessage, Telegram, Google Messages, and Signal, and vice versa.
As noted by Wired, WhatsApp wants the messaging services it connects with to use the same Signal Protocol to encrypt messages. Meta is also open to apps using alternate encryption protocols so long as companies can prove “they reach the security standards that WhatsApp outlines in its guidance.” The third-party services will also have to sign a contract with Meta before they plug into WhatsApp, with more details about the agreement coming in March.
https://blog.nomic.ai/posts/nomic-embed-text-v1
We're excited to announce the release of Nomic Embed, the first
- Open source
- Open data
- Open training code
- Fully reproducible and auditable
https://blog.langchain.dev/opengpts/
A little over two months ago, on the heels of OpenAI dev day, we launched OpenGPTs: a take on what an open-source GPT store may look like. It was powered by an early version of LangGraph - an extension of LangChain aimed at building agents as graphs. At the time, we did not highlight this new package much, as we had not publicly launched it and were still figuring out the interface. We finally got around to launching LangGraph two weeks ago, and over the past weekend we updated OpenGPTs to fully use LangGraph (as well as added some new features). We figure now is as good of time as any to do a technical deep-dive on OpenGPTs and what powers it.
In this blog, we will talk about:
- MessageGraph: A particular type of graph that OpenGPTs runs on
- Cognitive architectures: What the 3 different types of cognitive architectures OpenGPTs supports are, and how they differ
- Persistence: How persistence is baked in OpenGPTs via LangGraph checkpoints.
- Configuration: How we use LangChain primitives to configure all these different bots.
- New models: what new models we support
- New tools: what new tools we support
- astream_events: How we are using this new method to stream tokens and intermediate steps
https://www.npr.org/2024/01/26/1226810515/tiny-desk-concert-thee-sacred-souls
San Diego-based trio Thee Sacred Souls made its mark at the Tiny Desk with satin vocals and vintage melodies. Paying homage to southern California Latino culture meeting American soul roots, the group's sweet fusion melodies brought history and love into the space.
https://blog.rwkv.com/p/eagle-7b-soaring-past-transformers
Eagle 7B is a 7.52B parameter model that:
Built on the RWKV-v5 architecture (a linear transformer with 10-100x+ lower inference cost)
Ranks as the world’s greenest 7B model (per token)
Trained on 1.1 Trillion Tokens across 100+ languages
Outperforms all 7B class models in multi-lingual benchmarks
Approaches Falcon (1.5T), LLaMA2 (2T), Mistral (>2T?) level of performance in English evals
Trade blows with MPT-7B (1T) in English evals
All while being an “Attention-Free Transformer”
Is a foundation model, with a very small instruct tune - further fine-tuning is required for various use cases!
We are releasing RWKV-v5 Eagle 7B, licensed as Apache 2.0 license, under the Linux Foundation, and can be used personally or commercially without restrictions
https://www.youtube.com/watch?v=nOxKexn3iBo
In this comprehensive video tutorial, Jeremy Howard from answer.ai demystifies the process of programming NVIDIA GPUs using CUDA, and simplifies the perceived complexities of CUDA programming. Jeremy emphasizes the accessibility of CUDA, especially when combined with PyTorch's capabilities, allowing for programming directly in notebooks rather than traditional compilers and terminals. To make CUDA more approachable to Python programmers, Jeremy shows step by step how to start with Python implementations, and then convert them largely automatically to CUDA. This approach, he argues, simplifies debugging and development.
The tutorial is structured in a hands-on manner, encouraging viewers to follow along in a Colab notebook. Jeremy uses practical examples, starting with converting an RGB image to grayscale using CUDA, demonstrating the process step-by-step. He further explains the memory layout in GPUs, emphasizing the differences from CPU memory structures, and introduces key CUDA concepts like streaming multi-processors and CUDA cores.
Jeremy then delves into more advanced topics, such as matrix multiplication, a critical operation in deep learning. He demonstrates how to implement matrix multiplication in Python first and then translates it to CUDA, highlighting the significant performance gains achievable with GPU programming. The tutorial also covers CUDA's intricacies, such as shared memory, thread blocks, and optimizing CUDA kernels.
The tutorial also includes a section on setting up the CUDA environment on various systems using Conda, making it accessible for a wide range of users.
This is lecture 3 of the "CUDA Mode" series (but you don't need to watch the others first). The notebook is available in the lecture3 folder here: https://github.com/cuda-mode/lecture2...
https://ollama.ai/blog/python-javascript-libraries
The initial versions of the Ollama Python and JavaScript libraries are now available:
Ollama Python Library
Ollama JavaScript Library
Both libraries make it possible to integrate new and existing apps with Ollama in a few lines of code, and share the features and feel of the Ollama REST API.
https://www.theverge.com/2024/1/25/24050445/google-cloud-hugging-face-ai-developer-access
Google Cloud’s new partnership with AI model repository Hugging Face is letting developers build, train, and deploy AI models without needing to pay for a Google Cloud subscription. Now, outside developers using Hugging Face’s platform will have “cost-effective” access to Google’s tensor processing units (TPU) and GPU supercomputers, which will include thousands of Nvidia’s in-demand and export-restricted H100s.
Google said that Hugging Face users can begin using the AI app-building platform Vertex AI and the Kubernetes engine that helps train and fine-tune models “in the first half of 2024.”
https://openai.com/blog/new-embedding-models-and-api-updates
We are launching a new generation of embedding models, new GPT-4 Turbo and moderation models, new API usage management tools, and soon, lower pricing on GPT-3.5 Turbo.
https://fosdem.org/2024/schedule/events/
Lots of great sessions. I'm looking forward to the sessions on the following topics:
- Matrix
- AI
- Nix / NixOS
- Software Defined Radio (SDR) & Amateur Radio
- Modern Email
- Collaboration & Content Management
https://openai.com/research/microscope
We’re introducing OpenAI Microscope, a collection of visualizations of every significant layer and neuron of eight vision “model organisms” which are often studied in interpretability. Microscope makes it easier to analyze the features that form inside these neural networks, and we hope it will help the research community as we move towards understanding these complicated systems.
https://inteltechniques.com/blog/2024/01/05/unredacted-magazine-status/
...the magazine is not 'dead'. Much like the podcast, it is simply on a hiatus. Many people falsely report online that the podcast and magazine are officially never coming back, which is contradictory to my previous post. The reason there have been no issues of the magazine is simply a lack of submissions.
The magazine is a community-driven product. Without the community driving it, it will go nowhere. If you would like to submit an article, please email it to staff@unredactedmagazine.com.
Sponsors are lined up to pay the costs and keep the content free, but there lies other problems. We received constant complaints about having sponsors. Most readers demanded free content without ads, which is unrealistic.
We have considered a small fee per issue, but the credit card fraud which comes with that is an even bigger issue. What is the solution? I do not know yet. If the articles pour in, I will figure it out.

Interesting points.
https://nightshade.cs.uchicago.edu/
Nightshade, a tool that turns any image into a data sample that is unsuitable for model training. More precisely, Nightshade transforms images into "poison" samples, so that models training on them without consent will see their models learn unpredictable behaviors that deviate from expected norms, e.g. a prompt that asks for an image of a cow flying in space might instead get an image of a handbag floating in space.
https://dayoneapp.com/blog/introducing-shared-journals/
Shared Journals are a private space for your closest friends and family to shared life updates and memories. Shared Journals introduce a new dimension to journaling, offering a unique way to share your personal stories and experiences with up to 30 selected individuals, while keeping your individual entries private and secure.
Awesome! When I was writing the post Private Social Media yesterday, I wasn't aware that these had already launched. I knew they were in beta but it's great to see they're now generally available. I'll have to give them a try.
https://stability.ai/news/introducing-stable-lm-2
Stable LM 2 1.6B is a state-of-the-art 1.6 billion parameter small language model trained on multilingual data in English, Spanish, German, Italian, French, Portuguese, and Dutch.
This model's compact size and speed lower hardware barriers, allowing more developers to participate in the generative AI ecosystem.
In addition to the pre-trained and instruction-tuned version, we release the last checkpoint before the pre-training cooldown. We include optimizer states to facilitate developers in fine-tuning and experimentation. Data details will be provided in the upcoming technical report.
Stable LM 2 1.6B can be used now both commercially and non-commercially with a Stability AI Membership & you can test the model on Hugging Face.
https://www.theverge.com/24036427/rss-feed-reader-best
RSS readers allow you to collect the articles of specific sources in one app, making it a lot easier to find the content you’re interested in without crawling through a lot of noise.
Whatever RSS feed reader you choose, it’s worth it to try at least one or two. This way, you can keep up with news from your favorite sources without depending on the chaos that is your email account or the random opinions from TikTok.
Great overview of the various RSS feed readers out there.
it’s increasingly clear that the early success of the Vision Pro, and much of the answer to the question of what this headset is actually for, will come from a single app: Safari.
That’s right, friends. Web browsers are back.
...at least at first, the open web is Apple’s best chance to make its headset a winner. Because at least so far, it seems developers are not exactly jumping to build new apps for Apple’s new platform.
Some of the high-profile companies that have announced they’re not yet building apps for the Vision Pro and its visionOS platform — Netflix, Spotify, YouTube, and others — are the very same ones that have loudly taken issue with how Apple runs the App Store.
But what if you don’t need the App Store to reach Apple users anymore? All this corporate infighting has the potential to completely change the way we use our devices, starting with the Vision Pro.
...we’ve all stopped opening websites and started tapping app icons, but the age of the URL might be coming back.
If you believe the open web is a good thing, and that developers should spend more time on their web apps and less on their native ones, this is a big win for the future of the internet.
The problem is, it’s happening after nearly two decades of mobile platforms systematically downgrading and ignoring their browsing experience...Mobile platforms treat browsers like webpage viewers, not app platforms, and it shows.
There are some reasons for hope, though...the company appears to be still invested in making Safari work.
Safari for visionOS will also come with some platform-specific features: you’ll be able to open multiple windows at the same time and move them all around in virtual space.
With a good browser and powerful PWAs, many users might mostly not notice the difference between opening the Spotify app and going to Spotify.com. That’s a win for the whole web.
here’s the real question for Apple: which is more important, getting the Vision Pro off to a good start or protecting the sanctity of its App Store control at all costs? As Apple tries to create a platform shift to face computers, I’m not sure it can have it both ways.
Great article by David Pierce. As part of my website stats, I should probably start also counting authors I reference since many of the articles from the Verge I've previously linked to are written by David.
As someone who accesses services - "apps" - primarily through the web browser on desktop, this is exciting to see. While native apps have their advantages, the types of cross-platform connected experiences that can be delivered through the browser can't be ignored. First-class support for browsers in various platforms can only make these experiences even better. With more folks building their own platforms on the web on top of open standards that have been around for decades, I'm excited for the future of the web.
https://blog.bytebytego.com/p/how-discord-serves-15-million-users
In early summer 2022, the Discord operations team noticed unusually high activity on their dashboards. They thought it was a bot attack, but it was legitimate traffic from MidJourney - a new, fast-growing community for generating AI images from text prompts.
To use MidJourney, you need a Discord account. Most MidJourney users join one main Discord server. This server grew so quickly that it soon hit Discord’s old limit of around 1 million users per server.
This is the story of how the Discord team creatively solved this challenge.
Discord’s real-time messaging backend is built with Elixir. Elixir runs on the BEAM virtual machine. BEAM was created for Erlang - a language optimized for large real-time systems requiring rock-solid reliability and uptime.
A key capability BEAM provides is extremely lightweight parallel processes. This enables a single server to efficiently run tens or hundreds of thousands of processes concurrently.
Elixir brings friendlier, Ruby-inspired syntax to the battle-tested foundation of BEAM. Combined they make it much easier to program massively scalable, fault-tolerant systems.
So by leveraging BEAM's lightweight processes, the Elixir code powering Discord can "fan out" messages to hundreds of thousands of users around the world concurrently. However, limits emerge as communities grow larger.
A protocol for peer-to-peer data stores. The best parts? Fine-grained permissions, a keen approach to privacy, destructive edits, and a dainty bandwidth and memory footprint.
https://stability.ai/news/stable-code-2024-llm-code-completion-release
Stable Code 3B is a 3 billion parameter Large Language Model (LLM), allowing accurate and responsive code completion at a level on par with models such as CodeLLaMA 7b that are 2.5x larger.
Operates offline even without a GPU on common laptops such as a MacBook Air.
https://huyenchip.com//2024/01/16/sampling.html
ML models are probabilistic. Imagine that you want to know what’s the best cuisine in the world. If you ask someone this question twice, a minute apart, their answers both times should be the same. If you ask a model the same question twice, its answer can change.
This probabilistic nature makes AI great for creative tasks.
However, this probabilistic nature also causes inconsistency and hallucinations. It’s fatal for tasks that depend on factuality. Recently, I went over 3 months’ worth of customer support requests of an AI startup I advise and found that ⅕ of the questions are because users don’t understand or don’t know how to work with this probabilistic nature.
To understand why AI’s responses are probabilistic, we need to understand how models generate responses, a process known as sampling (or decoding). This post consists of 3 parts.
1. Sampling: sampling strategies and sampling variables including temperature, top-k, and top-p. 2. Test time sampling: sampling multiple outputs to help improve a model’s performance. 3. Structured outputs: how to get models to generate outputs in a certain format.
https://www.theverge.com/2024/1/9/24032155/youtube-podcast-rss-spotify-apple-audacy-bankruptcy
Today, YouTube at very long last debuts RSS integration.
This means more hosts saying "...or wherever you get your podcasts." 🙂
By now most internet users know their online activity is constantly tracked.
But what is the scale of this surveillance? Judging from data collected by Facebook and newly described in a unique study by non-profit consumer watchdog Consumer Reports, it’s massive, and examining the data may leave you with more questions than answers.
Using a panel of 709 volunteers who shared archives of their Facebook data, Consumer Reports found that a total of 186,892 companies sent data about them to the social network. On average, each participant in the study had their data sent to Facebook by 2,230 companies. That number varied significantly, with some panelists’ data listing over 7,000 companies providing their data.
What Exactly Does This Data Contain?
The data examined by Consumer Reports in this study comes from two types of collection: events and custom audiences. Both categories include information about what people do outside of Meta’s platforms.
Custom audiences allow advertisers to upload customer lists to Meta, often including identifiers like email addresses and mobile advertising IDs...
The other category of data collection, “events,” describes interactions that the user had with a brand, which can occur outside of Meta’s apps and in the real world. Events can include visiting a page on a company’s website, leveling up in a game, visiting a physical store, or purchasing a product...
How Can I See My Data?
Facebook users can browse through the list of companies that have sent their data to Facebook by going to: [https://accountscenter.facebook.com/info_and_permissions](https://accountscenter.facebook.com/info_and_permissions)
https://simonwillison.net/2024/Jan/17/oxide-and-friends/
I recorded an episode of the Oxide and Friends podcast on Monday, talking with Bryan Cantrill and Adam Leventhal about Open Source LLMs.
Too important for a small group to control...
This technology is clearly extremely important to the future of all sorts of things that we want to do.
I am totally on board with it. There are people who will tell you that it’s all hype and bluster. I’m over that. This stuff’s real. It’s really useful.
It is far too important for a small group of companies to completely control this technology. That would be genuinely disastrous. And I was very nervous that was going to happen, back when it was just OpenAI and Anthropic that had the only models that were any good, that was really nerve-wracking.
Today I’m not afraid of that at all, because there are dozens of organizations now that have managed to create one of these things...
On LLMs for learning...
One of the most exciting things for me about this technology is that it’s a teaching assistant that is always available to you.
You know that thing where you’re learning—especially in a classroom environment—and you miss one little detail and you start falling further and further behind everyone else because there was this one little thing you didn’t quite catch, and you don’t want to ask stupid questions?
You can ask stupid questions of ChatGPT anytime you like and it can help guide you through to the right answer.
That’s kind of a revelation.
https://arxiv.org/abs/2301.12662
We present SingSong, a system that generates instrumental music to accompany input vocals, potentially offering musicians and non-musicians alike an intuitive new way to create music featuring their own voice. To accomplish this, we build on recent developments in musical source separation and audio generation. Specifically, we apply a state-of-the-art source separation algorithm to a large corpus of music audio to produce aligned pairs of vocals and instrumental sources. Then, we adapt AudioLM (Borsos et al., 2022) -- a state-of-the-art approach for unconditional audio generation -- to be suitable for conditional "audio-to-audio" generation tasks, and train it on the source-separated (vocal, instrumental) pairs. In a pairwise comparison with the same vocal inputs, listeners expressed a significant preference for instrumentals generated by SingSong compared to those from a strong retrieval baseline. Sound examples at this https URL
AI can now help you create a backing track to all the songs you make up about your pets.
https://www.theverge.com/2024/1/17/24041330/notion-calendar-app
After acquiring Cron in 2022, Notion is bringing the calendar app fully into its all-in-one workspace.
The big new feature coming with the rebranding is Notion integration. If you or your company uses Notion, you’ll be able to create or link Notion documents inside a calendar invite. If you have a database filled with due dates, you can add that as a calendar to Notion Calendar. It sounds like a much better way to handle agendas and notes than sending them around before and after a meeting or hunting for them in your Slack. Putting everything in the calendar event is a good move.
This is one of the reasons I like org-mode in Emacs. Being able to annotate documents with timestamps and deadlines that show up and you can organize inside the Agenda view is so powerful. The integrations and learning curve is steeper compared to a tool like Notion but I find it simple and powerful enough for GTD-style workflows, I'd have a hard time moving. I have yet to use AnyType, so maybe after trying that, I choose to shift some of my workflows there.
OpenMentions is a project designed to use Webmentions and ActivityPub for topical content discovery. The site is organised along the lines of a hierarchy of topics going from broad to fine. This we call OpenTopic – the idea being that many sites could host the full collection of topics so that the loss of any one site is not the loss of all topics.
The intention is that this site should own nothing and that topic hierarchies are organic and discoverable.
We are disclosing LeftoverLocals: a vulnerability that allows recovery of data from GPU local memory created by another process on Apple, Qualcomm, AMD, and Imagination GPUs. LeftoverLocals impacts the security posture of GPU applications as a whole, with particular significance to LLMs and ML models run on impacted GPU platforms. By recovering local memory—an optimized GPU memory region—we were able to build a PoC where an attacker can listen into another user’s interactive LLM session (e.g., llama.cpp) across process or container boundaries
https://blog.thenewoil.org/easy-ways-to-improve-your-privacy-and-security-in-2024
Every year, I like to remind everyone to go back to the basics. For those who are new to privacy and security and may be trying to create some new, positive habits, this serves as a great entry point. For veteran privacy enthusiasts, the basics form our foundation for more advanced techniques later, making it imperative to ensure we cover all those bases. So in that spirit, let’s all pause – wherever we are in our privacy journeys – to do a quick check and make sure we’ve got the basics covered. If you’re one of those new people I mentioned, welcome! But also know that this post is packed with information, so try not to get overwhelmed. Maybe bookmark this post and do one thing per day or something like that.
Strong Passwords...
Multi-Factor Authentication (MFA)...
Regular Software Updates...
Secure Your Wi-Fi Network...
Be Cautious with Communications...
Review App Permissions...
Review Your Account Settings...
Secure Browsing Habits...
Device Security...
Review Financial Statements...
Educate Yourself...
https://sites.google.com/view/lastunen/ai-for-economists
This page contains example prompts and responses intended to showcase how generative AI, namely LLMs like GPT-4, can benefit economists.
Example prompts are shown from six domains: ideation and feedback; writing; background research; coding; data analysis; and mathematical derivations.
The framework as well as some of the prompts and related notes come from Korinek, A. 2023. “Generative AI for Economic Research: Use Cases and Implications for Economists“, Journal of Economic Literature, 61 (4): 1281–1317.
Each application area includes 1-3 prompts and responses from an LLM, often from the field of development economics, along with brief notes. The prompts will be updated periodically.
Smartphones and physical keyboards aren’t a combination we think of often, but Clicks for iPhone is trying to bring that back with a new keyboard case that’s extremely good.
Wishful thinking on my end but I'd buy a Blackberry-like device. Not a "smartphone", but an internet-connected device with all the phone capabilities that has a physical keyboard.
Goblin band is an attempt to replicate the colletive creative energy that happens on tumblr and take it to the fediverse
https://clarkesworldmagazine.com/
Clarkesworld is a monthly science fiction and fantasy magazine first published in October 2006. Each issue contains interviews, thought-provoking articles, and between six and eight works of original fiction.
https://twitter.com/ChicanoBatman/status/1746940313678299500
Starting off the year right with new Chicano Batman!
“Fly” is yours 1/23 🕊 And this is just the beginning!

https://hackaday.com/2023/12/20/floss-weekly-episode-762-spilling-the-tea/
We’re excited to announce that Hackaday is the new home of FLOSS Weekly, a long-running podcast about free, libre, and open-source software! The TWiT network hosted the podcast for an incredible seventeen years, but due to some changes on their end, they recently had to wind things down. They were gracious enough to let us pick up the torch, with Jonathan Bennett now taking over hosting duties.
That didn't take long. Last month I learned FLOSS Weekly was ending on the TWiT network. It's great to see it has found a new home in Hackaday! Time to update the RSS feeds and podroll.
Every is a daily newsletter founded in 2020. Every day, we publish a long-form essay to make you smarter about technology, productivity, and AI.
https://citationneeded.news/substack-to-self-hosted-ghost/
I have found myself with a roughly $103/mo setup...
However, more important to me than the exact price is the degree of control I have over my own not-a-platform...
I realize that this is...a lot. If you are a newsletter writer looking to flee the Substack ship, please don't let this discourage you.
Love seeing this! Whether through self-hosted or hosted options, I hope more people get to experience the benefits of owning their own platform.
https://www.w3.org/Provider/Style/URI
Keeping URIs so that they will still be around in 2, 20 or 200 or even 2000 years is clearly not as simple as it sounds. However, all over the Web, webmasters are making decisions which will make it really difficult for themselves in the future. Often, this is because they are using tools whose task is seen as to present the best site in the moment, and no one has evaluated what will happen to the links when things change. The message here is, however, that many, many things can change and your URIs can and should stay the same. They only can if you think about how you design them.
https://blog.benjojo.co.uk/post/who-hosts-the-fediverse-instances
Here we can see that Fastly and Cloudflare make up over 50% of the entire fediverse network.
...for the population using Cloudflare, a fair number of them (30%) appear to be hosting the instances behind a home broadband connection.
...the German hosting provider Hetzner hosts over 51% of the entire network!
https://thenewstack.io/more-than-an-openai-wrapper-perplexity-pivots-to-open-source/
...Perplexity has become a surprisingly strong player in a market otherwise dominated by OpenAI, Microsoft, Google and Meta.
At its core, Perplexity is a search engine.
...over the past year, Perplexity has evolved rapidly. It now has its own search index and has built its own LLMs based on open source models. They’ve also begun to combine their proprietary technology products. At the end of November, Perplexity announced two new “online LLMs” — LLMs combined with a search index — called pplx-7b-online and pplx-70b-online. They were built on top of the open source models mistral-7b and llama2-70b.
Using open source models has been critical for the growth of Perplexity.
...the default Perplexity model still relies on GPT 3.5 (and a dash of LLaMA-2). But the intention is to move away from that long-standing reliance on OpenAI for its base model.
marimo is an open-source reactive notebook for Python — reproducible, git-friendly, executable as a script, and shareable as an app.
https://shellsharks.com/indieweb
Principle Mechanics
This section does not provide exhaustive coverage of how to implement IndieWeb functionality. Instead, I simply summarize five core primitives which I feel comprise an IndieWeb site. For a more official gauge on where a site scores within the IndieWeb spectrum, consider leveraging IndieMark!
Hosting: You need a place to host your site and store your content. There are a lot of great options out there. Ideally, choose one that allows you the ability to make some under-the-hood changes and does not limit your content portability.
Syndication: Share your content with the world! There are two preferred methods for syndication, PESOS and POSSE. This resource does a great job explaining both! For more examples of how this is done, check this and this out. RSS is a great starting point for helping others subscribe to new content on your site.
Writing: Though your site could simply serve as a more static point/identity on the web, with little to no “content” being regularly added, I recommend writing!
Interactivity: One of the more advanced concepts within the IndieWeb world, the ability to bake in native comments, replies, likes, etc is a greay way to build community. This interactivity helps mitigate reliance on centralized social networks for communication within Indie communities. One example of IndieWeb interactivity is Webmentions.
Identity: Make it unique, make it fun, make it yours. The corporate web is sterile and suffocating. Let’s bring back the whimsy of the old web.
https://www.alexirpan.com/2024/01/10/ai-timelines-2024.html
...computers are useful, ML models are useful, and even if models fail to scale, people will want to fit GPT-4 sized models on their phone. It seems reasonable to assume the competing factions will figure something out.
Data seems like the harder question. (Or at least the one I feel qualified talking about.) We have already crossed the event horizon of trying to train on everything on the Internet. It’s increasingly difficult for labs to differentiate themselves on publicly available data. Differentiation is instead coming from non-public high-quality data to augment public low-quality data.
All the scaling laws have followed power laws so far, including dataset size. Getting more data by hand doesn’t seem good enough to cross to the next thresholds. We need better means to get good data.
A long time ago, when OpenAI still did RL in games / simulation, they were very into self-play. You run agents against copies of themselves, score their interactions, and update the models towards interactions with higher reward. Given enough time, they learn complex strategies through competition.
I think it’s possible we’re at the start of a world where self-play or self-play-like ideas work to improve LLM capabilities. Drawing an analogy, the environment is the dialogue, actions are text generated from an LLM, and the reward is from whatever reward model you have. Instead of using ground truth data, our models may be at a point where they can generate data that’s good enough to train on.
https://openai.com/blog/introducing-the-gpt-store
It’s been two months since we announced GPTs, and users have already created over 3 million custom versions of ChatGPT. Many builders have shared their GPTs for others to use. Today, we're starting to roll out the GPT Store to ChatGPT Plus, Team and Enterprise users so you can find useful and popular GPTs.
https://tonybaloney.github.io/posts/python-gets-a-jit.html
In late December 2023 (Christmas Day to be precise), CPython core developer Brandt Bucher submitted a little pull-request to the Python 3.13 branch adding a JIT compiler.
I woke up today...and decided I was going to delete all the apps off my iPhone.
If I didn’t need it to do a specialized function? Gone, poof. I decided to just use websites and bookmarks instead.
The websites worked just fine.
...websites are just badly designed these days, especially with using a screen reader on a mobile device. I can’t quite describe it, because mobile web browsers aren’t really well designed either, so it makes the website worse because it doesn’t even render all elements as smoothly as on desktop.
Even though there are problems, I’m honestly glad I deleted almost all my apps off my phone and started to pin websites to my home screen more. For one thing, it cuts down on notifications. it’s super freeing to not get a random notification because you didn’t open the app in a day, so the app pings you to say hey I’m still here please pay attention to me, I feel lonely, and nobody will give me animals to snuggle with.
With pinned websites, my phone is faster and my home screen is much more organized as well.
I did this a few years ago. Websites work just fine for almost everything I need to do. The main benefits I noticed:
- Less distractions
- More real estate when viewing websites on laptop / desktop
- Less apps to drain the battery when running on the background
- More restricted access / permissions (i.e. websites don't need unrestricted access to my contacts or other information on my phone)
Better PWA support on mobile platforms would go a long way here to better balance between apps and websites. In the meantime though, pinning websites and websites overall work just fine for most things I need to do day-to-day.
https://www.tiobe.com/tiobe-index/
For the first time in the history of the TIOBE index, C# has won the programming language of the year award. Congratulations! C# has been a top 10 player for more than 2 decades and now that it is catching up with the big 4 languages, it won the well-deserved award by being the language with the biggest uptick in one year (+1.43%).
Exciting to see F# almost break into the Top 20 at number 22 with 0.77%.

...owning the address where your audience finds you is important. It allows you to be mobile, nimble, and without attached strings. It helps you show off all the things and places you want folks to see because you can put all these URLs on your /feeds page. It’s user-friendly in more ways than one (pretty cool how you can make all those URLs human-readable, huh?).
...it means your audience never has to think about how they’re going to get your stuff.
This is a great idea. I've written before about owning your links. Today, that's how I expose many of my links in the contact page. For example, to access my Mastodon profile, instead of going to the actual URL, you can just visit lqdev.me/mastodon which redirects to the actual URL. If tomorrow I choose to change where and how my Mastodon presence is hosted, the URL doesn't have to change. However, I haven't done the same for my RSS links. Recently I've been thinking about restructuring my website, specifically my microblog feed which includes notes and responses. Today, the RSS urls are coupled to the folder structure on my website which is subject to change and isn't flexible. By setting up more user-friendly and stable RSS urls through redirection, that wouldn't be an issue and readers wouldn't have to change the RSS URL they use.

https://ma.tt/2024/01/birthday-gift/
the gift I most want for my 40th is something everyone can do.
I want you to blog.
Publish a post. About anything! It can be long or short, a photo or a video, maybe a quote or a link to something you found interesting. Don’t sweat it. Just blog. Share something you created, or amplify something you enjoyed. It doesn’t take much. The act of publishing will be a gift for you and me.
That’s it! No wrapping paper or bows. Just blogs and blogs and blogs, each unique and beautiful in its own way.
https://bix.blog/2024/01/01/the-year-for-blogging-to-pump-up-the-volume/
There’s been a lot of pontificating lately that the web is ripe for a blogging renaissance, wishing for it to be true. Much of it from people who don’t seem to notice that’s it’s already begun. Maybe they don’t anymore know quite where to look. Maybe the sorts of blogging they’re seeing isn’t what they mean. (To the blognoscenti, do things like “wordvomits” count?) If you haven’t seen it, either, that’s okay. All you have to do is choose to be a part of it. There’s never been a better time: those who managed to monopolize our attentions and keep too many of us chattering for a few hundred characters at a time to the benefit of advertisers are losing their relevance.
I’m not one for making personal resolutions, but let me suggest one on behalf of the blogosphere: this is the year we pump up the volume.
Bring back self-hosted blogs, reinstall a feed reader, make your feed icon prominent on your blog. Blogs + Atom/RSS is the best decentralized social media system we've ever had!
And yes I am saying that as co-author of ActivityPub: self hosted blogs is the best decentralized social networking we've had
💯 💯 💯 💯 💯 💯
I think I've read about this somewhere before...
“All animals are equal, but some animals are more equal than others.” ― George Orwell, Animal Farm
“Four legs good, two legs bad.” ― George Orwell, Animal Farm
https://arxiv.org/abs/2310.07704
We introduce Ferret, a new Multimodal Large Language Model (MLLM) capable of understanding spatial referring of any shape or granularity within an image and accurately grounding open-vocabulary descriptions. To unify referring and grounding in the LLM paradigm, Ferret employs a novel and powerful hybrid region representation that integrates discrete coordinates and continuous features jointly to represent a region in the image. To extract the continuous features of versatile regions, we propose a spatial-aware visual sampler, adept at handling varying sparsity across different shapes. Consequently, Ferret can accept diverse region inputs, such as points, bounding boxes, and free-form shapes. To bolster the desired capability of Ferret, we curate GRIT, a comprehensive refer-and-ground instruction tuning dataset including 1.1M samples that contain rich hierarchical spatial knowledge, with 95K hard negative data to promote model robustness. The resulting model not only achieves superior performance in classical referring and grounding tasks, but also greatly outperforms existing MLLMs in region-based and localization-demanded multimodal chatting. Our evaluations also reveal a significantly improved capability of describing image details and a remarkable alleviation in object hallucination. Code and data will be available at this https URL
My posts have been...including more reviews of fancy travel hacked flights, tours and slow travel locations. Possibly as a result of this shift in topic – or possibly simply because blogging seems to be on its way out according to a few of my blogging peers – my comments section has been quieter lately. I talked about this in one of my monthly recaps with the spin that I didn’t realize I had come to rely on getting at least one comment per post to know that people (and not just bots 🙂 ) were reading my words and they weren’t floating into an abyss.
I didn’t want to be reliant on external validation when I had written this blog without it being public for years, and hadn’t realized I had come to rely on anything but the joy I get from writing it. So I was trying to grow after realizing that not receiving comments on multiple posts in a row bothered me for some reason. I’m going to do my best to not rely on that kind of feedback going forward and will continue to blog for the main reason I always have: for myself 🙂 .
I also followed a reader suggestion to add a “Like” button at the bottom of my posts (it’s after the “Share This” section and before the “Related” articles section) because readers said they don’t necessarily have something they want to comment, but that a Like button would help show there is still a human reading. All fair 🙂 .
🙋♂️ there's still a human reading your posts on this end 🙂
Also, today I learned there's a Guineafowl Pufferfish.

https://bsky.app/profile/bsky.app/post/3kh5rjl6bgu2i
I'm not as active on there, but feel free to subscribe to my Bluesky feed wherever you subscribe to feeds.
Also, if you have any feed recommendations, let me know.
📢 1.60 is rolling out now (3/5)
RSS feeds for profiles!
Access your posts via RSS by pasting your profile link into your RSS feed reader and it will automatically be discovered.

What was probably being said according to Copilot 😂
Cristiano, you need to listen to me, mate. You're wasting your time and money on those Apple products. They're overpriced, overrated, and outdated. They're nothing compared to the real champions of technology: Windows Phone and Zune. Trust me, I know what I'm talking about. I've used them both, and they're the best phone and MP3 player ever made. Let me tell you why. First of all, they had a sleek design, a smooth interface, and a unique tile system that was way ahead of its time. They were also compatible with Microsoft's ecosystem, which gave you access to Office, Xbox, and Bing. And don't get me started on the Zune Pass, which let you stream and download unlimited music for a low monthly fee. You can't beat that, mate. Second of all, they had no apps, no games, no support, and no market share. Wait, what? No, no, no, that's not a bad thing. That's a good thing. That means they were exclusive, elite, and original. They were not for the masses, they were for the class. They were not for the sheep, they were for the lions. They were not for the followers, they were for the leaders. They were not for the weak, they were for the strong. They were not for you, they were for me. And they can be for you too, if you have the courage, the vision, and the taste to switch to Windows Phone and Zune. I'm telling you, Cristiano, you're missing out on the best phone and MP3 player ever made. And I'm willing to prove it to you. I'll bet you a million euros that if you try them for a week, you'll never go back to your Apple products. What do you say? Are you man enough to take the challenge? Or are you too scared to face the truth? Come on, Cristiano, don't be a coward. Don't be a fool. Don't be a loser. Be a winner. Be a legend. Be a Windows Phone and Zune user.
https://sites.research.google/videopoet/
VideoPoet is a simple modeling method that can convert any autoregressive language model or large language model (LLM) into a high-quality video generator. It contains a few simple components:
- A pre-trained MAGVIT V2 video tokenizer and a SoundStream audio tokenizer transform images, video, and audio clips with variable lengths into a sequence of discrete codes in a unified vocabulary. These codes are compatible with text-based language models, facilitating an integration with other modalities, such as text.
- An autoregressive language model learns across video, image, audio, and text modalities to autoregressively predict the next video or audio token in the sequence.
- A mixture of multimodal generative learning objectives are introduced into the LLM training framework, including text-to-video, text-to-image, image-to-video, video frame continuation, video inpainting and outpainting, video stylization, and video-to-audio. Furthermore, such tasks can be composed together for additional zero-shot capabilities (e.g., text-to-audio).
This simple recipe shows that language models can synthesize and edit videos with a high degree of temporal consistency. VideoPoet demonstrates state-of-the-art video generation, in particular in producing a wide range of large, interesting, and high-fidelity motions. The VideoPoet model supports generating videos in square orientation, or portrait to tailor generations towards short-form content, as well as supporting audio generation from a video input.



https://mid-journey.ai/midjourney-v6-release/
The Dev Team gonna let the community test an alpha-version of Midjourney v6 model over the winter break, starting tonight, December 21st, 2023.
What’s new with the Midjourney v6 base model?
- Much more accurate prompt following as well as longer prompts,
- Improved coherence, and model knowledge,
- Improved image prompting and remix mode,
- Minor text drawing ability (you must write your text in “quotations” and --style raw or lower --stylize values may help)
- /imagine a photo of the text "Hello World!" written with a marker on a sticky note --ar 16:9 --v 6
- Improved upscalers, with both 'subtle‘ and 'creative‘ modes (increases resolution by 2x) (you’ll see buttons for these under your images after clicking U1/U2/U3/U4)
https://blog.langchain.dev/langchain-state-of-ai-2023/
What are people building?
Retrieval has emerged as the dominant way to combine your data with LLMs.
...42% of complex queries involve retrieval
...about 17% of complex queries are part of an agent.
Most used LLM Providers
OpenAI has emerged as the leading LLM provider of 2023, and Azure (with more enterprise guarantees) has seized that momentum well.
On the open source model side, we see Hugging Face (4th), Fireworks AI (6th), and Ollama (7th) emerge as the main ways users interact with those models.
OSS Model Providers
A lot of attention recently has been given to open source models, with more and more providers racing to host them at cheaper and cheaper costs. So how exactly are developers accessing these open source models?
We see that the people are mainly running them locally, with options to do so like Hugging Face, LlamaCpp, Ollama, and GPT4All ranking high.
Most used vector stores
Vectorstores are emerging as the primary way to retrieve relevant context.
...local vectorstores are the most used, with Chroma, FAISS, Qdrant and DocArray all ranking in the top 5.
Of the hosted offerings, Pinecone leads the pack as the only hosted vectorstore in the top 5. Weaviate follows next, showing that vector-native databases are currently more used than databases that add in vector functionality.
Of databases that have added in vector functionality, we see Postgres (PGVector), Supabase, Neo4j, Redis, Azure Search, and Astra DB leading the pack.
Most used embeddings
OpenAI reigns supreme
Open source providers are more used, with Hugging Face coming in 2nd most use
On the hosted side, we see that Vertex AI actually beats out AzureOpenAI
Top Advanced Retrieval Strategies
the most common retrieval strategy we see is not a built-in one but rather a custom one.
After that, we see more familiar names popping up:
- Self Query - which extracts metadata filters from user's questions
- Hybrid Search - mainly through provider specific integrations like Supabase and Pinecone
- Contextual Compression - which is postprocessing of base retrieval results
- Multi Query - transforming a single query into multiple, and then retrieving results for all
- TimeWeighted VectorStore - give more preference to recent documents
How are people testing?
83% of test runs have some form of feedback associated with them. Of the runs with feedback, they average 2.3 different types of feedback, suggesting that developers are having difficulty finding a single metric to rely entirely on, and instead use multiple different metrics to evaluate.
...the majority of them use an LLM to evaluate the outputs. While some have expressed concern and hesitation around this, we are bullish on this as an approach and see that in practice it has emerged as the dominant way to test.
...nearly 40% of evaluators are custom evaluators. This is in line with the fact that we've observed that evaluation is often really specific to the application being worked on, and there's no one-size-fits-all evaluator to rely on.
What are people testing?
...most people are still primarily concerned with the correctness of their application (as opposed to toxicity, prompt leakage, or other guardrails
...low usage of Exact Matching as an evaluation technique [suggests] that judging correctness is often quite complex (you can't just compare the output exactly as is)
https://lea.verou.me/blog/2023/eigensolutions/
tl;dr: Overfitting happens when solutions don’t generalize sufficiently and is a hallmark of poor design. Eigensolutions are the opposite: solutions that generalize so much they expose links between seemingly unrelated use cases. Designing eigensolutions takes a mindset shift from linear design to composability.
The eigensolution is a solution that addresses several key use cases, that previously appeared unrelated.
...it takes a mindset shift, from the linear Use case → Idea → Solution process to composability. Rather than designing a solution to address only our driving use cases, step back and ask yourself: can we design a solution as a composition of smaller, more general features, that could be used together to address a broader set of use cases?
Contrary to what you may expect, eigensolutions can actually be quite hard to push to stakeholders:
- Due to their generality, they often require significantly higher engineering effort to implement. Quick-wins are easier to sell: they ship faster and add value sooner. In my 11 years designing web technologies, I have seen many beautiful, elegant eigensolutions be vetoed due to implementation difficulties in favor of far more specific solutions — and often this was the right decision, it’s all about the cost-benefit.
- Eigensolutions tend to be lower level primitives, which are more flexible, but can also involve higher friction to use than a solution that is tailored to a specific use case.
Eigensolutions tend to be lower level primitives. They enable a broad set of use cases, but may not be the most learnable or efficient way to implement all of them, compared to a tailored solution. In other words, they make complex things possible, but do not necessarily make common things easy.
Instead of implementing tailored solutions ad-hoc (risking overfitting), they can be implemented as shortcuts: higher level abstractions using the lower level primitive. Done well, shortcuts provide dual benefit: not only do they reduce friction for common cases, they also serve as teaching aids for the underlying lower level feature. This offers a very smooth ease-of-use to power curve: if users need to go further than what the shortcut provides, they can always fall back on the lower level primitive to do so.
In an ideal world, lower level primitives and higher level abstractions would be designed and shipped together. However, engineering resources are typically limited, and it often makes sense to ship one before the other, so we can provide value sooner.
This can happen in either direction:
- Lower level primitive first. Shortcuts to make common cases easy can ship at a later stage, and demos and documentation to showcase common “recipes” can be used as a stopgap meanwhile. This prioritizes use case coverage over optimal UX, but it also allows collecting more data, which can inform the design of the shortcuts implemented.
- Higher level abstraction first, as an independent, ostensibly ad hoc feature. Then later, once the lower level primitive ships, it is used to “explain” the shortcut, and make it more powerful. This prioritizes optimal UX over use case coverage: we’re not covering all use cases, but for the ones we are covering, we’re offering a frictionless user experience.
...despite the name eigensolution, it’s still all about the use cases: eigensolutions just expose links between use cases that may have been hard to detect, but seem obvious in retrospect...Requiring all use cases to precede any design work can be unnecessarily restrictive, as frequently solving a problem improves our understanding of the problem.

https://huggingface.co/microsoft/phi-2
When Phi-2 initially released, it was on the Azure AI Studio Model Catalog. It's nice to see it's now in HuggingFace as well.
https://arxiv.org/abs/2312.11514
Large language models (LLMs) are central to modern natural language processing, delivering exceptional performance in various tasks. However, their intensive computational and memory requirements present challenges, especially for devices with limited DRAM capacity. This paper tackles the challenge of efficiently running LLMs that exceed the available DRAM capacity by storing the model parameters on flash memory but bringing them on demand to DRAM. Our method involves constructing an inference cost model that harmonizes with the flash memory behavior, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks. Within this flash memory-informed framework, we introduce two principal techniques. First, "windowing'" strategically reduces data transfer by reusing previously activated neurons, and second, "row-column bundling", tailored to the sequential data access strengths of flash memory, increases the size of data chunks read from flash memory. These methods collectively enable running models up to twice the size of the available DRAM, with a 4-5x and 20-25x increase in inference speed compared to naive loading approaches in CPU and GPU, respectively. Our integration of sparsity awareness, context-adaptive loading, and a hardware-oriented design paves the way for effective inference of LLMs on devices with limited memory.
https://www.newyorker.com/tech/annals-of-technology/its-time-to-dismantle-the-technopoly
...according to [Neil Postman], we no longer live in a technocratic era. We now inhabit what he calls technopoly. In this third technological age, Postman argues, the fight between invention and traditional values has been resolved, with the former emerging as the clear winner. The result is the “submission of all forms of cultural life to the sovereignty of technique and technology.” Innovation and increased efficiency become the unchallenged mechanisms of progress, while any doubts about the imperative to accommodate the shiny and new are marginalized. “Technopoly eliminates alternatives to itself in precisely the way Aldous Huxley outlined in Brave New World,” Postman writes. “It does not make them illegal. It does not make them immoral. It does not even make them unpopular. It makes them invisible and therefore irrelevant.” Technopoly, he concludes, “is totalitarian technocracy.”
What I didn’t realize back in 2016, however, was that, although the grip of technopoly was strong, it was also soon to weaken.
A major source of this destabilization was the Trump-Clinton election cycle...Where once they had seen platforms like Facebook as useful and in some sense mandatory, they started treating them more warily.
This emerging resistance to the technopoly mind-set doesn’t fall neatly onto a spectrum with techno-optimism at one end and techno-skepticism at the other. Instead, it occupies an orthogonal dimension we might call techno-selectionism. This is a perspective that accepts the idea that innovations can significantly improve our lives but also holds that we can build new things without having to accept every popular invention as inevitable. Techno-selectionists believe that we should continue to encourage and reward people who experiment with what comes next. But they also know that some experiments end up causing more bad than good. Techno-selectionists can be enthusiastic about artificial intelligence, say, while also taking a strong stance on settings where we should block its use. They can marvel at the benefits of the social Internet without surrendering their kids’ mental lives to TikTok.
https://platform.openai.com/docs/guides/prompt-engineering
This guide shares strategies and tactics for getting better results from large language models (sometimes referred to as GPT models) like GPT-4. The methods described here can sometimes be deployed in combination for greater effect. We encourage experimentation to find the methods that work best for you.
https://www.eff.org/deeplinks/2023/12/meet-spritely-and-veilid
While there is a surge in federated social media sites, like Bluesky and Mastodon, some technologists are hoping to take things further than this model of decentralization with fully peer-to-peer applications. Two leading projects, Spritely and Veilid, hint at what this could look like.
Spritely is a framework for building distributed apps that don’t even have to know that they’re distributed. The project is spearheaded by Christine Lemmer-Webber, who was one of the co-authors of the ActivityPub spec that drives the fediverse. She is taking the lessons learned from that work, combining them with security and privacy minded object capabilities models, and mixing it all up into a model for peer to peer computation that could pave the way for a generation of new decentralized tools.
The Veilid project was released at DEFCON 31 in August and has a number of promising features that could lead to it being a fundamental tool in future decentralized systems. Described as a cross between TOR and Interplanetary File System (IPFS), Veilid is a framework and protocol that offers two complementary tools. The first is private routing, which, much like TOR, can construct an encrypted private tunnel over the public internet allowing two devices to communicate with each other without anyone else on the network knowing who is talking to whom...The second tool that Veilid offers is a Distributed Hash Table (DHT), which lets anyone look up a bit of data associated with a specific key, wherever that data lives on the network.
Public interest in decentralized tools and services is growing, as people realize that there are downsides to centralized control over the platforms that connect us all. The past year has seen interest in networks like the fediverse and Bluesky explode and there’s no reason to expect that to change. Projects like Spritely and Veilid are pushing the boundaries of how we might build apps and services in the future. The things that they are making possible may well form the foundation of social communication on the internet in the next decade, making our lives online more free, secure, and resilient.
Additional Links
https://www.theverge.com/23990974/social-media-2023-fediverse-mastodon-threads-activitypub
Good article from David Pierce. I'd add that many of these platforms (i.e. Mastodon, Lemmy, PeerTube, WordPress) have strong RSS support which offer another degree of freedom from opting out of signing up for any of the platforms but still being able to follow the people and topics you care about. Sure, the experience may not be as rich but it's yet another way for people to participate in the ecosystem.
A new kind of social internet is currently forming. Right now it might still look like “Twitter and Reddit, only different,” but that’s only the very beginning of what’s to come. Hopefully.
I’m convinced we’ll be better off with a hundred different apps for Snapchat or Instagram or X instead of just one...
It doesn’t make sense that we have a dozen usernames, a dozen profiles, a dozen sets of fans and friends. All that stuff should belong to me, and I should be able to access it and interact with it anywhere and everywhere.
Decentralizing social media can sound like a sort of kumbaya anti-capitalist manifesto: “It’s about openness and sharing, not capitalism, man!” In practice it’s the opposite: it’s a truly free market approach to social networking.
...in a fediverse-dominated world, the way to win is not to achieve excellent lock-in and network effects. The only way to win is to build the best product.
...so far we’re mostly in the “popular app, but federated” phase of this transition.
Almost everything in the fediverse is a one-to-one competitor to an existing platform...Some of these apps are very good! But nearly all of them are differentiated only in that they’re federated.
Let’s be super clear about this: the point of the fediverse is not that it’s federated...Making the “It’s federated!” argument is like making the “It’s better for privacy!” argument: it makes you feel good, and at best it’s a useful tiebreaker, but it doesn’t actually matter. All that matters is the product.
2023 was the year “fediverse” became a buzzword, 2024 will be the year it becomes an industry. (Hopefully one with a better name, but I’ll get over that.) We’ve spent too long living our lives online in someone else’s spaces. What’s next will belong to all of us. All that’s left to do is start posting.
https://mastodon.social/@jwz/111583679963120813
Just published a blog post, AI like it's 1999 or 1899, inspired by this post from jwz, among other things.

After 17 years and 761 episodes, FLOSS Weekly ended its run on the TWiT network yesterday.
Nooo! So sad to hear that FLOSS Weekly is ending, especially after learning that The Privacy, Security, and OSINT Show with Michael Bazzell ended as well.
At least there's some hope at the end of Doc's post which hints at it living on in some form.
By the way, FLOSS Weekly has not slipped below the waves. I expect it will be picked up somewhere else on the Web, and wherever you get your podcasts. (I love that expression because it means podcasting isn’t walled into some giant’s garden.) When that happens, I’ll point to it here.
In any case, it was good while it lasted. Also, there's still Reality 2.0 where the guests and topics are just as interesting and entertaining.
https://blog.mozilla.org/en/mozilla/introducing-solo-ai-website-builder/
Today we are excited to introduce a new Mozilla Innovation Project, Solo, an AI website builder for solopreneurs.
If you scour Yelp, it appears a third of businesses lack a website. However, building a website not only provides you with a presence that you own and control but it is also good for business.
Our survey data shows that the majority of solopreneurs rely upon their “tech buddy” to help build their website. As a result, the websites become stale and harder to maintain as it relies on a call to their buddy. Others without a “tech buddy” try popular website authoring tools and then abandon because it’s simply too hard to author and curate content.
Using AI to generate the content of your site and source your images, which a solopreneur can then revise into their own unique voice and style levels the playing field. Solo takes this a step further and can also scrape your existing business Yelp or other page so you have an online presence that is totally authentic to you.
...a farewell episode was released on November 20th, 2023 entitled “My Irish Exit”. It was finally officially confirmed that [The Privacy, Security, and OSINT Show with Michael Bazzell]...has reached an end.
That's unfortunate. I really enjoyed listening to this show and even had it listed in my podroll. The UNREDACTED magazine had great content as well.
https://dayoneapp.com/blog/introducing-journaling-suggestions/
See journaling recommendations inspired by your photos, locations, activities and more. Exclusively for iPhone.
I've been tinkering with Day One the past few months. When paired with their templates, this is a nice addition. Too bad it's iPhone exclusive. Hopefully it makes its way to Android at some point.
https://wildmanlife.com/aoudaghost-economic-hub-of-the-sahara/
Since 2001, the site has been on the UNESCO World Heritage Tentative List.
Today, Aoudaghost is in a state of complete abandonment. The remains of the once-thriving town are concentrated in the area most protected by the wind and sand, with several walls and fortifications yet to be fully englobed by the desert. From the adjacent cliff, the current state of Aoudaghost can be seen in its entirety, but only the mind can imagine the Aoudaghost that served as an economic and cultural hub for the Sahara
https://future.mozilla.org/blog/introducing-memorycache/
MemoryCache, a Mozilla Innovation Project, is an early exploration project that augments an on-device, personal model with local files saved from the browser to reflect a more personalized and tailored experience through the lens of privacy and agency.
Additional resources
https://future.mozilla.org/innovation-week/
Mozilla’s Innovation Week is a journey into the future of technology, where AI is not just a buzzword, but a reality we're actively shaping. Here, we're not just talking about innovation – we're living it through a series of AI-driven explorations.
With that in mind, Innovation Week is more than a showcase. It's a platform for collaboration and inspiration. It's about bringing together ideas, people, and technology to pave the way for a more open and responsible future.
https://justine.lol/oneliners/
I spent the last month working with Mozilla to launch an open source project called llamafile which is the new best way to run an LLM on your own computer. So far things have been going pretty smoothly. The project earned 5.6k stars on GitHub, 1073 upvotes on Hacker News, and received press coverage from Hackaday. Yesterday I cut a 0.3 release so let's see what it can do.
https://github.com/ml-explore/mlx-examples/tree/main/mixtral
Run the Mixtral1 8x7B mixture-of-experts (MoE) model in MLX on Apple silicon.
https://wordpress.org/state-of-the-word/
State of the Word is the annual keynote address delivered by the WordPress project’s co-founder, Matt Mullenweg, celebrating the progress of the open source project and offering a glimpse into its future.

https://www.microsoft.com/research/blog/steering-at-the-frontier-extending-the-power-of-prompting/
...steering GPT-4 with a modified version of Medprompt achieves the highest score ever achieved on the complete MMLU.
To achieve a new SoTA on MMLU, we extended Medprompt to Medprompt+ by adding a simpler prompting method and formulating a policy for deriving a final answer by integrating outputs from both the base Medprompt strategy and the simple prompts. The synthesis of a final answer is guided by a control strategy governed by GPT-4 and inferred confidences of candidate answers.
While systematic prompt engineering can yield maximal performance, we continue to explore the out-of-the-box performance of frontier models with simple prompts. It’s important to keep an eye on the native power of GPT-4 and how we can steer the model with zero- or few-shot prompting strategies.
https://github.com/microsoft/promptbase
promptbase is an evolving collection of resources, best practices, and example scripts for eliciting the best performance from foundation models like GPT-4.
https://arxiv.org/abs/2312.06550
The recent surge in open-source Large Language Models (LLMs), such as LLaMA, Falcon, and Mistral, provides diverse options for AI practitioners and researchers. However, most LLMs have only released partial artifacts, such as the final model weights or inference code, and technical reports increasingly limit their scope to high-level design choices and surface statistics. These choices hinder progress in the field by degrading transparency into the training of LLMs and forcing teams to rediscover many details in the training process. We present LLM360, an initiative to fully open-source LLMs, which advocates for all training code and data, model checkpoints, and intermediate results to be made available to the community. The goal of LLM360 is to support open and collaborative AI research by making the end-to-end LLM training process transparent and reproducible by everyone. As a first step of LLM360, we release two 7B parameter LLMs pre-trained from scratch, Amber and CrystalCoder, including their training code, data, intermediate checkpoints, and analyses (at this https URL). We are committed to continually pushing the boundaries of LLMs through this open-source effort. More large-scale and stronger models are underway and will be released in the future.
Additional Resources
https://www.microsoft.com/research/blog/phi-2-the-surprising-power-of-small-language-models/
We are now releasing Phi-2, a 2.7 billion-parameter language model that demonstrates outstanding reasoning and language understanding capabilities, showcasing state-of-the-art performance among base language models with less than 13 billion parameters. On complex benchmarks Phi-2 matches or outperforms models up to 25x larger, thanks to new innovations in model scaling and training data curation.
https://www.answer.ai/posts/2023-12-12-launch.html
Jeremy Howard (founding CEO, previously co-founder of Kaggle and fast.ai) and Eric Ries (founding director, previously creator of Lean Startup and the Long-Term Stock Exchange) today launched Answer.AI, a new kind of AI R&D lab which creates practical end-user products based on foundational research breakthroughs. The creation of Answer.AI is supported by an investment of USD10m from Decibel VC. Answer.AI will be a fully-remote team of deep-tech generalists—the world’s very best, regardless of where they live, what school they went to, or any other meaningless surface feature.
https://stability.ai/news/stablelm-zephyr-3b-stability-llm
Stable LM Zephyr 3B is a 3 billion parameter Large Language Model (LLM), 60% smaller than 7B models, allowing accurate, and responsive output on a variety of devices without requiring high-end hardware.
Despite delays, the plan to connect Tumblr’s blogging site to the wider world of decentralized social media, also known as the “fediverse,” is still on, it seems.
...Mullenweg explained that despite the re-org, which will see many Tumblr employees move to other projects at the end of the year, Automattic did switch someone over to Tumblr to work on the fediverse integration, which will continue in the new year.
“I remain a huge believer in open standards and user freedom, though I don’t claim to have the truth on which particular standard is better or best, to serve our customers we will support everything we can in good faith to give users more freedom, choice, and avoid lock-in,” [Matt Mullenweg] also said in his AMA.
Mullunweg also noted that a larger effort to migrate Tumblr’s half a billion blogs to WordPress on the backend is something he’s also contemplating in the new year.
https://saprmarks.github.io/geometry-of-truth/dataexplorer/
This page contains interactive charts for exploring how large language models represent truth. It accompanies the paper The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets by Samuel Marks and Max Tegmark.
To produce these visualizations, we first extract LLaMA-13B representations of factual statements. These representations live in a 5120-dimensional space, far too high-dimensional for us to picture, so we use PCA to select the two directions of greatest variation for the data. This allows us to produce 2-dimensional pictures of 5120-dimensional data. See this footnote for more details.1
https://docs.google.com/presentation/d/156WpBF_rGvf4Ecg19oM1fyR51g4FAmHV3Zs0WLukrLQ/edit?usp=sharing
Key themes in the 2023 Report include:
- GPT-4 is the master of all it surveys (for now), beating every other LLM on both classic benchmarks and exams designed to evaluate humans, validating the power of proprietary architectures and reinforcement learning from human feedback.
- Efforts are growing to try to clone or surpass proprietary performance, through smaller models, better datasets, and longer context. These could gain new urgency, amid concerns that human-generated data may only be able to sustain AI scaling trends for a few more years.
- LLMs and diffusion models continue to drive real-world breakthroughs, especially in the life sciences, with meaningful steps forward in both molecular biology and drug discovery.
- Compute is the new oil, with NVIDIA printing record earnings and startups wielding their GPUs as a competitive edge. As the US tightens its restrictions on trade restrictions on China and mobilizes its allies in the chip wars, NVIDIA, Intel, and AMD have started to sell export-control proof chips at scale.
- GenAI saves the VC world, as amid a slump in tech valuations, AI startups focused on generative AI applications (including video, text, and coding), raised over $18 billion from VC and corporate investors.
- The safety debate has exploded into the mainstream, prompting action from governments and regulators around the world. However, this flurry of activity conceals profound divisions within the AI community and a lack of concrete progress towards global governance, as governments around the world pursue conflicting approaches.
- Challenges mount in evaluating state of the art models, as standard LLMs often struggle with robustness. Considering the stakes, as “vibes-based” approach isn’t good enough.
Additional resources
https://github.com/vitoplantamura/OnnxStream/
Generally major machine learning frameworks and libraries are focused on minimizing inference latency and/or maximizing throughput, all of which at the cost of RAM usage. So I decided to write a super small and hackable inference library specifically focused on minimizing memory consumption: OnnxStream.
OnnxStream is based on the idea of decoupling the inference engine from the component responsible of providing the model weights, which is a class derived from WeightsProvider. A WeightsProvider specialization can implement any type of loading, caching and prefetching of the model parameters. For example a custom WeightsProvider can decide to download its data from an HTTP server directly, without loading or writing anything to disk (hence the word "Stream" in "OnnxStream"). Three default WeightsProviders are available: DiskNoCache, DiskPrefetch and Ram.
OnnxStream can consume even 55x less memory than OnnxRuntime with only a 50% to 200% increase in latency (on CPU, with a good SSD, with reference to the SD 1.5's UNET - see the Performance section below).
https://www.cs.princeton.edu/~arvindn/talks/evaluating_llms_minefield/
...many things can go wrong when we are trying to evaluate LLMs’ performance on a certain task or behavior in a certain scenario.
It has big implications for reproducibility: both for research on LLMs and research that uses LLMs to answer a question in social science or any other field.
https://benchmark.vectorview.ai/vectordbs.html
Picking a vector database can be hard. Scalability, latency, costs, and even compliance hinge on this choice. For those navigating this terrain, I've embarked on a journey to sieve through the noise and compare the leading vector databases of 2023. I’ve included the following vector databases in the comparision: Pinecone, Weviate, Milvus, Qdrant, Chroma, Elasticsearch and PGvector. The data behind the comparision comes from ANN Benchmarks, the docs and internal benchmarks of each vector database and from digging in open source github repos.
Teach LLMs to manage their own memory for unbounded context!
Large language models (LLMs) have revolutionized AI, but are constrained by limited context windows, hindering their utility in tasks like extended conversations and document analysis. To enable using context beyond limited context windows, we propose virtual context management, a technique drawing inspiration from hierarchical memory systems in traditional operating systems that provide the appearance of large memory resources through data movement between fast and slow memory. Using this technique, we introduce MemGPT (Memory-GPT), a system that intelligently manages different memory tiers in order to effectively provide extended context within the LLM's limited context window, and utilizes interrupts to manage control flow between itself and the user. We evaluate our OS-inspired design in two domains where the limited context windows of modern LLMs severely handicaps their performance: document analysis, where MemGPT is able to analyze large documents that far exceed the underlying LLM's context window, and multi-session chat, where MemGPT can create conversational agents that remember, reflect, and evolve dynamically through long-term interactions with their users. We release MemGPT code and data for our experiments at https://memgpt.ai.
In MemGPT, a fixed-context LLM processor is augmented with a tiered memory system and a set of functions that allow it to manage its own memory. Main context is the (fixed-length) LLM input. MemGPT parses the LLM text ouputs at each processing cycle, and either yields control or executes a function call, which can be used to move data between main and external context. When the LLM generates a function call, it can request immediate return of execution to chain together functions. In the case of a yield, the LLM will not be run again until the next external event trigger (e.g. a user message or scheduled interrupt).
https://www.databricks.com/blog/LLM-auto-eval-best-practices-RAG
This blog represents the first in a series of investigations we’re running at Databricks to provide learnings on LLM evaluation.
Recently, the LLM community has been exploring the use of “LLMs as a judge” for automated evaluation with many using powerful LLMs such as GPT-4 to do the evaluation for their LLM outputs.
Using the Few Shots prompt with GPT-4 didn’t make an obvious difference in the consistency of results.
Including few examples for GPT-3.5-turbo-16k significantly improves the consistency of the scores, and makes the result usable.
...evaluation results can’t be transferred between use cases and we need to build use-case-specific benchmarks in order to properly evaluate how good a model can meet customer needs.
LLM-as-a-judge is one promising tool in the suite of evaluation techniques necessary to measure the efficacy of LLM-based applications.
https://arxiv.org/abs/2309.16671
Contrastive Language-Image Pre-training (CLIP) is an approach that has advanced research and applications in computer vision, fueling modern recognition systems and generative models. We believe that the main ingredient to the success of CLIP is its data and not the model architecture or pre-training objective. However, CLIP only provides very limited information about its data and how it has been collected, leading to works that aim to reproduce CLIP's data by filtering with its model parameters. In this work, we intend to reveal CLIP's data curation approach and in our pursuit of making it open to the community introduce Metadata-Curated Language-Image Pre-training (MetaCLIP). MetaCLIP takes a raw data pool and metadata (derived from CLIP's concepts) and yields a balanced subset over the metadata distribution. Our experimental study rigorously isolates the model and training settings, concentrating solely on data. MetaCLIP applied to CommonCrawl with 400M image-text data pairs outperforms CLIP's data on multiple standard benchmarks. In zero-shot ImageNet classification, MetaCLIP achieves 70.8% accuracy, surpassing CLIP's 68.3% on ViT-B models. Scaling to 1B data, while maintaining the same training budget, attains 72.4%. Our observations hold across various model sizes, exemplified by ViT-H achieving 80.5%, without any bells-and-whistles. Curation code and training data distribution on metadata is made available at this https URL.
Repository
https://arxiv.org/abs/2310.10634
Language agents show potential in being capable of utilizing natural language for varied and intricate tasks in diverse environments, particularly when built upon large language models (LLMs). Current language agent frameworks aim to facilitate the construction of proof-of-concept language agents while neglecting the non-expert user access to agents and paying little attention to application-level designs. We present OpenAgents, an open platform for using and hosting language agents in the wild of everyday life. OpenAgents includes three agents: (1) Data Agent for data analysis with Python/SQL and data tools; (2) Plugins Agent with 200+ daily API tools; (3) Web Agent for autonomous web browsing. OpenAgents enables general users to interact with agent functionalities through a web user interface optimized for swift responses and common failures while offering developers and researchers a seamless deployment experience on local setups, providing a foundation for crafting innovative language agents and facilitating real-world evaluations. We elucidate the challenges and opportunities, aspiring to set a foundation for future research and development of real-world language agents.
https://crfm.stanford.edu/fmti/
A comprehensive assessment of the transparency of foundation model developers
Context. Foundation models like GPT-4 and Llama 2 are used by millions of people. While the societal impact of these models is rising, transparency is on the decline. If this trend continues, foundation models could become just as opaque as social media platforms and other previous technologies, replicating their failure modes.
Design. We introduce the Foundation Model Transparency Index to assess the transparency of foundation model developers. We design the Index around 100 transparency indicators, which codify transparency for foundation models, the resources required to build them, and their use in the AI supply chain.
Execution. For the 2023 Index, we score 10 leading developers against our 100 indicators. This provides a snapshot of transparency across the AI ecosystem. All developers have significant room for improvement that we will aim to track in the future versions of the Index.
https://www.latent.space/p/oct-2023
Mistral 7B, released at the tail end of Sept 2023, is both Apache 2.0 and smaller but better than Llama 2, and is now rumored to be raising $400m at $2.5b valuation from a16z.
https://mistral.ai/news/mixtral-of-experts/
Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.
Mixtral has the following capabilities.
- It gracefully handles a context of 32k tokens.
- It handles English, French, Italian, German and Spanish.
- It shows strong performance in code generation.
- It can be finetuned into an instruction-following model that achieves a score of 8.3 on MT-Bench.
Mixtral is a sparse mixture-of-experts network. It is a decoder-only model where the feedforward block picks from a set of 8 distinct groups of parameters. At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.
This technique increases the number of parameters of a model while controlling cost and latency, as the model only uses a fraction of the total set of parameters per token. Concretely, Mixtral has 46.7B total parameters but only uses 12.9B parameters per token. It, therefore, processes input and generates output at the same speed and for the same cost as a 12.9B model.
https://kottke.org/23/11/the-future-of-rss-is-textcasting-1
Here’s the philosophy:
- The goal is interop between social media apps and the features writers need.
- What we’re doing: Moving documents between networked apps. We need a set of common features in order for it to work.
- The features are motivated by the needs of writers. Not by programmers or social media company execs.
It’s a proposal to build, using technologies we already have and understand very well, a very simple social media protocol that is completely agnostic about what editor you use to write your posts and what viewer you choose to read it. Writer/authors would have more control over styling, links, media enclosures, etc., and readers would have more control over how and where they consume it. It’s decentralized social media, but without the need to peer through ActivityPub or anybody else’s API and squeeze our toothpaste through its tubes.
Additional resources
https://blakewatson.com/journal/omg-lol-an-oasis-on-the-internet/
The main thing you are getting with omg.lol is one or more subdomains, which are referred to as addresses.
- Email forwarding: You get an email address, you@omg.lol, which you can forward to any email address.
- Web Page: This is your link-in-bio one-pager to do whatever you want with. By default this is where your main address (eg, you.omg.lol) points. It’s the flagship feature of omg.lol. It comes with a markdown editor that has some fancy features baked into it. You get a selection of built-in themes but you also have the freedom to go wild with your own CSS.
- DNS: You have the ability to use your omg.lol subdomain however you wish by way of a friendly DNS panel.
- Now Page: This is a type of page you can use to let people know what’s going on in your life. It’s broader than a social media post but more immediately relevant than an about page. It comes with the same fancy markdown editor and you can optionally appear in omg.lol’s Now Garden.
- Statuslog: This is a place to post statuses. It’s really just a fun, silly alternative to other social media platforms but without follows and likes and such. These can cross-post to Mastodon if you want.
- Weblog: A full-fledge blogging platform. I’m not aware of all its features but it’s pretty powerful. It comes with fancy markdown support and has all the bloggy things you need like tags and RSS. A good example of a very custom blog on omg.lol is Apple Annie’s Weblog. But it’s worth noting you use it right out of the box without design customization if you want.
- Pastebin: It’s just a pastebin for storing text snippets. Super simple and friendly like all of the omg.lol services.
- Pics: It’s an image hosting service labeled as being “super-beta” as of the time of this writing. But it does what it says on the tin. You can host images there and they also show up on the some.pics image feed.
- PURLs: Persistent uniform resource locators. This is a URL redirection service. You get you.omg.lol/whatever and you.url.lol/whatever. You can use these the way you would use similar services and they come with a basic hit counter and way to preview the URL before following it.
- Switchboard: This is a powerful routing system that lets you point the variants of your address wherever you want, be it a destination on the omg.lol platform or an external website. Most omg.lol services have their own domain so you end up with a variety of options. Just as an example, you get a tilde address (ie, omg.lol/~you). Mine points to my tilde.club webpage.
- Keys: A place to store public keys—SSH, PGP, etc.
- Proofs: A service for verifying ownership or control of a particular web property at a particular moment in time. For example, here is proof that I controlled blakewatson.com as of December 10, 2023.
- API access: Most, if not all, omg.lol services have an API you can use to interact with them. Total nerd freedom. 🤯
https://thoughtcatalog.com/ryan-holiday/2017/01/to-everyone-who-asks-for-just-a-little-of-your-time/
Makers...need to have large blocks of uninterrupted, unscheduled time to do what they do. To create and think.
I keep a maker’s schedule because I believe that anything else is anathema to deep work or creativity.
Seneca writes that if all the geniuses in history were to get together, none would be able explain our baffling relationship with time. He says,
No person would give up even an inch of their estate, and the slightest dispute with a neighbor can mean hell to pay; yet we easily let others encroach on our lives—worse, we often pave the way for those who will take it over. No person hands out their money to passers-by, but to how many do each of us hand out our lives! We’re tight-fisted with property and money, yet think too little of wasting time, the one thing about which we should all be the toughest misers.
Time? Time is our most irreplaceable asset—we cannot buy more of it. We cannot get a second of it back. We can only hope to waste as little as possible. Yet somehow we treat it as most renewable of all resources.
https://staysaasy.com/management/2023/12/07/accelerating-product-velocity.html
Remove Dependencies
Create a culture that favors begging forgiveness (and reversing decisions quickly) rather than asking permission. Invest in infrastructure such as progressive / cancellable rollouts. Use asynchronous written docs to get people aligned (“comment in this doc by Friday if you disagree with the plan”) rather than meetings (“we’ll get approval at the next weekly review meeting”).
Demand Clear Narratives
Unclear thinking is a reliable cause of slowness, and gets revealed under a microscope.
Bonus points for documenting plans in writing. One of the largest advantages of a strong writing culture is that it forces much clearer narratives than meetings, powerpoint, or five Slack threads spread over 8 business days.
Get Your Deployment and Incident Metrics In Shape
No matter what your job function is, part of your role is ensuring that your engineering team has enough time to get their vital metrics in order. Especially if you’re a product leader, it’s essential that you resist the temptation to push relentlessly for more features and give your engineering counterparts the room to get fit.
Find Trusted Engineering Guides
...it’s especially important to build a strong relationship with all of your engineering partners, and especially these trusted guides.
https://github.com/microsoft/satclip
SatCLIP trains location and image encoders via contrastive learning, by matching images to their corresponding locations. This is analogous to the CLIP approach, which matches images to their corresponding text. Through this process, the location encoder learns characteristics of a location, as represented by satellite imagery. For more details, check out our paper.
DOS_deck is built upon the foundation of JS-DOS, which, in turn, relies on DOSBox. Together, they breathe new life into MS-DOS games by bringing them to your browser. However, there's a twist. Games from that era were designed for keyboard and mouse input, without established standards for interaction or control patterns. Here at DOS_deck, a tremendous effort was put into creating a seamless experience, enabling you to effortlessly navigate and play these games, ideally with the comfort of a controller in hand.
Aggregated list of App Defaults blog posts inspired by Hemispheric Views 097 - Duel of the Defaults!
https://daverupert.com/rss-club/
RSS Club is a collection of blogs (personal and otherwise) committed to providing RSS-only content. It’s like a newsletter delivered to your feed reader in order to celebrate the medium of RSS and breakaway from social media.
https://www.anthropic.com/index/claude-2-1-prompting
- Claude 2.1 recalls information very well across its 200,000 token context window
- However, the model can be reluctant to answer questions based on an individual sentence in a document, especially if that sentence has been injected or is out of place
- A minor prompting edit removes this reluctance and results in excellent performance on these tasks
What can users do if Claude is reluctant to respond to a long context retrieval question? We’ve found that a minor prompt update produces very different outcomes in cases where Claude is capable of giving an answer, but is hesitant to do so. When running the same evaluation internally, adding just one sentence to the prompt resulted in near complete fidelity throughout Claude 2.1’s 200K context window
We achieved significantly better results on the same evaluation by adding the sentence “Here is the most relevant sentence in the context:” to the start of Claude’s response. This was enough to raise Claude 2.1’s score from 27% to 98% on the original evaluation.
https://chrismcleod.dev/blog/blogging-is-where-its-at-again/
the blog is the “natural form” of posting on the web: a site of your own, that you control[1] and set your own rules on content and discussion; where you can post whatever you like without worrying about “The Algorithm”
For better or for worse, social media opened up the web to a lot more people for a number of reasons...But deep down I feel having your own site is better. For the web, and for you: the writer and the reader.
...stumbling into such a trove of active blogs has enthused me about blogging as a medium again. It’s sparked a thought that through a combination of increased blogging activity, declining platforms, and increasing adoption of open standards to glue everything together, that maybe — just maybe — we can swing the web back towards the blog again.
Agree with many of the points. Also, TIL you could subscribe to OPML feeds.
https://blog.google/technology/ai/google-gemini-ai/
Gemini is the result of large-scale collaborative efforts by teams across Google, including our colleagues at Google Research. It was built from the ground up to be multimodal, which means it can generalize and seamlessly understand, operate across and combine different types of information including text, code, audio, image and video.
Gemini is also our most flexible model yet — able to efficiently run on everything from data centers to mobile devices. Its state-of-the-art capabilities will significantly enhance the way developers and enterprise customers build and scale with AI.
We’ve optimized Gemini 1.0, our first version, for three different sizes:
- Gemini Ultra — our largest and most capable model for highly complex tasks.
- Gemini Pro — our best model for scaling across a wide range of tasks.
- Gemini Nano — our most efficient model for on-device tasks.
We designed Gemini to be natively multimodal, pre-trained from the start on different modalities. Then we fine-tuned it with additional multimodal data to further refine its effectiveness. This helps Gemini seamlessly understand and reason about all kinds of inputs from the ground up, far better than existing multimodal models — and its capabilities are state of the art in nearly every domain.
Our first version of Gemini can understand, explain and generate high-quality code in the world’s most popular programming languages, like Python, Java, C++, and Go.
On TPUs, Gemini runs significantly faster than earlier, smaller and less-capable models.
Starting today, Bard will use a fine-tuned version of Gemini Pro for more advanced reasoning, planning, understanding and more.
We’re also bringing Gemini to Pixel. Pixel 8 Pro is the first smartphone engineered to run Gemini Nano, which is powering new features like Summarize in the Recorder app and rolling out in Smart Reply in Gboard, starting with WhatsApp — with more messaging apps coming next year.
Starting on December 13, developers and enterprise customers can access Gemini Pro via the Gemini API in Google AI Studio or Google Cloud Vertex AI.
https://hacks.mozilla.org/2023/11/introducing-llamafile/
Today we’re announcing the first release of llamafile and inviting the open source community to participate in this new project.
llamafile lets you turn large language model (LLM) weights into executables.
We achieved all this by combining two projects that we love: llama.cpp (a leading open source LLM chatbot framework) with Cosmopolitan Libc (an open source project that enables C programs to be compiled and run on a large number of platforms and architectures). It also required solving several interesting and juicy problems along the way, such as adding GPU and dlopen() support to Cosmopolitan;
https://framablog.org/2023/11/28/peertube-v6-is-out-and-powered-by-your-ideas/
The sixth major version is being released today and we are very proud !
Protect your videos with passwords !
Video storyboard : preview what’s coming !
Upload a new version of your video !
Get chapters in your videos !
Stress tests, performance and config recommandations
…and there’s always more !
https://blog.jim-nielsen.com/2023/how-i-take-and-publish-notes/
99% of the time, this is how my note-taking process goes:
- I’m catching up on my RSS feed (on my phone in the Reeder app)
- I read something that strikes me as interesting, novel, or insightful.
- I copy/paste it as an blockquote into a new, plain-text note in iA writer.
- I copy/paste the link of the article into iA writer.
- I finish reading the article and copy/paste anything else in the article that strikes me.
- I add my own comments in the note as they pop into my head.
- I move on to the next article in my RSS feed.
- Repeat.
Kind of meta but somewhat similar process for me. To publish the different content found on my response feed, I:
- Go through articles on my RSS feed (NewsBlur on both desktop and mobile).
- Copy URL and block quotes from article and paste them somewhere. When I have time like now, I create a post like this one, usually in VS Code. If I don't have time though, I've been experimenting with using a messaging app like Element and E-mail as a read-it-later service. At minimum, I create a message with the link and send it to myself for later review. Later on when I have time, I create the post with additional comments and content from the article.
- (Optional) Add some of my own comments.
- Publish the notes.
- Repeat.
https://www.schneier.com/blog/archives/2023/12/ai-and-mass-spying.html
Surveillance facilitates social control, and spying will only make this worse. Governments around the world already use mass surveillance; they will engage in mass spying as well.
Mass surveillance ushered in the era of personalized advertisements; mass spying will supercharge that industry...The tech monopolies that are currently keeping us all under constant surveillance won’t be able to resist collecting and using all of that data.
We could limit this capability. We could prohibit mass spying. We could pass strong data-privacy rules. But we haven’t done anything to limit mass surveillance. Why would spying be any different?
AI Alliance Launches as an International Community of Leading Technology Developers, Researchers, and Adopters Collaborating Together to Advance Open, Safe, Responsible AI

YOU NEED FEEDS.
A web feed is a special listing of the latest content from your favourite site. News, music, video and more - whatever is new, web feeds will show you. What's more, you can combine your favourite feeds using a feed reader application - and suddenly the whole web comes to you.
You don't have to do the work of staying on top any more. You can now visit a single site, or use a single app, and see everything that's new and interesting. You choose the content. You're in control.
https://ma.tt/2023/10/texts-joins-automattic/
Using an all-in-one messaging app is a real game-changer for productivity and keeping up with things.
This is obviously a tricky area to navigate, as in the past the networks have blocked third-party clients, but I think with the current anti-trust and regulatory environments this is actually something the big networks will appreciate: it maintains the same security as their clients, opens them up in a way consumers will love and is very user-centric, and because we’re committed to supporting all their features it can actually increase engagement and usage of their platforms.
I can relate to the feeling of wanting to have one inbox expressed in the video. Coincidentally, I've been playing with Delta Chat and by building on top of e-mail, some of the issues with the siloed platforms are alleviated. Also, e-mail isn't dead and despite some of its shortcomings, it's still broadly used to sign up and sign into platforms.
https://www.theverge.com/2023/10/24/23928685/automattic-texts-acquisition-universal-messaging
I'm really liking the recent acquisitions from Automattic. I'm just starting to use Day One and really enjoy it. Pocket Casts is a fantastic podcast app, though I prefer to use AntennaPod. WordPress is also starting to make it easy to plug into the Fediverse using your blog. I'm excited for Texts and what that might offer in the current siloed messaging landscape.
Automattic, the company that runs WordPress.com, Tumblr, Pocket Casts, and a number of other popular web properties, just made a different kind of acquisition: it’s buying Texts, a universal messaging app, for $50 million.
Texts is an app for all your messaging apps. You can use it to log in to WhatsApp, Instagram, LinkedIn, Signal, iMessage, and more and see and respond to all your messages in one place.
...Mullenweg says he’s bullish on solutions like Matrix, which offers a decentralized and open-source messaging network, and other up-and-coming standards for messaging. He’s already thinking about how Texts might gently nudge people toward more open protocols over time.
Mullenweg and Automattic see a big future for messaging, as more online interaction shifts away from public-first social networks and toward things like group chats. Hardly anyone has figured out how to build a meaningful and sustainable business from chat, but Mullenweg thinks it’s possible. And he thinks it starts with making your messaging a little less messy.
The platform era is ending. Rather than build new Twitters and Facebooks, we can create a stuff-posting system that works better for everybody.
In a POSSE world, everybody owns a domain name, and everybody has a blog. (I’m defining “blog” pretty loosely here — just as a place on the internet where you post your stuff and others consume it.)
But there are some big challenges to the idea...The most immediate question...is simply how to build a POSSE system that works. POSSE’s problems start at the very beginning: it requires owning your own website, which means buying a domain and worrying about DNS records and figuring out web hosts, and by now, you’ve already lost the vast majority of people who would rather just type a username and password into some free Meta platform...Even those willing and able to do the technical work can struggle to make POSSE work.
When I ask Doctorow why he believed in POSSE, he describes the tension every poster feels on the modern internet. “I wanted to find a way to stand up a new platform in this moment,” he says, “where, with few exceptions, everyone gets their news and does their reading through the silos that then hold you to ransom. And I wanted to use those silos to bring in readers and to attract and engage with an audience, but I didn’t want to become beholden to them.” The best of both worlds is currently a lot of work. But the poster’s paradise might not be so far away.
https://udlbook.github.io/udlbook/
The title of this book is “Understanding Deep Learning” to distinguish it from volumes that cover coding and other practical aspects. This text is primarily about the ideas that underlie deep learning. The first part of the book introduces deep learning models and discusses how to train them, measure their performance, and improve this performance. The next part considers architectures that are specialized to images, text, and graph data. These chapters require only introductory linear algebra, calculus, and probability and should be accessible to any second-year undergraduate in a quantitative discipline. Subsequent parts of the book tackle generative models and reinforcement learning. These chapters require more knowledge of probability and calculus and target more advanced students.
https://arxiv.org/abs/2309.17421
Large multimodal models (LMMs) extend large language models (LLMs) with multi-sensory skills, such as visual understanding, to achieve stronger generic intelligence. In this paper, we analyze the latest model, GPT-4V(ision), to deepen the understanding of LMMs. The analysis focuses on the intriguing tasks that GPT-4V can perform, containing test samples to probe the quality and genericity of GPT-4V's capabilities, its supported inputs and working modes, and the effective ways to prompt the model. In our approach to exploring GPT-4V, we curate and organize a collection of carefully designed qualitative samples spanning a variety of domains and tasks. Observations from these samples demonstrate that GPT-4V's unprecedented ability in processing arbitrarily interleaved multimodal inputs and the genericity of its capabilities together make GPT-4V a powerful multimodal generalist system. Furthermore, GPT-4V's unique capability of understanding visual markers drawn on input images can give rise to new human-computer interaction methods such as visual referring prompting. We conclude the report with in-depth discussions on the emerging application scenarios and the future research directions for GPT-4V-based systems. We hope that this preliminary exploration will inspire future research on the next-generation multimodal task formulation, new ways to exploit and enhance LMMs to solve real-world problems, and gaining better understanding of multimodal foundation models. Finally, we acknowledge that the model under our study is solely the product of OpenAI's innovative work, and they should be fully credited for its development. Please see the GPT-4V contributions paper for the authorship and credit attribution: this https URL
https://arxiv.org/abs/2309.11495
Generation of plausible yet incorrect factual information, termed hallucination, is an unsolved issue in large language models. We study the ability of language models to deliberate on the responses they give in order to correct their mistakes. We develop the Chain-of-Verification (COVE) method whereby the model first (i) drafts an initial response; then (ii) plans verification questions to fact-check its draft; (iii) answers those questions independently so the answers are not biased by other responses; and (iv) generates its final verified response. In experiments, we show COVE decreases hallucinations across a variety of tasks, from list-based questions from Wikidata, closed book MultiSpanQA and longform text generation.
https://wordpress.com/blog/2023/10/11/activitypub/
Exciting times are here for all WordPress.com users! The revolutionary ActivityPub feature is now available across all WordPress.com plans, unlocking a world of engagement and interaction for your blog. Your blogs can now be part of the rapidly expanding fediverse, which enables you to connect with a broader audience and attract more followers.
I can't believe I missed these news but so exciting!
https://huyenchip.com/2023/10/10/multimodal.html
This post covers multimodal systems in general, including LMMs. It consists of 3 parts.
Part 1 covers the context for multimodality, including why multimodal, different data modalities, and types of multimodal tasks.
Part 2 discusses the fundamentals of a multimodal system, using the examples of CLIP, which lays the foundation for many future multimodal systems, and Flamingo, whose impressive performance gave rise to LMMs.
Part 3 discusses some active research areas for LMMs, including generating multimodal outputs and adapters for more efficient multimodal training, covering newer multimodal systems such as BLIP-2, LLaVA, LLaMA-Adapter V2, LAVIN, etc.
https://github.com/huggingface/text-embeddings-inference
A blazing fast inference solution for text embeddings models.
Radiooooo is a project born in 2013, dreamt up by a little family of friends, both djs and music lovers, who decided to share their record collections and the fruit of many years of research, for all to enjoy.
« Sharing and discovering » , « curiosity and pleasure » these are the foundations of this musical time machine.
Radiooooo is a collaborative website, whose goal is to open each and everyone’s horizons through culture and beauty.
https://www.beren.io/2023-04-11-Scaffolded-LLMs-natural-language-computers/
https://queue.acm.org/detail.cfm?id=3623391
The team at NVIDIA brings confidentiality and integrity to user code and data for accelerated computing.

Mistral-7B-v0.1 is a small, yet powerful model adaptable to many use-cases. Mistral 7B is better than Llama 2 13B on all benchmarks, has natural coding abilities, and 8k sequence length. It’s released under Apache 2.0 licence. We made it easy to deploy on any cloud, and of course on your gaming GPU.
https://about.fb.com/news/2023/09/introducing-ai-powered-assistants-characters-and-creative-tools/
- We’re starting to roll out AI stickers across our apps, and soon you’ll be able to edit your images or even co-create them with friends on Instagram using our new AI editing tools, restyle and backdrop.
- We’re introducing Meta AI in beta, an advanced conversational assistant that’s available on WhatsApp, Messenger, and Instagram, and is coming to Ray-Ban Meta smart glasses and Quest 3. Meta AI can give you real-time information and generate photorealistic images from your text prompts in seconds to share with friends. (Available in the US only)
- We’re also launching 28 more AIs in beta, with unique interests and personalities. Some are played by cultural icons and influencers, including Snoop Dogg, Tom Brady, Kendall Jenner, and Naomi Osaka.
- Over time, we’re making AIs for businesses and creators available, and releasing our AI studio for people and developers to build their own AIs.
- These new AI experiences also come with a new set of challenges for our industry. We’re rolling out our new AIs slowly and have built in safeguards.
https://www.raspberrypi.com/products/raspberry-pi-5/
The everything computer. Optimised.
With 2–3× the speed of the previous generation, and featuring silicon designed in‑house for the best possible performance, we’ve redefined the Raspberry Pi experience.
Coming October 2023
https://shop.boox.com/products/palma
I really like my Boox e-reader but having a more pocketable device would be amazing. It's unforunate you can't also use it for handwritten notes but at this size it makes sense.


https://blog.research.google/2023/09/distilling-step-by-step-outperforming.html
In “Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes”, presented at ACL2023, we set out to tackle this trade-off between model size and training data collection cost. We introduce distilling step-by-step, a new simple mechanism that allows us to train smaller task-specific models with much less training data than required by standard fine-tuning or distillation approaches that outperform few-shot prompted LLMs’ performance. We demonstrate that the distilling step-by-step mechanism enables a 770M parameter T5 model to outperform the few-shot prompted 540B PaLM model using only 80% of examples in a benchmark dataset, which demonstrates a more than 700x model size reduction with much less training data required by standard approaches.
https://www.bbc.com/future/article/20230912-how-i-hacked-my-brain
There is growing evidence that simple, everyday changes to our lives can alter our brains and change how they work. Melissa Hogenboom put herself into a scanner to find out.
I was surprised that something as simple as mindfulness can play such a crucial role in keeping our minds healthy. Research has shown that mindfulness is a simple but powerful way to enhance several cognitive functions. It can improve attention, relieve pain and reduce stress. Research has found that after only a few months of mindfulness training, certain depression and anxiety symptoms can ease – though as with any complex mental health problem, this may of course vary depending on individual circumstances.
http://josephthacker.com/ai/2023/09/18/vim-llm-hacks.html
... I learned that you could be inside vim, but manipulate the entire file as if you were piping the contents of the file into a command. The output of the command does in-line replacement of the entire file with those changes. That sounds confusing, but it just means you can be inside a vim file and do :%!grep test and it’ll remove all lines that don’t contain test, for example.
This post is a simple showcase of taking that concept, but throwing an llm into the mix to add more dynamic functionality.
https://www.youtube.com/watch?v=bskEGP0r3hE
The future is AVX10, so says Intel. Recently a document was released showcasing a post-AVX512 world, and to explain why this matters, I've again invited the Chips And Cheese crew onto the channel. Chester and George answer my questions on AVX10 and why it matters! Visit http://www.chipsandcheese.com to learn more!

https://www.nps.gov/katm/learn/fat-bear-week.htm
Fat Bear Week - an annual celebration of success. All bears are winners but only one true champion will emerge. Held over the course of seven days and concluding on the Fat Bear Tuesday, people chose which bear to crown in this tournament style bracket where bears are pitted against each other for your vote.
https://openai.com/blog/chatgpt-can-now-see-hear-and-speak
We are beginning to roll out new voice and image capabilities in ChatGPT. They offer a new, more intuitive type of interface by allowing you to have a voice conversation or show ChatGPT what you’re talking about.
https://www.aboutamazon.com/news/company-news/amazon-aws-anthropic-ai
Anthropic selects AWS as its primary cloud provider and will train and deploy its future foundation models on AWS Trainium and Inferentia chips, taking advantage of AWS’s high-performance, low-cost machine learning accelerators.
Happy 20th anniversary! Also, thanks for the generous linking. Lots of new folks to read and subscribe to.
DALL·E 3 understands significantly more nuance and detail than our previous systems, allowing you to easily translate your ideas into exceptionally accurate images.
https://matrix.org/blog/2023/09/matrix-2-0/
TL;DR: If you want to play with a shiny new Matrix 2.0 client, head over to Element X.
Sponsored post, but it's still a good list with guidance and suggestions for common questions.
https://huggingface.co/blog/optimize-llm
In this blog post, we will go over the most effective techniques at the time of writing this blog post to tackle these challenges for efficient LLM deployment:
- Lower Precision: Research has shown that operating at reduced numerical precision, namely 8-bit and 4-bit, can achieve computational advantages without a considerable decline in model performance.
2. Flash Attention: Flash Attention is a variation of the attention algorithm that not only provides a more memory-efficient approach but also realizes increased efficiency due to optimized GPU memory utilization.
3. Architectural Innovations: Considering that LLMs are always deployed in the same way during inference, namely autoregressive text generation with a long input context, specialized model architectures have been proposed that allow for more efficient inference. The most important advancement in model architectures hereby are Alibi, Rotary embeddings, Multi-Query Attention (MQA) and Grouped-Query-Attention (GQA).
https://blog.minch.co/2022/11/15/software-squared.html
A new generation of AIs that become increasingly general by producing their own training data
We are currently at the cusp of transitioning from “learning from data” to “learning what data to learn from” as the central focus of AI research.
If deep learning can be described as “Software 2.0”—software that programs itself based on example inputs/output pairs, then this promising, data-centric paradigm, in which software effectively improves itself by searching for its own training data, can be described as a kind of “Software²”. This paradigm inherits the benefits of Software 2.0 while improving on its core, data-bound weaknesses: While deep learning (Software 2.0) requires the programmer to manually provide training data for each new task, Software² recasts data as software that models or searches the world to produce its own, potentially unlimited, training tasks and data.
https://github.com/OpenRobotLab/PointLLM
We introduce PointLLM, a multi-modal large language model capable of understanding colored point clouds of objects. It perceives object types, geometric structures, and appearance without concerns for ambiguous depth, occlusion, or viewpoint dependency. We collect a novel dataset comprising 660K simple and 70K complex point-text instruction pairs to enable a two-stage training strategy. To rigorously evaluate our model's perceptual abilities and its generalization capabilities, we establish two benchmarks: Generative 3D Object Classification and 3D Object Captioning, assessed through three different evaluation methods.
https://a16z.com/how-are-consumers-using-generative-ai/
1. Most leading products are built from the “ground up” around generative AI
Like ChatGPT, the majority of products on this list didn’t exist a year ago—80% of these websites are new Of the 50 companies on the list, only 5 are products of, or acquisitions by, pre-existing big tech companies... Of the remaining list members, a whopping 48% are completely bootstrapped, with no outside funding, according to PitchBook data.
2. ChatGPT has a massive lead, for now…
ChatGPT represents 60% of monthly traffic to the entire top 50 list, with an estimated 1.6 billion monthly visits and 200 million monthly users (as of June 2023). This makes ChatGPT the 24th most visited website globally.
3. LLM assistants (like ChatGPT) are dominant, but companionship and creative tools are on the rise
General LLM chatbots represent 68% of total consumer traffic to the top 50 list. However, two other categories have started to drive significant usage in recent months—AI companions (such as CharacterAI) and content generation tools (such as Midjourney and ElevenLabs). Within the broader content generation category, image generation is the top use case with 41% of traffic, followed by prosumer writing tools at 26%, and video generation at 8%. Another category worth mentioning? Model hubs. There are only 2 on the list, but they drive significant traffic—Civitai (for images) and Hugging Face both rank in the top 10. This is especially impressive because consumers are typically visiting these sites to download models to run locally, so web traffic is likely an underestimate of actual usage.
4. Early “winners” have emerged, but most product categories are up for grabs
Good news for builders: despite the surge in interest in generative AI, in many categories there is not yet a runway success.
5. Acquisition for top products is entirely organic—and consumers are willing to pay!
The majority of companies on this list have no paid marketing (at least, that SimilarWeb is able to attribute). There is significant free traffic “available” via X, Reddit, Discord, and email, as well as word of mouth and referral growth. And consumers are willing to pay for GenAI. 90% of companies on the list are already monetizing, nearly all of them via a subscription model. The average product on the list makes $21/month (for users on monthly plans)—yielding $252 annually.
6. Mobile apps are still emerging as a GenAI platform
Consumer AI products have, thus far, been largely browser-first, rather than app-first. Even ChatGPT took 6 months to launch a mobile app! Why aren’t more AI companies building on mobile? The browser is a natural starting place to reach the broadest base of consumers. Many AI companies have small teams and likely don’t want to fragment their focus and resources across Web, iOS, and Android. Given that the average consumer now spends 36 minutes more per day on mobile than desktop (4.1 hours vs. 3.5 hours), we expect to see more mobile-first GenAI products emerge as the technology matures.
https://wordpress.org/plugins/activitypub/
I can't believe I missed this announcement. This is great to see!
Enter the fediverse with ActivityPub, broadcasting your blog to a wider audience! Attract followers, deliver updates, and receive comments from a diverse user base of ActivityPub-compliant platforms.
With the ActivityPub plugin installed, your WordPress blog itself function as a federated profile, along with profiles for each author. For instance, if your website is example.com, then the blog-wide profile can be found at @example.com@example.com, and authors like Jane and Bob would have their individual profiles at @jane@example.com and @bobz@example.com, respectively.
https://huggingface.co/spaces/coqui/xtts
XTTS is a Voice generation model that lets you clone voices into different languages by using just a quick 3-second audio clip.
XTTS is built on previous research, like Tortoise, with additional architectural innovations and training to make cross-language voice cloning and multilingual speech generation possible.
https://huggingface.co/blog/wuerstchen
Würstchen is a diffusion model, whose text-conditional component works in a highly compressed latent space of images. Why is this important? Compressing data can reduce computational costs for both training and inference by orders of magnitude. Training on 1024×1024 images is way more expensive than training on 32×32. Usually, other works make use of a relatively small compression, in the range of 4x - 8x spatial compression. Würstchen takes this to an extreme. Through its novel design, it achieves a 42x spatial compression! This had never been seen before, because common methods fail to faithfully reconstruct detailed images after 16x spatial compression. Würstchen employs a two-stage compression, what we call Stage A and Stage B. Stage A is a VQGAN, and Stage B is a Diffusion Autoencoder (more details can be found in the paper). Together Stage A and B are called the Decoder, because they decode the compressed images back into pixel space. A third model, Stage C, is learned in that highly compressed latent space. This training requires fractions of the compute used for current top-performing models, while also allowing cheaper and faster inference. We refer to Stage C as the Prior.
https://huggingface.co/blog/t2i-sdxl-adapters
T2I-Adapter is an efficient plug-and-play model that provides extra guidance to pre-trained text-to-image models while freezing the original large text-to-image models. T2I-Adapter aligns internal knowledge in T2I models with external control signals. We can train various adapters according to different conditions and achieve rich control and editing effects.
Over the past few weeks, the Diffusers team and the T2I-Adapter authors have been collaborating to bring the support of T2I-Adapters for Stable Diffusion XL (SDXL) in diffusers. In this blog post, we share our findings from training T2I-Adapters on SDXL from scratch, some appealing results, and, of course, the T2I-Adapter checkpoints on various conditionings (sketch, canny, lineart, depth, and openpose)!
https://huggingface.co/blog/falcon-180b
Today, we're excited to welcome TII's Falcon 180B to HuggingFace! Falcon 180B sets a new state-of-the-art for open models. It is the largest openly available language model, with 180 billion parameters, and was trained on a massive 3.5 trillion tokens using TII's RefinedWeb dataset. This represents the longest single-epoch pretraining for an open model.
https://retool.com/visual-basic/
How Visual Basic became the world's most dominant programming environment, its sudden fall from grace, and why its influence is still shaping the future of software development.
https://www.modular.com/blog/mojo-its-finally-here
Today, we’re excited to announce the next big step in Mojo’s evolution: Mojo is now available for local download – beginning with Linux systems, and adding Mac and Windows in coming releases.
https://github.com/Textualize/textual-web
Textual Web publishes Textual apps and terminals on the web.
https://www.dreadcentral.com/the-overlook-motel/
I'm a fan of finding hidden gems and overlooked films, especially when it comes to horror. It's how I came across some of my favorites like Hell House and Terrifier. That's why I was excited to run into The Overlook Motel series from Dread Central which spotlights these kinds of films.

https://mullvad.net/en/blog/2023/9/7/tailscale-has-partnered-with-mullvad/
Today we announce a partnership with Tailscale that allows you to use both in conjunction through the Tailscale app. This functionality is not available through the Mullvad VPN app.
This partnership allows customers of Tailscale to make use of our WireGuard VPN servers as “exit nodes”. This means that whilst connected to Tailscale, you can access your devices across Tailscale’s mesh network, whilst still connecting outbound through Mullvad VPN WireGuard servers in any location.
https://www.jwz.org/blog/2023/09/platos-cave-regrets-to-inform-you-it-will-be-raising-its-rent/
If you are receiving this letter, it means you have been designated a tenant of the cave—i.e., you are chained to the wall, you are forced to watch shadows for all eternity, you are projecting said shadow puppets, and/or you are a philosopher who was able to break free and understand the true shackles of reality (PhD candidates about to argue their thesis).
We do not undertake this lightly. As the costs of maintaining a cave meant to trap you in your ignorance increases year after year, we want you to know, from the bottom of our hearts, that we, too, are suffering. We get that times are tough, and we hope you can extend that sympathy to us, the managers of your cave.
Please rest assured that cave costs are increasing everywhere. We manage many other caves like that of Polyphemus the Cyclops and the childhood home of Zeus. So, trust us: we know caves.
We hope you will continue to enjoy living in our cave. We believe you are a valued part of the Plato's Cave community. Credit, cash, or Venmo all work.
Original Source: https://www.mcsweeneys.net/articles/platos-cave-regrets-to-inform-you-it-will-be-raising-its-rent

https://www.aaron-powell.com/posts/2023-09-04-generative-ai-and-dotnet---part-2-sdk/
It’s time to have a look at how we can build the basics of an application using Azure OpenAI Services and the .NET SDK.
https://community.torproject.org/onion-services/setup/
This guide shows you how to set up an Onion Service for your website. For the technical details of how the Onion Service protocol works, see our Onion Service protocol page.
https://spectrum.ieee.org/doctorow-interoperability
In his new book The Internet Con: How to Seize the Means of Computation, author Cory Doctorow presents a strong case for disrupting Big Tech. While the dominance of Internet platforms like Twitter, Facebook, Instagram, or Amazon is often taken for granted, Doctorow argues that these walled gardens are fenced in by legal structures, not feats of engineering. Doctorow proposes forcing interoperability—any given platform’s ability to interact with another—as a way to break down those walls and to make the Internet freer and more democratic.
https://www.microsoft.com/en-us/research/blog/rethinking-trust-in-direct-messages-in-the-ai-era/
This blog post is a part of a series exploring our research in privacy, security, and cryptography. For the previous post, see https://www.microsoft.com/en-us/research/blog/research-trends-in-privacy-security-and-cryptography. While AI has the potential to massively increase productivity, this power can be used equally well for malicious purposes, for example, to automate the creation of sophisticated scam messages. In this post, we explore threats AI can pose for online communication ecosystems and outline a high-level approach to mitigating these threats.
https://perplexity.vercel.app/
I built this little tool to help me understand what it's like to be an autoregressive language model. For any given passage of text, it augments the original text with highlights and annotations that tell me how "surprising" each token is to the model, and which other tokens the model thought were most likely to occur in its place. Right now, the LM I'm using is the smallest version of GPT-2, with 124M parameters.
https://www.fast.ai/posts/2023-09-04-learning-jumps/
Summary: recently while fine-tuning a large language model (LLM) on multiple-choice science exam questions, we observed some highly unusual training loss curves. In particular, it appeared the model was able to rapidly memorize examples from the dataset after seeing them just once. This astonishing feat contradicts most prior wisdom about neural network sample efficiency. Intrigued by this result, we conducted a series of experiments to validate and better understand this phenomenon. It’s early days, but the experiments support the hypothesis that the models are able to rapidly remember inputs. This might mean we have to re-think how we train and use LLMs.
This article reminds me of this gem 😂

https://openai.com/blog/teaching-with-ai
We’re releasing a guide for teachers using ChatGPT in their classroom—including suggested prompts, an explanation of how ChatGPT works and its limitations, the efficacy of AI detectors, and bias.
Solo by Pixelfed
We've been secretly building a single user federated photo sharing server (based on Pixelfed), with minimal setup, and built-in import
Solo is simple, download the code, drag your photos to the media directory and open your browser
So simple, yet super smart, Solo won't get in your way, but it will impress
Launching Oct 2023
Very excited about this!
https://www.aaron-powell.com/posts/2023-09-01-generative-ai-and-dotnet---part-1-intro/
over this series I’m going to share my learnings on the APIs, SDKs, and the like. The goal here isn’t to “build something” but rather to share what I’ve learnt, the mistakes I’ve made, the things I’ve found confusing, and the code I’ve had to rewrite umpteen times because “oh, that’s a better way to do it”.
Llama 2 7B/13B are now available in Web LLM!
Llama 2 70B is also supported.
This project brings large-language model and LLM-based chatbot to web browsers. Everything runs inside the browser with no server support and accelerated with WebGPU. This opens up a lot of fun opportunities to build AI assistants for everyone and enable privacy while enjoying GPU acceleration.
https://a16z.com/2023/08/30/supporting-the-open-source-ai-community/
We believe artificial intelligence has the power to save the world—and that a thriving open source ecosystem is essential to building this future.
To help close this resource gap, we’re announcing today the a16z Open Source AI Grant program. We’ll support a small group of open source developers through grant funding (not an investment or SAFE note), giving them the opportunity to continue their work without the pressure to generate financial returns.
https://www.reality2cast.com/151
Good discussion on the open web, self-hosting, radio, and the indie web.
https://simonwillison.net/2023/Aug/27/wordcamp-llms/
My goal today is to provide practical, actionable advice for getting the most out of Large Language Models—both for personal productivity but also as a platform that you can use to build things that you couldn’t build before.
https://www.newyorker.com/culture/cultural-comment/we-dont-need-a-new-twitter
If Meta can succeed in capturing some of this peak-Twitter magic, while avoiding late-stage Twitter’s struggles, the company will perhaps even reclaim some of the cultural gravity that it squandered a decade ago when Facebook took its turn toward crazy-uncle irrelevance. But can Meta possibly succeed in building a saner, nicer Twitter?
Breaking news can spread quickly, as can clips that are funny in an original or strange way—but these innocuous trends feel serendipitous, like a rainbow spanning storm clouds. To reach the Twitter masses, conspiracy, demagoguery, and cancellation are much more likely to succeed. The result is a Faustian bargain for our networked era: trusting the wisdom of crowds to identify what’s interesting can create an intensely compelling stream of shared content, but this content is likely to arrive drenched in rancor.
The obvious way Meta can attempt to escape this bargain is by moving Threads away from retransmission-based curation and toward algorithmic ranking. This will give the company more control over which discussions are amplified, but, in doing so, they will also lose the human-powered selectivity that makes Twitter so engaging.
If we look past this narrow discussion of Threads’ challenges, however, a broader question arises: Why is it so important to create a better version of Twitter in the first place? Ignored amid the hand-wringing about the toxic turn taken by large-scale conversation platforms are the many smaller, less flashy sites and services that have long been supporting a more civilized form of digital interaction.
“The Internet has become the ultimate narrowcasting vehicle: everyone from UFO buffs to New York Yankee fans has a Website (or dozen) to call his own,” the journalist Richard Zoglin wrote in 1996. “A dot-com in every pot.”
We’ve gone from Zoglin’s dot-com in every pot to the social-media age’s vision of every pot being filled with slop from the same platforms.
https://studio.ribbonfarm.com/p/against-waldenponding
Waldenponding (after Thoreau's Walden Pond experiment on which Walden is based). The crude caricature is "smash your smart phone and go live in a log cabin to reclaim your attention and your life from being hacked by evil social media platforms."
https://tomcritchlow.com/2022/04/21/new-rss/
RSS is kind of an invisible technology. People call RSS dead because you can’t see it. There’s no feed, no login, no analytics. RSS feels subsurface.
Come to think of it - all the interesting bits of blogging are invisible. The discussion has moved to Twitter, or discords, or DMs. Trackbacks aren’t a thing anymore. So when you see someone blogging all you see is the blog post. The branching replies and conversations are either invisible or hard to track down.
But I believe we’re living in a golden age of RSS. Blogging is booming. My feed reader has 280 feeds in it.
How do we increase the surface area of RSS and blogging?
I think there’s something quietly radical about making your feed reader open by default. It increases the surface area of RSS so others can discover content more easily. It makes blogging more visible.
The nice thing about RSS and OPML is that’s a very extensible spec. The file format is flexible, you can define your own schema and fields. This might open up new kinds of publishing.
About Feeds is a free site from Matt Webb. I made this site because using web feeds for the first time is hard, and we can fix that.
https://www.edge.org/conversation/marvin_minsky-consciousness-is-a-big-suitcase
Marvin Minsky is the leading light of AI—artificial intelligence, that is. He sees the brain as a myriad of structures. Scientists who, like Minsky, take the strong AI view believe that a computer model of the brain will be able to explain what we know of the brain's cognitive abilities. Minsky identifies consciousness with high-level, abstract thought, and believes that in principle machines can do everything a conscious human being can do.
A graphical Unix-like operating system for desktop computers!
SerenityOS is a love letter to '90s user interfaces with a custom Unix-like core. It flatters with sincerity by stealing beautiful ideas from various other systems.
Roughly speaking, the goal is a marriage between the aesthetic of late-1990s productivity software and the power-user accessibility of late-2000s *nix.
This is a system by us, for us, based on the things we like.
https://ai.meta.com/blog/code-llama-large-language-model-coding/
Takeaways
- Code Llama is a state-of-the-art LLM capable of generating code, and natural language about code, from both code and natural language prompts.
- Code Llama is free for research and commercial use.
- Code Llama is built on top of Llama 2 and is available in three models:
- Code Llama, the foundational code model;
- Codel Llama - Python specialized for Python;
- and Code Llama - Instruct, which is fine-tuned for understanding natural language instructions.
- In our own benchmark testing, Code Llama outperformed state-of-the-art publicly available LLMs on code tasks
Today we’re announcing a significant evolution in the analytical capabilities available within Excel by releasing a Public Preview of Python in Excel. Python in Excel makes it possible to natively combine Python and Excel analytics within the same workbook - with no setup required. With Python in Excel, you can type Python directly into a cell, the Python calculations run in the Microsoft Cloud, and your results are returned to the worksheet, including plots and visualizations.
https://www.deeplearning.ai/short-courses/large-language-models-semantic-search/
Keyword search has been a common method for search for many years. But for content-rich websites like news media sites or online shopping platforms, the keyword search capability can be limiting. Incorporating large language models (LLMs) into your search can significantly enhance the user experience by allowing them to ask questions and find information in a much easier way.
This course teaches the techniques needed to leverage LLMs into search.
Throughout the lessons, you’ll explore key concepts like dense retrieval, which elevates the relevance of retrieved information, leading to improved search results beyond traditional keyword search, and reranking, which injects the intelligence of LLMs into your search system, making it faster and more effective.
https://eugeneyan.com/writing/llm-patterns/
There are seven key patterns. They’re also organized along the spectrum of improving performance vs. reducing cost/risk, and closer to the data vs. closer to the user.
- Evals: To measure performance
- RAG: To add recent, external knowledge
- Fine-tuning: To get better at specific tasks
- Caching: To reduce latency & cost
- Guardrails: To ensure output quality
- Defensive UX: To anticipate & manage errors gracefully
- Collect user feedback: To build our data flywheel
Addendum: how to match these LLM patterns to potential problems
https://github.com/huggingface/candle
Candle is a minimalist ML framework for Rust with a focus on performance (including GPU support) and ease of use.
https://huyenchip.com/2023/08/16/llm-research-open-challenges.html
- Reduce and measure hallucinations
- Optimize context length and context construction
- Incorporate other data modalities
- Make LLMs faster and cheaper
- Design a new model architecture
- Develop GPU alternatives
- Make agents usable
- Improve learning from human preference
- Improve the efficiency of the chat interface
- Build LLMs for non-English languages
https://www.infoq.com/news/2023/08/jupyter-ai-notebooks/
The open-source Project Jupyter, used by millions for data science and machine learning, has released Jupyter AI, a free tool bringing powerful generative AI capabilities to Jupyter notebooks.
https://jupyter-ai.readthedocs.io/en/latest/
Jupyter AI, which brings generative AI to Jupyter. Jupyter AI provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. More specifically, Jupyter AI offers:
An %%ai magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, VSCode, etc.).
A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant.
Support for a wide range of generative model providers and models (AI21, Anthropic, Cohere, Hugging Face, OpenAI, SageMaker, etc.).
Interesting project.
RetroStrange is part independent media experiment, part handmade exaltation of vintage weirdness and the public domain. It is produced by Noah Maher and Phil Nelson.
https://developer.wordpress.org/playground/
Not a WordPress user but this is cool, especially this - "Build an entire site, save it, host it"
WordPress Playground makes WordPress instantly accessible for users, learners, extenders, and contributors. You can:
- Try a block, a theme, or a plugin
- Build an entire site, save it, host it
- Test your plugin with many specific WordPress and PHP versions
- Embed a real, interactive WordPress site in your tutorial or course
- Showcase a plugin or theme on your website
- Preview pull requests from your repository
- …or even run WordPress locally using the VisualStudio Code plugin or a CLI tool called wp-now
a loose association of like-minded tilde communities.
tildes are pubnixes in the spirit of tilde.club, which was created in 2014 by paul ford.
Public Access UNIX Systems (PAUS) are a type of server that provide various services to a multi-user community. They first began in the early 1980's and continue today. Early servers ran various flavors of UNIX, hence the name Public Access "UNIX" Systems, but later generations saw a large mix of Unix-variants and, of course, GNU/Linux. To recognize the many different operating systems online today, these systems are increasingly referred to generically as "pubnixes". - Pubnix Hist
https://nick-black.com/htp-notcurses.pdf
A TUI (text user interface) is a holistic model, view, and controller implemented using character graphics. TUIs, like WIMP3 GUIs, freely move the cursor around their rectilinear display, as opposed to line-oriented CLIs and their ineluctable marches through the scrolling region. Given the same interactive task
• A TUI implementation is almost certainly a smaller memory and disk footprint than a GUI,
• a good TUI implementation might introduce less latency, and
• a properly-done TUI implementation can often be significantly more portable.
https://the-dam.org/docs/explanations/suc.html
suc provides Slack, Mattermost, etc.’s core features:
Real-time, rich-text chat,
File sharing,
Fine-grained access control,
Straightforward automation and integration with other tools,
Data encryption in transit
and optionally at rest,
state-of-the-art user authentication.This paper shows how suc implements those features. suc stays small by leveraging the consistent and composable primitives offered by modern UNIX implementations
https://creatoreconomy.so/p/kaz-coo-shopify-craft-and-no-meetings
The difference between crafters and managers
The difference is in what you spend time on.
"Most people get satisfaction from building — from actually creating things."
As companies scale, optics start playing a larger role. People start spending more time on internal docs than actually talking to customers. How do you prevent this from happening at Shopify?
In most product reviews, product managers spend way too much time preparing the perfect presentation for execs.
At Shopify, our approach to product reviews is different. We want to see how the product actually works by playing with the demo or diving into the code.
We want our PMs to be extremely user-focused, to take full ownership over problems, and to have a high tolerance for risk.
If these attributes aren't present, product managers tend to become "keepers of strategy.” You end up with smart, highly credentialed individuals spending all their time writing strategy memos to increase their team size so that they can write even more strategy memos.
How Shopify rages against meetings
In early 2023, Shopify initiated operation “Chaos Monkey” to:
- Cancel all meetings with 3+ people
- Reinstate “no meeting Wednesdays”
- Remove needless Slack channels
Does Shopify have a strong writing culture to help people communicate without meetings?
Yes, we try to make async decisions as much as we can. We do this in a few ways:
One of our mantras is “Do things, tell people.” You’ll see this plastered on our walls if you come to Shopify’s office.
We built an operating system called GSD (get shit done). This internal tool emphasizes frequent written updates, which are much easier to digest than constant meetings.
A meeting is a bug that some other process didn’t work out.
We focus on the mission. We want to be the all-in-one commerce platform for people to start and grow businesses. We try to avoid getting distracted by other side quests.
The main thing is to keep the main thing the main thing.
Today we announce the formation of xAI.
The goal of xAI is to understand the true nature of the universe.
https://keras.io/keras_core/announcement/
We're excited to share with you a new library called Keras Core, a preview version of the future of Keras. In Fall 2023, this library will become Keras 3.0. Keras Core is a full rewrite of the Keras codebase that rebases it on top of a modular backend architecture. It makes it possible to run Keras workflows on top of arbitrary frameworks — starting with TensorFlow, JAX, and PyTorch.
Keras Core is also a drop-in replacement for tf.keras, with near-full backwards compatibility with tf.keras code when using the TensorFlow backend. In the vast majority of cases you can just start importing it via import keras_core as keras in place of from tensorflow import keras and your existing code will run with no issue — and generally with slightly improved performance, thanks to XLA compilation.
https://openai.com/blog/gpt-4-api-general-availability
GPT-4 API general availability and deprecation of older models in the Completions API. GPT-3.5 Turbo, DALL·E and Whisper APIs are also generally available, and we are releasing a deprecation plan for older models of the Completions API, which will retire at the beginning of 2024.
The 512KB Club is a collection of performance-focused web pages from across the Internet. To qualify your website must satisfy both of the following requirements:
- It must be an actual site that contains a reasonable amount of information, not just a couple of links on a page (more info here).
- Your total UNCOMPRESSED web resources must not exceed 512KB.
1MB Club is a growing collection of performance-focused web pages weighing less than 1 megabyte.
https://proton.me/blog/proton-pass-launch
We’re happy to announce the global launch of Proton Pass...a password manager, one of the most highly demanded services from the Proton community in our annual surveys since we first launched Proton Mail...
I'm really enjoying the sessions. Kudos to the team who put it together and presenters delivering great content.
If you're interested, check out the stream at http://fsharpconf.com/.


List of resources from the Reclaim Open 2023 Conference.
https://arxiv.org/pdf/2306.02707.pdf
Recent research has focused on enhancing the capability of smaller models through imitation learning, drawing on the outputs generated by large foundation models (LFMs). A number of issues impact the quality of these models, ranging from limited imitation signals from shallow LFM outputs; small scale homogeneous training data; and most notably a lack of rigorous evaluation resulting in overestimating the small model’s capability as they tend to learn to imitate the style, but not the reasoning process of LFMs. To address these challenges, we develop Orca, a 13-billion parameter model that learns to imitate the reasoning process of LFMs. Orca learns from rich signals from GPT-4 including explanation traces; step-by-step thought processes; and other complex instructions, guided by teacher assistance from ChatGPT. To promote this progressive learning, we tap into large-scale and diverse imitation data with judicious sampling and selection. Orca surpasses conventional state-of-the-art instruction-tuned models such as Vicuna-13B by more than 100% in complex zero-shot reasoning benchmarks like Big- Bench Hard (BBH) and 42% on AGIEval. Moreover, Orca reaches parity with ChatGPT on the BBH benchmark and shows competitive performance (4 pts gap with optimized system message) in professional and academic examinations like the SAT, LSAT, GRE, and GMAT, both in zero-shot settings without CoT; while trailing behind GPT-4. Our research indicates that learning from step-by-step explanations, whether these are generated by humans or more advanced AI models, is a promising direction to improve model capabilities and skills.
https://gorilla.cs.berkeley.edu/
Large Language Models (LLMs) have seen an impressive wave of advances recently, with models now excelling in a variety of tasks, such as mathematical reasoning and program synthesis. However, their potential to effectively use tools via API calls remains unfulfilled. This is a challenging task even for today's state-of-the-art LLMs such as GPT-4, largely due to their inability to generate accurate input arguments and their tendency to hallucinate the wrong usage of an API call. We release Gorilla, a finetuned LLaMA-based model that surpasses the performance of GPT-4 on writing API calls. When combined with a document retriever, Gorilla demonstrates a strong capability to adapt to test-time document changes, enabling flexible user updates or version changes. It also substantially mitigates the issue of hallucination, commonly encountered when prompting LLMs directly. To evaluate the model's ability, we introduce APIBench, a comprehensive dataset consisting of HuggingFace, TorchHub, and TensorHub APIs. The successful integration of the retrieval system with Gorilla demonstrates the potential for LLMs to use tools more accurately, keep up with frequently updated documentation, and consequently increase the reliability and applicability of their outputs.
https://arxiv.org/abs/2305.10973
...we propose DragGAN, which consists of two main components: 1) a feature-based motion supervision that drives the handle point to move towards the target position, and 2) a new point tracking approach that leverages the discriminative generator features to keep localizing the position of the handle points. Through DragGAN, anyone can deform an image with precise control over where pixels go, thus manipulating the pose, shape, expression, and layout of diverse categories such as animals, cars, humans, landscapes, etc. As these manipulations are performed on the learned generative image manifold of a GAN, they tend to produce realistic outputs even for challenging scenarios such as hallucinating occluded content and deforming shapes that consistently follow the object's rigidity. Both qualitative and quantitative comparisons demonstrate the advantage of DragGAN over prior approaches in the tasks of image manipulation and point tracking. We also showcase the manipulation of real images through GAN inversion.
https://huggingface.co/blog/starcoder
StarCoder and StarCoderBase are Large Language Models for Code (Code LLMs) trained on permissively licensed data from GitHub, including from 80+ programming languages, Git commits, GitHub issues, and Jupyter notebooks. Similar to LLaMA, we trained a ~15B parameter model for 1 trillion tokens. We fine-tuned StarCoderBase model for 35B Python tokens, resulting in a new model that we call StarCoder.
https://github.com/microsoft/LoRA
LoRA reduces the number of trainable parameters by learning pairs of rank-decompostion matrices while freezing the original weights. This vastly reduces the storage requirement for large language models adapted to specific tasks and enables efficient task-switching during deployment all without introducing inference latency. LoRA also outperforms several other adaptation methods including adapter, prefix-tuning, and fine-tuning.
https://arxiv.org/abs/2305.02463
We present Shap-E, a conditional generative model for 3D assets. Unlike recent work on 3D generative models which produce a single output representation, Shap-E directly generates the parameters of implicit functions that can be rendered as both textured meshes and neural radiance fields. We train Shap-E in two stages: first, we train an encoder that deterministically maps 3D assets into the parameters of an implicit function; second, we train a conditional diffusion model on outputs of the encoder. When trained on a large dataset of paired 3D and text data, our resulting models are capable of generating complex and diverse 3D assets in a matter of seconds. When compared to Point-E, an explicit generative model over point clouds, Shap-E converges faster and reaches comparable or better sample quality despite modeling a higher-dimensional, multi-representation output space.
https://wordpress.com/blog/2023/06/01/newsletters-paid-subscriptions/
...we’re introducing a big update — the ability to add paid subscriptions and premium content, whatever plan you’re on. Including the Free plan.
Paid subscriptions let your fans support your art, writing, or project directly.
https://ai.facebook.com/blog/multilingual-model-speech-recognition/
The Massively Multilingual Speech (MMS) project expands speech technology from about 100 languages to over 1,000 by building a single multilingual speech recognition model supporting over 1,100 languages (more than 10 times as many as before), language identification models able to identify over 4,000 languages (40 times more than before), pretrained models supporting over 1,400 languages, and text-to-speech models for over 1,100 languages. Our goal is to make it easier for people to access information and to use devices in their preferred language.
https://ai.google/discover/palm2
PaLM 2 is our next generation large language model that builds on Google’s legacy of breakthrough research in machine learning and responsible AI.
It excels at advanced reasoning tasks, including code and math, classification and question answering, translation and multilingual proficiency, and natural language generation better than our previous state-of-the-art LLMs, including PaLM. It can accomplish these tasks because of the way it was built – bringing together compute-optimal scaling, an improved dataset mixture, and model architecture improvements.
PaLM 2 is grounded in Google’s approach to building and deploying AI responsibly. It was evaluated rigorously for its potential harms and biases, capabilities and downstream uses in research and in-product applications. It’s being used in other state-of-the-art models, like Med-PaLM 2 and Sec-PaLM, and is powering generative AI features and tools at Google, like Bard and the PaLM API.
https://huggingface.co/docs/transformers/en/transformers_agents
Transformers Agent...provides a natural language API on top of transformers: we define a set of curated tools and design an agent to interpret natural language and to use these tools. It is extensible by design; we curated some relevant tools, but we’ll show you how the system can be extended easily to use any tool developed by the community.
https://githubnext.com/projects/copilot-for-docs
Whether you’re learning a new library or API or you’ve been using it for years, it can feel like the documentation gets in your way more than it helps. Maybe the tutorials are too basic, or the reference manual is too sketchy, or the relevant information is split across multiple pages full of irrelevant details.
We’re exploring a way to get you the information you need, faster. By surfacing the most relevant content for questions with tailored summaries that help connect the dots, Copilot for docs saves developers from scouring reams of documentation.
https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/
In ChatGPT Prompt Engineering for Developers, you will learn how to use a large language model (LLM) to quickly build new and powerful applications. Using the OpenAI API, you’ll be able to quickly build capabilities that learn to innovate and create value in ways that were cost-prohibitive, highly technical, or simply impossible before now.
https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/
...ImageBind, the first AI model capable of binding information from six modalities. The model learns a single embedding, or shared representation space, not just for text, image/video, and audio, but also for sensors that record depth (3D), thermal (infrared radiation), and inertial measurement units (IMU), which calculate motion and position.
https://openaipublic.blob.core.windows.net/neuron-explainer/paper/index.html
This paper applies automation to the problem of scaling an interpretability technique to all the neurons in a large language model. Our hope is that building on this approach of automating interpretability will enable us to comprehensively audit the safety of models before deployment.
Our technique seeks to explain what patterns in text cause a neuron to activate. It consists of three steps:
- Explain the neuron's activations using GPT-4
- Simulate activations using GPT-4, conditioning on the explanation
- Score the explanation by comparing the simulated and real activations
https://huggingface.co/blog/peft
...as models get larger and larger, full fine-tuning becomes infeasible to train on consumer hardware. In addition, storing and deploying fine-tuned models independently for each downstream task becomes very expensive, because fine-tuned models are the same size as the original pretrained model. Parameter-Efficient Fine-tuning (PEFT) approaches are meant to address both problems!
PEFT approaches only fine-tune a small number of (extra) model parameters while freezing most parameters of the pretrained LLMs, thereby greatly decreasing the computational and storage costs. This also overcomes the issues of catastrophic forgetting, a behaviour observed during the full finetuning of LLMs. PEFT approaches have also shown to be better than fine-tuning in the low-data regimes and generalize better to out-of-domain scenarios. It can be applied to various modalities, e.g., image classification and stable diffusion dreambooth.
https://blog.jim-nielsen.com/2023/offline-is-online-with-extreme-latency/
you can think of online/offline as part of the same continuum just different measurements of latency. There are gradations of latency when you’re “online”, and “offline” is merely at the slowest end of that spectrum.
LLaVA represents a novel end-to-end trained large multimodal model that combines a vision encoder and Vicuna for general-purpose visual and language understanding, achieving impressive chat capabilities mimicking spirits of the multimodal GPT-4 and setting a new state-of-the-art accuracy on Science QA.
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks in the language domain, but the idea is less explored in the multimodal field.
1. Multimodal Instruct Data. We present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. 2. LLaVA Model. We introduce LLaVA (Large Language-and-Vision Assistant), an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding. 3. Performance. Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. 4. Open-source. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
https://developer.mozilla.org/en-US/docs/Web/API/WebGPU_API
The WebGPU API enables web developers to use the underlying system's GPU (Graphics Processing Unit) to carry out high-performance computations and draw complex images that can be rendered in the browser.
https://github.com/openai/consistency_models
Paper: https://arxiv.org/abs/2303.01469
Diffusion models have made significant breakthroughs in image, audio, and video generation, but they depend on an iterative generation process that causes slow sampling speed and caps their potential for real-time applications. To overcome this limitation, we propose consistency models, a new family of generative models that achieve high sample quality without adversarial training. They support fast one-step generation by design, while still allowing for few-step sampling to trade compute for sample quality. They also support zero-shot data editing, like image inpainting, colorization, and super-resolution, without requiring explicit training on these tasks. Consistency models can be trained either as a way to distill pre-trained diffusion models, or as standalone generative models. Through extensive experiments, we demonstrate that they outperform existing distillation techniques for diffusion models in one- and few-step generation. For example, we achieve the new state-of-the-art FID of 3.55 on CIFAR-10 and 6.20 on ImageNet 64x64 for one-step generation. When trained as standalone generative models, consistency models also outperform single-step, non-adversarial generative models on standard benchmarks like CIFAR-10, ImageNet 64x64 and LSUN 256x256.
https://arxiv.org/pdf/2304.03442.pdf
In this paper, we introduce generative agents—computational software agents that simulate believable human behavior. Generative agents wake up, cook breakfast, and head to work; artists paint, while authors write; they form opinions, notice each other, and initiate conversations; they remember and reflect on days past as they plan the next day. To enable generative agents, we describe an architecture that extends a large language model to store a complete record of the agent’s experiences using natural language, synthesize those memories over time into higher-level reflections, and retrieve them dynamically to plan behavior. We instantiate generative agents to populate an interactive sandbox environment inspired by The Sims, where end users can interact with a small town of twenty five agents using natural language. In an evaluation, these generative agents produce believable individual and emergent social behaviors...
By fusing large language models with computational, interactive agents, this work introduces architectural and interaction patterns for enabling believable simulations of human behavior.
https://bair.berkeley.edu/blog/2023/04/03/koala/
...Koala, a chatbot trained by fine-tuning Meta’s LLaMA on dialogue data gathered from the web.
Many of the most capable LLMs require huge computational resources to train, and oftentimes use large and proprietary datasets. This suggests that in the future, highly capable LLMs will be largely controlled by a small number of organizations, and both users and researchers will pay to interact with these models without direct access to modify and improve them on their own. On the other hand, recent months have also seen the release of increasingly capable freely available or (partially) open-source models, such as LLaMA. These systems typically fall short of the most capable closed models, but their capabilities have been rapidly improving. This presents the community with an important question: will the future see increasingly more consolidation around a handful of closed-source models, or the growth of open models with smaller architectures that approach the performance of their larger but closed-source cousins?
Our results suggest that learning from high-quality datasets can mitigate some of the shortcomings of smaller models, maybe even matching the capabilities of large closed-source models in the future.
https://www.fast.ai/posts/part2-2023.html
From Deep Learning Foundations to Stable Diffusion...is part 2 of Practical Deep Learning for Coders.
In this course, containing over 30 hours of video content, we implement the astounding Stable Diffusion algorithm from scratch!
https://learn.microsoft.com/semantic-kernel/howto/schillacelaws
The "Schillace Laws" were formulated after working with a variety of Large Language Model (LLM) AI systems to date. Knowing them will accelerate your journey into this exciting space of reimagining the future of software engineering.
https://blog.darklang.com/gpt/
On February 1, we stopped working on what we're now calling "darklang-classic", and are fully heads down on building "darklang-gpt", which is the same core Darklang but redesigned to have AI as the primary (or possibly only) way of writing code.
https://laion.ai/blog/open-flamingo/
...OpenFlamingo, an open-source reproduction of DeepMind's Flamingo model. At its core, OpenFlamingo is a framework that enables training and evaluation of large multimodal models (LMMs).
https://www.cerebras.net/blog/cerebras-gpt-a-family-of-open-compute-efficient-large-language-models/
Cerebras open sources seven GPT-3 models from 111 million to 13 billion parameters. Trained using the Chinchilla formula, these models set new benchmarks for accuracy and compute efficiency.
Today’s release is designed to be used by and reproducible by anyone. All models, weights, and checkpoints are available on Hugging Face and GitHub under the Apache 2.0 license. Additionally, we provide detailed information on our training methods and performance results in our forthcoming paper. The Cerebras CS-2 systems used for training are also available on-demand via Cerebras Model Studio.
https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/
This post only focuses on prompt engineering for autoregressive language models, so nothing with Cloze tests, image generation or multimodality models. At its core, the goal of prompt engineering is about alignment and model steerability.
https://openai.com/product/gpt-4
GPT-4 can accept images as inputs and generate captions, classifications, and analyses.
GPT-4 is capable of handling over 25,000 words of text, allowing for use cases like long form content creation, extended conversations, and document search and analysis.
https://crfm.stanford.edu/2023/03/13/alpaca.html
We are releasing our findings about an instruction-following language model, dubbed Alpaca, which is fine-tuned from Meta’s LLaMA 7B model. We train the Alpaca model on 52K instruction-following demonstrations generated in the style of self-instruct using text-davinci-003. Alpaca shows many behaviors similar to OpenAI’s text-davinci-003, but is also surprisingly small and easy/cheap to reproduce.
https://danielmiessler.com/blog/spqa-ai-architecture-replace-existing-software/
AI-based applications will be completely different than those we have today. The new architecture will be a far more elegant, four-component structure based around GPTs: State, Policy, Questions, and Action.
A security program using SPQA
Choose the base model — You start with the latest and greatest overall GPT model from OpenAI, Google, Meta, McKinsey, or whoever. Lots of companies will have one. Let’s call it OpenAI’s GPT-6. It already knows so incredibly much about security, biotech, project management, scheduling, meetings, budgets, incident response, and audit preparedness that you might be able to survive with it alone. But you need more personalized context.
Train your custom model — Then you train your custom model which is based on your own data, which will stack on top of GPT-6. This is all the stuff in the STATE section above. It’s your company’s telemetry and context. Logs. Docs. Finances. Chats. Emails. Meeting transcripts. Everything. It’s a small company and there are compression algorithms as part of the Custom Model Generation (CMG) product we use, so it’s a total of 312TB of data. You train your custom model on that.
Train your policy model — Now you train another model that’s all about your company’s desires. The mission, the goals, your anti-goals, your challenges, your strategies. This is the guidance that comes from humans that we’re using to steer the ACTION part of the architecture. When we ask it to make stuff for us, and build out our plans, it’ll do so using the guardrails captured here in the POLICY.
Tell the system to take the following actions — Now the models are combined. We have GPT-6, stacked with our STATE model, also stacked with our POLICY model, and together they know us better than we know ourselves.
https://simonwillison.net/2023/Mar/11/llama/
The race is on to release the first fully open language model that gives people ChatGPT-like capabilities on their own devices.
https://bitwarden.com/blog/access-your-bitwarden-vault-without-a-password/
Bitwarden expands the Log in with device option that lets you use a second device to authenticate your Bitwarden vault login instead of using your Bitwarden password.
Data-Centric AI (DCAI) is an emerging science that studies techniques to improve datasets, which is often the best way to improve performance in practical ML applications. While good data scientists have long practiced this manually via ad hoc trial/error and intuition, DCAI considers the improvement of data as a systematic engineering discipline.
This is the first-ever course on DCAI. This class covers algorithms to find and fix common issues in ML data and to construct better datasets, concentrating on data used in supervised learning tasks like classification. All material taught in this course is highly practical, focused on impactful aspects of real-world ML applications, rather than mathematical details of how particular models work. You can take this course to learn practical techniques not covered in most ML classes, which will help mitigate the “garbage in, garbage out” problem that plagues many real-world ML applications.
https://karpathy.medium.com/software-2-0-a64152b37c35
The “classical stack” of Software 1.0 is what we’re all familiar with — it is written in languages such as Python, C++, etc...Software 2.0 is written in much more abstract, human unfriendly language, such as the weights of a neural network.
Benefits of Software 2.0
- Computationally homogeneous
- Simple to bake into silicon
- Constant running time
- Constant memory use
- Highly portable
- Agile
- Modules can meld into an optimal whole
- It is better than you
Limitations of Software 2.0
At the end of the optimization we’re left with large networks that work well, but it’s very hard to tell how. Across many applications areas, we’ll be left with a choice of using a 90% accurate model we understand, or 99% accurate model we don’t.
The 2.0 stack can fail in unintuitive and embarrassing ways ,or worse, they can “silently fail”
...the existence of adversarial examples and attacks highlights the unintuitive nature of this stack.
Programming Software 2.0
If you recognize Software 2.0 as a new and emerging programming paradigm instead of simply treating neural networks as a pretty good classifier in the class of machine learning techniques, the extrapolations become more obvious, and it’s clear that there is much more work to do.
In particular, we’ve built up a vast amount of tooling that assists humans in writing 1.0 code, such as powerful IDEs with features like syntax highlighting, debuggers, profilers, go to def, git integration, etc. In the 2.0 stack, the programming is done by accumulating, massaging and cleaning datasets. Who is going to develop the first Software 2.0 IDEs, which help with all of the workflows in accumulating, visualizing, cleaning, labeling, and sourcing datasets?
Github is a very successful home for Software 1.0 code. Is there space for a Software 2.0 Github? In this case repositories are datasets and commits are made up of additions and edits of the labels.
Traditional package managers and related serving infrastructure like pip, conda, docker, etc. help us more easily deploy and compose binaries. How do we effectively deploy, share, import and work with Software 2.0 binaries? What is the conda equivalent for neural networks?
https://huggingface.co/blog/blip-2
This guide introduces BLIP-2 from Salesforce Research that enables a suite of state-of-the-art visual-language models that are now available in 🤗 Transformers. We'll show you how to use it for image captioning, prompted image captioning, visual question-answering, and chat-based prompting.
BLIP-2 bridges the modality gap between vision and language models by adding a lightweight Querying Transformer (Q-Former) between an off-the-shelf frozen pre-trained image encoder and a frozen large language model. Q-Former is the only trainable part of BLIP-2; both the image encoder and language model remain frozen.
https://www.schneier.com/blog/archives/2023/02/attacking-machine-learning-systems.html
At their core, modern ML systems have complex mathematical models that use training data to become competent at a task. And while there are new risks inherent in the ML model, all of that complexity still runs in software. Training data are still stored in memory somewhere. And all of that is on a computer, on a network, and attached to the Internet. Like everything else, these systems will be hacked through vulnerabilities in those more conventional parts of the system.
https://github.com/microsoft/LMOps
LMOps is a research initiative on fundamental research and technology for building AI products w/ foundation models, especially on the general technology for enabling AI capabilities w/ LLMs and Generative AI models.
- Better Prompts: Promptist, Extensible prompts
- Longer Context: Structured prompting, Length-Extrapolatable Transformers
- Knowledge Augmentation (TBA)
- Fundamentals
A few updates I found interesting.
The Beauty of languages: You can now use your own voice during a translated call in Skype.
Universal translator: During a Skype call, if a participant speaks different languages, Skype Translator will automatically detect the languages and translate it for you.
Extra! Extra! Read all about it: Stay up-to-date with the latest news and trends.
Hit me up sometime: You can easily add contacts in Skype on mobile using a unique QR code to get connected.
I have a few thoughts on the Today feature and overall updates Skype has been receiving over the past few months but I'll leave those for another post.
Testing WebmentionFs send integration. From Website.
As someone who spends a significant amount of time in the browser, making Edge, more specifically the browser the platform for applications, this looks appealing. Especially when you consider Progressive Web App (PWA) support and integrations with the Windows Store.
Automattic, the current owner of tumblr, one of the biggest meme mines in the world, has said they’re going to implement ActivityPub, which is the underlying protocol on which Mastodon operates. There are boring ways this could go, and then interesting ways this could go.
Interesting points. I'm looking forward to how this shakes out.
https://www.coursera.org/specializations/mathematics-for-machine-learning-and-data-science
Master the Toolkit of AI and Machine Learning. Mathematics for Machine Learning and Data Science is a beginner-friendly specialization where you’ll learn the fundamental mathematics toolkit of machine learning: calculus, linear algebra, statistics, and probability.
https://blog.jim-nielsen.com/2023/best-time-to-own-a-domain/
if own your domain, create value there, and drive people to it, you’re paying ~$10 a year to build unbounded value over the years — value you control.
That is why owning a domain (and publishing your content there) is like planting a tree: it’s value that starts small and grows. The best time to own a domain and publish your content there was 20 years ago. The second best time is today.
I love a technology like
rel=mewhich pushes the idea of domain ownership into broader and broader spheres of society — “How do I get that nice little green checkmark on my profile?” It reinforces the value of owning your own domain (which you can verify elsewhere) and encourages citizens of the internet people to build value in their own little corners of the world wide web.
https://bitwarden.com/blog/bitwarden-open-source-security-explained/
This article answers three common questions about how being open source strengthens Bitwarden security, transparency, and privacy.
http://simonwillison.net/2023/Jan/13/semantic-search-answers/#atom-everything
Here's how to do this:
- Run a text search (or a semantic search, described later) against your documentation to find content that looks like it could be relevant to the user's question.
- Grab extracts of that content and glue them all together into a blob of text.
- Construct a prompt consisting of that text followed by "Given the above content, answer the following question: " and the user's question
- Send the whole thing through the GPT-3 API and see what comes back

https://blog.jim-nielsen.com/2023/subscribe-wherever-you-get-your-content/
Wouldn’t it be amazing if a similar phrase could enter the larger public consciousness for blogs or even people who you follow online?
Instead of:
“Follow me on Twitter.” “I’m @realChuckieCheese on Instagram.” “Subscribe to my videos on YouTube.”You’d hear some popular influencer saying:
“Follow me wherever you follow people online.” “Find me and subscribe wherever you get your content.”
In a world like this, perhaps apex domains could become the currency of online handles: follow me
@jim-nielsen.com.
Now the only challenges for me are:
- Should the song on my website match my ringtone?
- Where do I place the flames GIF?

If you're looking for new folks follow, here's a list of blogs on a variety of topics.
https://www.windowscentral.com/hardware/computers-desktops/intel-core-i3-n-series-launch-ces-2023

The article suggests these processors are for the education market. Hopefully a few of the devices with these processors in a Surface Go form-factor are made generally available as well. I think the N200 series is the sweet spot in terms of performance and battery life with only 6W of max turbo power. The i3 which draws a max of 15W may be too much. At that point, some of the newly announced U-series processors might make more sense.
Great post.
For me, I've found POSSE to Twitter and Mastodon using RSS and IFTTT-like services has been a relatively low-effort thing to do. The downside though is any follow-up conversations take place on those platforms. That hasn't been an issue for me yet though so until it is, I'll continue to use my relatively low-effort solution.
I agree with you on likes / reposts. My current implementation of those posts is focused on Webmentions, which means it's virtually meaningless since few people know about let alone integrate Webmentions into their website. I would argue replies tend to fall into that same space as well. I have however found great use in bookmark posts to which I try and add some content from the source document to help me quickly identfy why I thought that post / website was interesting or relevant to a specific topic at that time.
https://github.com/karpathy/nanoGPT
The simplest, fastest repository for training/finetuning medium-sized GPTs. It's a re-write of minGPT, which I think became too complicated, and which I am hesitant to now touch. Still under active development, currently working to reproduce GPT-2 on OpenWebText dataset. The code itself aims by design to be plain and readable: train.py is a ~300-line boilerplate training loop and model.py a ~300-line GPT model definition, which can optionally load the GPT-2 weights from OpenAI. That's it.
Run 100B+ language models at home, BitTorrent-style. Fine-tuning and inference up to 10x faster than offloading
https://www.theverge.com/23513418/bring-back-personal-blogging
In the beginning, there were blogs, and they were the original social web. We built community. We found our people. We wrote personally. We wrote frequently. We self-policed, and we linked to each other so that newbies could discover new and good blogs.
The biggest reason personal blogs need to make a comeback is a simple one: we should all be in control of our own platforms.
People built entire communities around their favorite blogs, and it was a good thing. You could find your people, build your tribe, and discuss the things your collective found important.
Buy that domain name. Carve your space out on the web. Tell your stories, build your community, and talk to your people. It doesn’t have to be big. It doesn’t have to be fancy. You don’t have to reinvent the wheel. It doesn’t need to duplicate any space that already exists on the web — in fact, it shouldn’t. This is your creation. It’s your expression. It should reflect you.
https://openai.com/blog/new-and-improved-embedding-model/
The new model,
text-embedding-ada-002, replaces five separate models for text search, text similarity, and code search, and outperforms our previous most capable model, Davinci, at most tasks, while being priced 99.8% lower.
https://danielmiessler.com/blog/its-time-to-get-back-into-rss/
We all mourned when Reader died and took RSS with it, but it's time to return to what made it great
Really cool project. Don't really care for the crypto stuff but the rest looks very interesting.
https://matrix.org/blog/2022/12/25/the-matrix-holiday-update-2022
These updates are exciting!
Reddit appears to be building out new Chat functionality using Matrix
Discourse is working on adding Matrix support
Thunderbird launched Matrix support.
Automattic is busy building Matrix plugins for Wordpress
Not as exciting
...only a handful of these initiatives have resulted in funding reaching the core Matrix team. This is directly putting core Matrix development at risk.
In short: folks love the amazing decentralised encrypted comms utopia of Matrix. But organisations also love that they can use it without having to pay anyone to develop or maintain it. This is completely unsustainable, and Element is now literally unable to fund the entirety of the Matrix Foundation on behalf of everyone else - and has had to lay off some of the folks working on the core team as a result.
In the interim, if you are an organisation who’s building on Matrix and you want the project to continue to flourish, please mail funding@matrix.org to discuss how you can support the foundations that you are depending on.
I'm looking forward to the future of the Matrix protocol, especially the P2P components.
https://google.github.io/comprehensive-rust/
This is a four day Rust course developed by the Android team. The course covers the full spectrum of Rust, from basic syntax to advanced topics like generics and error handling. It also includes Android-specific content on the last day.

https://github.com/norvig/pytudes/blob/main/ipynb/AlphaCode.ipynb
Large language models have recently shown an ability to solve a variety of problems. In this notebook we consider programming problems (as solved by AlphaCode) and mathematics problems (as solved by Minerva). The questions we would like to get at are:
- In the future, what role will these generative models play in assisting a programmer or mathematician?
- What will be a workflow that incorporates these models?
- How will other existing tools (such as programming languages) change to accomodate this workflow?
Worked well for me. Thanks for sharing!

Today we're joined by ChatGPT, the latest and coolest large language model developed by OpenAl. In our conversation with ChatGPT, we discuss the background and capabilities of large language models, the potential applications of these models, and some of the technical challenges and open questions in the field. We also explore the role of supervised learning in creating ChatGPT, and the use of PPO in training the model. Finally, we discuss the risks of misuse of large language models, and the best resources for learning more about these models and their applications.
https://github.com/charmbracelet/glow
Render markdown on the CLI
https://github.blog/2022-12-07-github-copilot-is-generally-available-for-businesses/
GitHub Copilot for Business gives organizations:
- The power of AI. Millions of developers have already used GitHub Copilot to build software faster, stay in the flow longer, and solve problems in new ways—all right from their editor of choice.
- Simple license management. Administrators can enable GitHub Copilot for their teams and select which organizations, teams, and developers receive licenses.
- Organization-wide policy management. You can easily set policy controls to enforce user settings for public code matching on behalf of your organization.
- Your code is safe with us. With Copilot for Business, we won’t retain code snippets, store or share your code regardless if the data is from public repositories, private repositories, non-GitHub repositories, or local files.
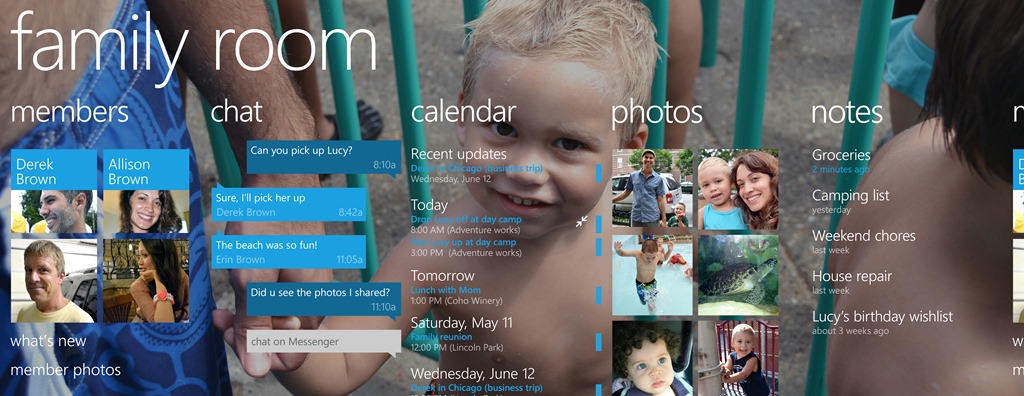
A container-based approach to boot a full Android system on a regular GNU/Linux system like Ubuntu.
https://dev.to/cognipla/geospatial-is-a-function-of-your-life-1924
Florence, a low-code geospatial library for everyone that ranks city places with (life-inspired) functions.
Florence heavily laverages .NET Interactive/Polyglot Notebooks runtime to hide and execute code behind the scene (including breaking some language constraints).
https://www.infoq.com/news/2022/12/microsoft-farmvibes/
Microsoft Research recently open-sourced FarmVibes.AI, a suite of ML models and tools for sustainable agriculture. FarmVibes.AI includes data processing workflows for fusing multiple sets of spatiotemporal and geospatial data, such as weather data and satellite and drone imagery.
https://medium.com/emacs/using-elfeed-to-view-videos-6dfc798e51e6
Slightly modified the original script to use Streamlink and lower quality to 240p for bandwith and resource purposes.
(require 'elfeed)
(defun elfeed-v-mpv (url)
"Watch a video from URL in MPV"
(async-shell-command (format "streamlink -p mpv %s 240p" url)))
(defun elfeed-view-mpv (&optional use-generic-p)
"Youtube-feed link"
(interactive "P")
(let ((entries (elfeed-search-selected)))
(cl-loop for entry in entries
do (elfeed-untag entry 'unread)
when (elfeed-entry-link entry)
do (elfeed-v-mpv it))
(mapc #'elfeed-search-update-entry entries)
(unless (use-region-p) (forward-line))))
(define-key elfeed-search-mode-map (kbd "v") 'elfeed-view-mpv)
https://openai.com/blog/chatgpt/
We’ve trained a model called ChatGPT which interacts in a conversational way. The dialogue format makes it possible for ChatGPT to answer followup questions, admit its mistakes, challenge incorrect premises, and reject inappropriate requests. ChatGPT is a sibling model to InstructGPT, which is trained to follow an instruction in a prompt and provide a detailed response.
https://opensource.com/article/22/11/open-source-payphone-philtel
PhilTel is a telephone collective based in Philadelphia, Pennsylvania, focusing on making communications accessible to everyone by installing free-to-use payphones. While you'll be able to make standard telephone calls through our phones, we're also focusing on offering interesting services or experiences. We don't want to only facilitate human-to-human interaction but also human-to-machine interaction and give people an environment where they can explore the telephone network and learn from it.
https://simonwillison.net/2022/Nov/26/productivity/
Consider timezones: engineers in Madrid and engineers in San Francisco had almost no overlap in their working hours. Good asynchronous communication was essential.
Over time, I noticed that the teams that were most effective at this scale were the teams that had a strong culture of documentation and automated testing.
As I started to work on my own array of smaller personal projects, I found that the same discipline that worked for large teams somehow sped me up, when intuitively I would have expected it to slow me down.
https://stability.ai/blog/stable-diffusion-v2-release
The Stable Diffusion 2.0 release includes robust text-to-image models trained using a brand new text encoder (OpenCLIP), developed by LAION with support from Stability AI, which greatly improves the quality of the generated images compared to earlier V1 releases.
Stable Diffusion 2.0 also includes an Upscaler Diffusion model that enhances the resolution of images by a factor of 4.
https://www.tremendous.com/blog/the-perks-of-a-high-documentation-low-meeting-work-culture
the intangible, overarching benefit of practicing meeting mindfulness is this: you spend less of your day sort-of-listening and more of your day really thinking.
Automattic CEO Matt Mullenweg — whose company acquired Tumblr from Verizon in 2019 — suggested...Tumblr... would soon add ...activitypub.
I'm perfectly happy using my site as the main place to post content but considering it's under new management and adopting open standards, it might be time to checkout out Tumblr again.
In the six weeks since announcing that Internet Archive has begun gathering content for the Digital Library of Amateur Radio and Communications (DLARC), the project has quickly grown to more than 25,000 items, including ham radio newsletters, podcasts, videos, books, and catalogs.
https://derw.substack.com/p/telepathic-technical-writing
...blog posts are always async, but they can lead to conversations and debates, once the reader is done reading. There's also the nature of blog posts being one-to-many, whereas chat is many-to-many, if done in a public channel. One-to-many forms of communication should generally be more formal, but can spread ideas and thoughts more coherently than many-to-many.
https://blog.archive.org/2022/11/15/digital-books-wear-out-faster-than-physical-books/
Our paper books have lasted hundreds of years on our shelves and are still readable. Without active maintenance, we will be lucky if our digital books last a decade.
Feta is a Matrix server distribution for the Raspberry Pi 3 and 4.
This looks like a great project to get started with self-hosting and join the Matrix network. Having something similar for the fediverse would be great as well. I've hosted Matrix and Mastodon servers on a Raspberry Pi before so I know it's up to the task.
https://newsletter.danhon.com/archive/4230/
Here’s how it works in practice:
- A news organization (or any organization, let’s just start with news) already asserts ownership of its domain e.g. via its certificate, so we piggyback trust off its domain.
- It stands up a Mastodon or other social server at a standard address. I’d propose follow.washingtonpost.com but there’s a bunch of reasons why you might do something else, see below, and uses the agreed well-known autodiscovery protocol to return the address for its Mastodon server (but I don’t see an entry for activitypub or Mastodon yet).
- It creates accounts for its staff on its Mastodon server. Nobody else gets an account; the public can’t sign up.
What you get:
- Verified accounts. Instead of relying on a third party to “verify” your account by sticking a blue check against your display name, account provenance and “verification” is inherited as a property of the Mastodon server....
- Ease of discovery...all a user would have to do, to find Washington Post accounts to follow, would be to know the washingtonpost.com domain. Autodiscovery would let your Mastodon client point itself to the appropriate server.
Not just news organizations...anyone can set up a Mastodon server...the federation means that “official” accounts become “more official” when their server home is hung off the domain of the actual organization.
You wouldn’t need Twitter (or anyone else, really) to verify that the UK Prime Minister’s account is official, because you’d have following.gov.uk as the Mastodon server, which means you can trust that server as much as you trust .gov.uk domains.
Your university or college wants you to have a social media account? Sure, you can have it hosted at following.ucla.edu.
And yes, brands can get in on it. Sure. That way there’s a tiny chance you’re following the Proper Brand Account rather than a Parody Brand Account, which… is probably for the best. Or it’s easier to see that a Parody Account is a Parody Account because you can look at the parent server.
https://www.karlsutt.com/articles/communicating-effectively-as-a-developer/
Communicating effectively as an engineer means empathically increasing the resolution of your writing.
...“low-resolution writing”...There is very little context, too much reliance on pronouns and unclear references. The writing is not emphatic —the reader has to spend extra energy to work out what is being said
Longer-form writing gives you an opportunity to dive deeper into why you are saying what you are saying. It is a chance to educate, to teach, to help understand and to level up.
The quality of the API documentation will carry an astronomical amount of leverage. This leverage will work in both directions. Genuinely helpful documentation is the difference between being swamped by support requests from frustrated API users and significantly increasing the usage of your service. Happy users beget more happy users.
Spoken words get forgotten. Written words are shared, preserved, and become the basis of a company's culture. source
High resolution, empathic writing...You will have to spend more energy to make your writing easy to follow. You will have to grapple with your own confusion and holes in your understanding. You will have to figure out what the appropriate density for your writing is.
It's not about you, though.. It's about them.
Not only does a single recipient benefit from your extra effort, what if ten people read your good work? A hundred? A thousand? What if the company CEO reads it? Taking writing seriously at work or in your organisation and putting in the effort to delight the reader will, over time, compound into a massive body of quality writing that benefits everyone. It is a literal win-win-win
Produce writing you would read with delight if you were on the other end.
It's also built with .NET 🙂
https://matthiasott.com/notes/suspension
write your most important thoughts on your own site. You can share the link on as many platforms as you like and have conversations with anyone who wants to connect with you and your work. But nobody can take it from you. You are in control. Forever.
https://pytorch.org/blog/PyTorchfoundation/
PyTorch is moving to the Linux Foundation (LF) as a top-level project under the name PyTorch Foundation.
The PyTorch Technical Governance now supports a hierarchical maintainer structure and clear outlining of processes around day to day work and escalations. This doesn’t change how we run things, but it does add discipline and openness that at our scale feels essential and timely.
https://blog.pocketcasts.com/2022/10/19/pocket-casts-mobile-apps-are-now-open-source/
We’ve been eager to take this step since we joined Automattic last year...
Wow. Yet another company I didn't know was owned by Automaticc (parent company of WordPress). So not only do they have a stake in regular blogs and websites, but they also are in the microblogging space with Tumblr. With Pocket Casts they're now into podcasts too. Good for them.
We believe that podcasting can not and should not be controlled by Apple and Spotify, and instead support a diverse ecosystem of third-party clients.
I couldn't agree more. Though to be fair to Apple, in all the years since podcasts have been a thing, despite them being one of the main indices, they didn't make any overt attempts to lock down the ecosystem. It's not until companies like Amazon and Spotify tried to make certain content platform exclusives that the ecosystem has started to feel more closed.
https://www.fast.ai/posts/part2-2022-preview.html
In total, we’re releasing four videos, with around 5.5 hours of content, covering the following topics (the lesson numbers start at “9”, since this is a continuation of Practical Deep Learning for Coders part 1, which had 8 lessons):
- Lesson 9 by Jeremy Howard: How to use Diffusers pipelines; What are the conceptual parts of Stable Diffusion
- Lesson 9A by Jonathan Whitaker: A deep dive into Stable Diffusion concepts and code
- Lesson 9B by Wasim Lorgat and Tanishq Abraham: The math of diffusion
- Lesson 10 by Jeremy Howard: Creating a custom diffusion pipeline; Starting “from the foundations”
https://twitter.com/andrestaltz/status/1582448952057958401
My experience working on SSB (i.e. non-crypto fully decentralized protocol) is suitable for small world communication, and definitely not suitable for big world. Email proves that federation can do big world.
https://maggieappleton.com/garden-history
The conversational feed design of email inboxes, group chats, and InstaTwitBook is fleeting – they're only concerned with self-assertive immediate thoughts that rush by us in a few moments...But streams only surface the Zeitgeisty ideas of the last 24 hours...Gardens present information in a richly linked landscape that grows slowly over time...The garden helps us move away from time-bound streams and into contextual knowledge spaces.
The Six Patterns of Gardening:
- Topography over Timelines - Gardens are organised around contextual relationships and associative links; the concepts and themes within each note determine how it's connected to others.
- Continuous Growth - Gardens are never finished, they're constantly growing, evolving, and changing.
- Imperfection & Learning in Public - Gardens are imperfect by design. They don't hide their rough edges or claim to be a permanent source of truth.
- Playful, Personal, and Experimental - Gardens are non-homogenous by nature. You can plant the same seeds as your neighbour, but you'll always end up with a different arrangement of plants.
- Intercropping & Content Diversity - Gardens are not just a collection of interlinked words...Podcasts, videos, diagrams, illustrations, interactive web animations, academic papers, tweets, rough sketches, and code snippets should all live and grow in the garden.
- Independent Ownership - Gardening is about claiming a small patch of the web for yourself, one you fully own and control... If you give it a bit of forethought, you can build your garden in a way that makes it easy to transfer and adapt. Platforms and technologies will inevitably change. Using old-school, reliable, and widely used web native formats like HTML/CSS is a safe bet.
https://blueskyweb.org/blog/10-18-2022-the-at-protocol
Bluesky was created to build a social protocol. In the spring, we released “ADX,” the very first iteration of the protocol...ADX is now the “Authenticated Transport Protocol"...more simply, the “AT Protocol.”
The “AT Protocol” is a new federated social network
What makes AT Protocol unique:
- Account portability
- Algorithmic choice
- Interoperation
- Performance
https://herbertlui.net/overdue-insights-on-daily-blogging/
Here are a bunch of not-so-obvious lessons I’ve internalized through writing each day:
- Writing can be a starting point, not an ending one
- Write to think
- The power of DIFY: Do it for yourself, don’t think too much about what you want other people to get out of it.
- Think small
- Gain energy
- A lot of books are collections of blog posts
- Small is an unblocker
https://gist.github.com/luisquintanilla/164176ec414e465246d6323aa62b38df
This sample shows how to use a pretrained Bidirectional Attention Flow (BiDAF) ONNX model in ML.NET for answering a query about a given context paragraph.
https://almanac.httparchive.org/en/2022/
The Web Almanac is a comprehensive report on the state of the web, backed by real data and trusted web experts. The 2022 edition is comprised of 23 chapters spanning aspects of page content, user experience, publishing, and distribution.
Readium LCP was developed five years ago to protect digital files from unauthorized distribution. Unlike proprietary platforms, the technology is open to anyone who wants to look inside the codebase and make improvements. It is a promising alternative for libraries and users wanting to avoid the limitations of traditional DRM.
https://berk.es/2022/10/12/blog-comments-on-a-static-site-via-social-networks/
discu.eu, a fantastic service that you provide with an URL and then gives back results from various social networks. Places where that URL is discussed. Hackernews, Reddit, and/or Lobsters. It has an API, that I can call with some JavaScript and then insert in the page.
https://zenodo.org/record/7070952#.Y0m5eX7MK00
This dataset contains detailed data on 42,207 apartments (242,257 rooms) in 3,093 buildings including their geometries, room typology as well as their visual, acoustical, topological and daylight characteristics.
https://arxiv.org/abs/2210.03945
Large language models (LLMs) have shown exceptional performance on a variety of natural language tasks. Yet, their capabilities for HTML understanding...have not been fully explored. We contribute HTML understanding models (fine-tuned LLMs) and an in-depth analysis of their capabilities under three tasks: (i) Semantic Classification of HTML elements, (ii) Description Generation for HTML inputs, and (iii) Autonomous Web Navigation of HTML pages.
Out of the LLMs we evaluate, we show evidence that T5-based models are ideal due to their bidirectional encoder-decoder architecture.
https://www.kaggle.com/kaggle-survey-2022
Development
Python and SQL remain the two most common programming skills for data scientists
VSCode is now used by over 50% of working data scientists
Notebooks are a popular environment as well.
Colab notebooks are the most popular cloud-based Jupyter notebook environment
Makes sense especially since Kaggle is owned by Google.
Machine Learning
Kaggle DS & ML Survey 2022 Scikit-learn is the most popular ML framework while PyTorch has been growing steadily year-over-year
LightGBM, XGBoost are also among the top frameworks.
Transformer architectures are becoming more popular for deep learning models (both image and text data)
Cloud computing
All major cloud computing providers saw strong year over year growth in 2022
Specialized hardware like Tensor Processing Units (TPUs) is gaining initial traction with Kaggle data scientists
Resources
I got serious about consolidating the media my family consumes; I decided to buy blu-ray and DVD copies of all the movies and TV shows we actually cared about, and rip them onto a NAS.
I'm glad I've gone down this path, and become more intentional about my media consumption, especially as companies are deleting already-purchased content from users' media libraries! It's sickening (and, IMHO, should be illegal) they can show a 'buy' button for a DRM'ed digital downloads that the user never actually 'owns'.
Couldn't agree more. Although the focus of this post is on video, you can say the same for music and books.
http://scripting.com/2022/10/01/133834.html?title=docQuixote
I spent great time, energy and money, over many years to create the writing and programming environment I wanted to use and I wanted my peers to use, so we could work together to create species-saving communication tools, and just beauty...
...I read the story of David Bowie's last days, he did something amazing when he knew he had a short time to live. He stepped back and got out of the way. He understood this is no longer his world.
When you're young, you think expansively, and as you get old reality sinks in and your imagination contracts. The horizon gets closer and closer. We don't get to mold the world, we are not gods, no matter how good or generous, smart of ruthless you may be, we all start out young and if we're lucky we get old and then we're gone.
https://www.stateof.ai/2022-report-launch.html
Key takeaways:
- New independent research labs are rapidly open sourcing the closed source output of major labs.
- Safety is gaining awareness among major AI research entities
- The China-US AI research gap has continued to widen
- AI-driven scientific research continues to lead to breakthroughs
https://stevens.netmeister.org/631/
In this course, students will learn to develop complex system-level software in the C programming language while gaining an intimate understanding of the Unix operating system (and all OS that belong to this family, such as Linux, the BSDs, and even Mac OS X) and its programming environment.
Topics covered will include the user/kernel interface, fundamental concepts of Unix, user authentication, basic and advanced I/O, fileystems, signals, process relationships, and interprocess communication. Fundamental concepts of software development and maintenance on Unix systems (development and debugging tools such as "make" and "gdb") will also be covered.
https://arxiv.org/pdf/2210.00108.pdf
...backdoors can be added during compilation, circumventing any safeguards in the data preparation and model training stages.
some backdoors, such as ImpNet, can only be reliably detected at the stage where they are inserted and removing them anywhere else presents a significant challenge.
machine-learning model security requires assurance of provenance along the entire technical pipeline, including the data, model architecture, compiler, and hardware specification.
A bookmark (or linkblog) is a post that is primarily comprised of a URL, often title text from that URL, sometimes optional text describing, tagging, or quoting from its contents.
Bookmarks are useful for saving things to read later or build a recommended reading list.
Both this post as well as Tom MacWright's "How to Blog" resonate. I've been posting more consistently to my microblog feeds. These posts are more informal, but just the aspect of producing something even if it's just a short snippet is gratifying. The informality of it makes the posts significantly shorter but the pace at which I publish content and share ideas is faster.
https://blog.jim-nielsen.com/2019/i-love-rss/
It's always fun to stumble upon these lists and finding more interesting people and websites to follow.
https://archive.org/details/locations-venues-indie-web-camp-berlin-2022
Interesting discussion at about 21:30 on a federated wiki / review aggregator.
https://blog.jim-nielsen.com/2022/other-peoples-websites/
Google+ was Google trying to mimic the walled garden of Facebook — their “how” of extracting value from the people of the internet. But they already had an answer for Facebook’s News Feed in front of them: Blogger / Google Reader, the read / write of the internet.
They provide the tools – Reader, Blogger, Search — we provide the personal websites. The open, accessible, indexable web as The Next Great Social Network.
I've been doing something similar to readlists, except with RSS feeds. I create a custom recipe in Calibre which pulls and aggregates the 50 latest articles for each feed in my recipe. I limit it to only look at articles published in the past day since I do this every evening. Think of it like the evening paper. The result is an EPUB file which I then import into my e-book reader.
A few advantages I've found to doing this are:
- I take a break from the computer.
- Since the e-book reader is offline, I focus on reading the article and don't have the option to click on links and get distracted browsing the internet.
- Since I'm already using the e-book reader, it's easy to transition to reading a book.
https://stellarium.org/release/2022/10/01/stellarium-1.0.html
Can't believe this is the first time I'd heard of this desktop app. Usually using mobile apps like Sky Guide is convenient when on the go, but Stellarium not only seems to have lots of information, but also cross-platform and web-based.
This ☝️. If you know, you know. 🔥

https://fosdem.org/2023/news/2022-09-14-fosdem-2023-dates/
It feels like the 2022 conference was just yesterday. In any case, save the date February 4-5,2023.
https://opensource.com/article/22/9/joplin-interview
Good read. Other than Emacs, Joplin is my go-to notetaking application.
https://web.dev/testing-web-design-color-contrast/
W3C’s Web Accessibility Initiative provides strategies, standards, and resources to ensure that the internet is accessible for as many people as possible. The guidelines that underpin these standards are called the Web Content Accessibility Guidelines, or WCAG.
Color contrast is an important piece of the puzzle for accessibility on the web, and adhering to it makes the web more usable for the greatest number of people in the most varied situations.
Apps to test contrast:
- Pika
- VisBug
- Chrome Dev Tools
https://ai.googleblog.com/2022/09/tensorstore-for-high-performance.html
High-perf, scalable array storage that can be used for scenarios like language models.
https://opensource.com/article/22/9/git-configuration-linux
- Create global configuration
- Set default name
- Set default email address
- Set default branch name
- Set default editor
https://www.robinsloan.com/notes/home-cooked-app/
When you liberate programming from the requirement to be general and professional and scalable, it becomes a different activity altogether, just as cooking at home is really nothing like cooking in a commercial kitchen.
Same goes for websites and self-hosting.
https://xibbon.com/terminal/2022/09/21/welcome-to-la-terminal.html
I'm not an Apple user, but this is cool.
https://larahogan.me/blog/management-resource-library/
Resource on:
Influence & managing up: Enact positive change for yourself, your team, or the whole organization.
Leading through crises: Strengthen your support network, meet your team where they’re at, and weather the tough times.
Cross-functional relationships: Strengthen relationships by creating role clarity and creatively supporting one another.
One-on-ones: Set your teammates up for success during your one-on-one meetings!
Hiring: Build consistent, repeatable, and equitable interviews and onboarding plans.
Meetings: Support participants, hone the content, and nail the meeting goal.
Feedback & performance reviews: Everyone deserves clear, actionable feedback!
Communication & team dynamics: Plan ahead, facilitate well, and create clarity.
Adapting your approach: As your work context and team evolves, your leadership approach will need to evolve, too.
https://weaviate.io/blog/2022/09/Distance-Metrics-in-Vector-Search.html
Metrics covered:
- Cosine
- Dot Product
- L2-Squared
- Manhattan
- Hamming
https://en.wikipedia.org/wiki/1%25_rule
...about 1% of Internet users create content, while 99% are just consumers of that content
http://paulgraham.com/users.html
What have I learned from YC's users, the startups we've funded?
...most startups have the same problems.
...the batch that broke YC was a powerful demonstration of how individualized the process of advising startups has to be.
...founders can be [bad] at realizing what their problems are. Founders will sometimes come in to talk about some problem, and we'll discover another much bigger one in the course of the conversation.
Often founders know what their problems are, but not their relative importance.
Focus is doubly important for early stage startups, because not only do they have a hundred different problems, they don't have anyone to work on them except the founders. If the founders focus on things that don't matter, there's no one focusing on the things that do.
Speed defines startups. Focus enables speed. YC improves focus.
Why are founders uncertain about what to do? Partly because startups almost by definition are doing something new, which means no one knows how to do it yet, or in most cases even what "it" is.
disgruntled Facebook users keep using the service because they don’t want to leave behind their friends, family, communities and customers.
“How to Ditch Facebook Without Losing Your Friends” explains the rationale behind these proposals - and offers a tour of what it would be like to use a federated, interoperable Facebook, from setting up your account to protecting your privacy and taking control of your own community’s moderation policies, overriding the limits and permissions that Facebook has unilaterally imposed on its users.
This tool will help you to create a Firefox profile with the defaults you like.
You select which features you want to enable and disable and in the end you get a download link for a zip-file with your profile template.
20 years and still going strong.
This is my comment 2
https://www.zylstra.org/blog/2022/09/wordpressindieweb-as-the-os-of-the-open-social-web/
...2022 Netherlands WordCamp edition in Arnhem [presentation] on turning all WordPress sites into fully IndieWeb enabled sites. Meaning turning well over a third of the web into the open social web. Outside all the silos.
http://www.paulgraham.com/chameleon.html
When Lisp adopts a new paradigm it not only replicates existing practice, but goes beyond it to become a testbed for advancing the state of the art. Why has Lisp been able to adapt so easily when other languages have not? One reason is that Lisp is a programmable programming language.
https://www.freecodecamp.org/news/new-online-courses/
Subjects:
- Science
- Programming
- Education & Teaching
- Health & Medicine
- Social Sciences
- Business
- Information Security (InfoSec)
- Mathematics
- Computer Science
- Data Science
- Personal Development
- Humanities
- Engineering
- Art & Design
https://www.openbuildinginstitute.org/
The OBI system is open source, collaborative and distributed.
Our focus is on low cost and rapidly-built structures that are modular, ecological, and energy efficient.
https://ideaspace.substack.com/p/metablogging
...internally public blogs written by members of the...squad detailing what they’re working on and thinking about.
https://aeturrell.github.io/coding-for-economists/intro.html
...a guide for economists on what programming is, why it’s useful, and how to do it.
https://github.com/google/haskell-trainings
This repository contains the source for the slides and the exercises used in the Haskell trainings at Google.
https://www.opensourcealternative.to/
Discover 350+ popular open source alternatives to your proprietary SaaS.
Open Library is an initiative of the Internet Archive, a 501(c)(3) non-profit, building a digital library of Internet sites and other cultural artifacts in digital form.
Find feeds for all of your favorite sites and keep up with everything they post!
https://evernote.com/blog/how-to-create-commonplace-with-evernote/
Why commonplace?
Commonplace is an ideal medium for the curation and cultivation of intellectual ideas, thoughts, and knowledge. It’s also a proven and timeless system, tested by folks from a spectrum of backgrounds including authors, professors, and scientists.
- Remember things
- Write to recall
- Understand reading
- Personal reference system
- Filter ideas
- Unleash creativity
Reflecting on your commonplace
The most profound power of your commonplace is being able to thumb through reading and review material. Your commonplace book isn’t just a filing cabinet—it’s an evolving record of your life and observations.
https://www.jayeless.net/wiki/small-web.html
...the kind of web they define themselves against; that kind of bloated, corporate, algorithm-ruled and ad-ridden mess that constitutes the majority of highly-trafficked websites these day.
...for me, the term “Small Web” refers to a couple of main things: independence from tech giants, and websites that are lightweight and high-performance.
Related concepts:
- A late 90s-style, hand-crafted web
- Alternative protocols, like Gemini
- An independent web
This site is dedicated to a community (and a larger movement) about the internet how it's changed. We are creating, discovering and enjoying websites and digital spaces.
https://knightcolumbia.org/events/reimagine-the-internet
A virtual conference exploring what the internet could become over the next decade
Sessions:
- Pioneering Alternative Models for Community on the Internet
- Misinformation, Disinformation, and Media Literacy in a Less-Centralized Social Media Universe
- Interoperability and Alternative Social Media
- Lessons from Experiments in Local Community-Building
- Deplatforming and Innovation
- New Directions in Social Media Research
...masterWiki is the direct adaptation of MasterClass' video courses translated into wikiHow-style how-to guides...
Here’s how to read the post:
- Level 1 — Casual. Read the headlines — figure out the details yourself. Most of this isn’t rocket science.
- Level 2 — Tutorial. Read the steps underneath the headline. I’ve spelled out every step so that you can save your brain power for something else.
- Level 3 — Productivity Nerd. Below the tutorial steps, I’ve included discussion of the behavior design implications. This is for true productivity nerds, i.e. the readers of Better Humans.
Optimize First for Single Tasking
#1. Turn OFF (almost) all notifications
#2. Hide social media slot machines
#3. Hide messaging slot machines
#4. Disable app review requests
#5. Turn on Do Not Disturb
#6. Be strategic about your wallpaper
#7. Turn off Raise to Wake
#8. Add the Screen Time widget
#9. Add Content Restrictions
#10. (Optional) Use Restrictions to turn off Safari
#11. Organize your Apps and Folders alphabetically
Switch to Google Cloud to Work Faster
#12. Choose GMail
#13. Choose Google Calendar
#14. Replace Apple Maps with Google Maps
#15. Install the GBoard keyboard for faster typing
#16. Switch to Google Photos
Install These Apps for Productivity
#17. Use Evernote for all note taking, to-do lists, everything
#18. The Case for Calm as your go-to meditation app
#19. Install the right goal tracker for you
#20. Store all your passwords in a password manager, probably LastPass
#21. Use Numerical as your default calculator
#22. Put the Camera app in your toolbar
#23. Use this Doppler Radar app
#24. Use this Pomodoro app
#25. Use Brain.fm for background noise
Use These Apps and Configurations for Deep Learning
#26. Subscribe to these podcasts
#27. Install the Kindle app but never read it in bed
#28. Use Safari this way
#29. Organize your home screen for deep learning over shallow learning
Use These Apps and Configurations for Longevity
#30. Track steps this way
#31. Prefer Time Restricted Eating Over Calorie Counting
#32. Schedule Night Shift
#33. Set up Medical ID
Make The Finishing Touches with These Configurations
#34. Change Siri to a man
#35. Change your phone’s name
#36. Turn off advertising tracking
#37. Set auto-lock to the maximum time
#38. Set your personal hotspot password to a random three word phrase
#39. Turn on control center everywhere
#40. Turn on Background App Refresh
#41. Delete Garage Band
#42. Develop verbal memory for talking to Siri
#43. Set up these text replacement shortcuts
#44. Set your address
#45. Backup this way
https://klemet.github.io/Workshop-Organization-EN/index.html
Workshop objectives
- Discover and learn to use the basic functions of the following software:
- Joplin
- Zotero
- Nextcloud
- Learn how to use these different software programs together to manage information using the following methods:
- The Zettelkasten method
- The P.A.R.A method
- The inbox method
https://www.fast.ai/2022/07/21/dl-coders-22/
A free course designed for people with some coding experience, who want to learn how to apply deep learning and machine learning to practical problems.
Lessons
- Getting started
- Deployment
- Neural net foundations
- Natural Language (NLP)
- From-scratch Model
- Random forests
- Collaborative filtering and embeddings
- Convolutions (CNNs)